
Résumés
Résumé
Cet article présente des solutions n’exigeant aucun calcul des problèmes de Fermat, de Weber et d’attraction-répulsion. Il met en évidence la proche parenté de l’approche topodynamique et de la nouvelle économie géographique tout en faisant ressortir les différences qui existent entre les concepts de forces d’attraction et de répulsion du problème d’attraction-répulsion et ceux de forces d’agglomération et de dispersion qui en découlent en nouvelle économie géographique. Enfin, il explore la possibilité de faire converger les approches de l’analyse topodynamique et de la nouvelle économie géographique.
Mots-clés:
- Problème d’attraction-répulsion,
- problème de Fermat,
- problème de Weber,
- modèle topodynamique,
- nouvelle économie géographique
Abstract
This paper presents non-numerical solutions to the Fermat, Weber and attraction-repulsion problems. It stresses the close relationship between the topodynamic approach and the New Economic Geography while pointing out the differences between the concepts of attractive and repulsive forces associated with the attraction-repulsion problem and those of agglomeration and repulsion forces of the New Economic Geography. Finally, it explores whether and to what extent the topodynamic and New Economic Geography approaches will converge.
Keywords:
- Attraction-repulsion problem,
- Fermat problem,
- Weber problem,
- topodynamic model,
- New Economic Geography
Corps de l’article
En 1985, dans mon livre intitulé Économie spatiale : rationalité économique de l’espace habité, il m’a été donné de formuler pour la toute première fois le problème d’attraction-répulsion et de le solutionner dans sa forme triangulaire à l’aide de la trigonométrie. Cette solution est directement inspirée de ma solution trigonométrique du problème de Weber publiée en 1972. En 1992, Chen et al. ont solutionné la forme plus générale du problème d’attraction-répulsion à l’aide d’un algorithme mathématique. Il se trouve que, depuis, sous le nom de nouvelle économie géographique, un corpus considérable s’est développé qui découle directement des concepts du problème d’attraction-répulsion. La meilleure synthèse récente de ce corpus est fournie par Combes et al. (2006).
Le présent article rappelle qu’il existe une solution facile du problème du triangle de Weber et du problème d’attraction-répulsion dans sa forme triangulaire. Cette solution, qu’aucun texte (livre ou article) ne présente à notre connaissance, permet à chacun de trouver la solution de ces deux problèmes sans le moindre calcul et sans autre instrument qu’un simple compas et du papier transparent. Elle a l’avantage de familiariser ceux que la trigonométrie et les mathématiques en général rebutent avec ces problèmes théoriques en faisant directement appel à leur intuition et à leur sens élémentaire de la géométrie. Cette solution présentée, nous nous attarderons à souligner les nuances qui distinguent les concepts de forces d’attraction et de répulsion du problème d’attraction-répulsion de ceux de forces d’agglomération et de dispersion qui en découlent en nouvelle économie géographique. Nous ferons alors allusion aux principaux modèles de ce courant scientifique avant de déboucher sur le modèle topodynamique qui diffère profondément des modèles de la nouvelle économie géographique tout en découlant comme eux du problème d’attraction-répulsion Ottaviano et Thisse (2005).
La solution facile du problème de Fermat
Le problème du triangle de Weber est une généralisation du problème de Fermat qui consiste à trouver la localisation d’un quatrième point qui minimise la distance totale séparant ce quatrième point de trois points prédéterminés A, B et C. Ce problème formulé par Pierre de Fermat en 1640 a été solutionné par Evangelista Torricelli en 1647. Le problème de Fermat revient à trouver le point d’équilibre d’un système de trois forces égales orientées vers les trois points de référence qui constituent, dans les faits, des points d’attraction. L’objectif de minimisation se rapprochant quand la distance du quatrième point à chacun des trois points diminue, on conçoit que le quatrième point est attiré par chacun des trois points de référence, ce qui fait de ces derniers des points d’attraction exerçant des forces d’attraction égales (se rapprocher d’un kilomètre du point A est équivalent à se rapprocher d’un kilomètre du point B ou du point C).
Dans un cas semblable, pour s’annuler, les trois forces d’attraction w égales devront être séparées par des angles α de 120 degrés (soit 360 degrés divisés par 3). Pour obtenir ces angles, il suffit de tracer avec une règle et un compas deux triangles équilatéraux dos à dos, comme sur la figure 1, et de prolonger le côté Oa’ commun aux deux triangles. Reste à superposer les vecteurs obtenus sur la carte géographique où se trouvent les points A, B et C de façon à ce que chaque vecteur soit orienté vers l’un des trois points de référence A, B et C (figures 2 et 3). Le point optimal O se trouve au point d’origine des trois vecteurs.
Figure 1
Traçage des angles de 120 degrés (problème de Fermat)

Figure 2
Superposition des vecteurs et de la carte géographique

Figure 3
Détermination du point optimal O (problème de Fermat)
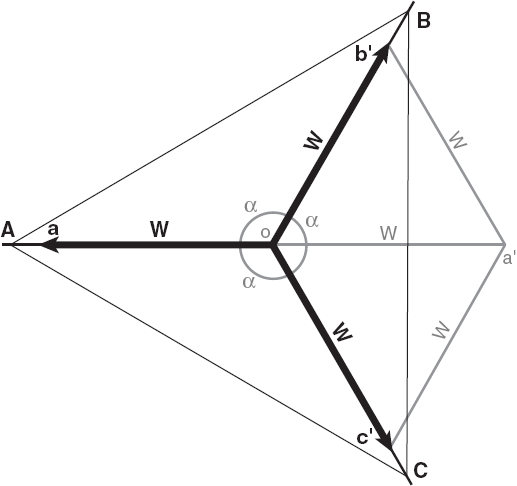
La solution facile du problème de Weber
Le problème de Weber est plus complexe. Il consiste à minimiser le coût total de transport d’une activité O à localiser par rapport à trois points d’attraction A, B et C. Le coût total de transport est égal à la somme des coûts de transport calculés par rapport à chacun des trois points d’attraction. Le coût de transport calculé par rapport au point A, par exemple, est égal à la distance au point A multipliée par la quantité transportée et le taux de transport correspondants. La force d’attraction wA du même point A est alors égale à la quantité transportée entre A et O multipliée par le taux de transport correspondant. Dans un tel cas, les forces d’attraction wA, wB et wC exercées par les points A, B et C ne sont normalement pas égales entre elles.
La première solution au problème du triangle de Weber est due à Georg Pick et se trouve en annexe du livre d’Alfred Weber (1909). Par la suite, Kuhn et Kuenne (1962) ont trouvé une solution algorithmique au cas du triangle et au cas général du problème de Weber. Enfin, ce n’est qu’en 1972, que j’ai trouvé la première solution numérique déterministe du problème du triangle de Weber. Cette solution est trigonométrique (Tellier, 1972).
La solution facile du problème du triangle de Weber consiste à tracer dos à dos deux triangles identiques Ob’a’ et c’Oa’ dont les côtés sont proportionnels aux forces d’attraction wA, wB et wC exercées respectivement par les points A, B et C, et à prolonger le côté Oa’ commun aux deux triangles pour obtenir les angles αA, αB et αC séparant les vecteurs wA, wB et wC orientés respectivement vers A, B et C, ces vecteurs correspondant aux trois forces d’attraction (figure 4).
Cette méthode se justifie de la façon suivante. Nous savons que la localisation optimale du point O est caractérisée par le fait que les forces d’attraction s’annulent. Par conséquent, à l’optimum, les trois forces sont disposées de telle manière que la résultante des forces wB et wC, obtenue par la méthode de composition de force à l’aide de parallélogrammes, annule la force wA, comme sur la figure 5. Il est facile de voir que les deux triangles ayant comme base commune la résultante ont des côtés égaux à chacune des trois forces du système. La solution facile consiste uniquement à tracer ces deux triangles ayant un côté en commun (soit la résultante) pour obtenir, en prolongeant la résultante, les angles αA, αB et αC assurant l’équilibre.
Figure 4
Traçage des angles permettant d’annuler les forces (problème de Weber)

Figure 5
Superposition des vecteurs et de la carte géographique

Reste à superposer les vecteurs obtenus sur la carte géographique où se trouvent les points A, B et C de façon à ce que chaque vecteur soit orienté vers le point d’attraction approprié (figures 5 et 6). Il est essentiel de respecter l’ordre des lettres : si les points se sont vus attribuer les lettres A, B et C dans le sens des aiguilles d’une montre, les côtés des deux triangles de forces doivent suivre l’ordre des aiguilles d’une montre et les vecteurs doivent être orientés vers les points d’attraction appropriés. Le point optimal O se trouve au point d’origine des trois vecteurs.
Figure 6
Détermination du point optimal O (problème de Weber)

La solution facile du problème d’attraction-répulsion
Un point d’attraction est un point qui est tel qu’en en rapprochant l’activité à localiser, nous nous rapprochons de l’objectif recherché (la maximisation du profit, la minimisation des coûts de transport, la maximisation de la satisfaction ou la maximisation du bien-être collectif, selon le cas). Inversement, un point de répulsion est un point qui est tel qu’en en éloignant l’activité à localiser, nous nous rapprochons de l’objectif recherché.
Le cas triangulaire du problème d’attraction-répulsion implique deux points d’attraction et un point de répulsion (le cas de deux points de répulsion et d’un point d’attraction donne lieu à une localisation au point d’attraction si la force d’attraction est plus grande que la somme des deux forces de répulsion ou à une localisation à l’infini dans le cas contraire). La solution facile du problème d’attraction-répulsion est aussi simple que la solution facile du problème de Weber.
Elle consiste uniquement à tracer dos à dos deux triangles Ob’r’ et a’Or’ identiques dont les côtés sont proportionnels aux forces exercées respectivement par les points d’attraction A et B, et par le point de répulsion R. Il est essentiel que le côté Or’ commun aux deux triangles soit celui qui correspond à la force de répulsion wR. De même, il est essentiel d’inverser l’ordre des lettres : si les points se sont vus attribuer les lettres A, B et R dans le sens des aiguilles d’une montre, les côtés des deux triangles de forces doivent suivre le sens inverse des aiguilles d’une montre et les vecteurs doivent être orientés vers les points de référence appropriés.
Les figures 7, 8 et 9 illustrent la méthode. Il est important de noter que deux optima peuvent être trouvés. L’un, illustré à la figure 9, est tel que le point de répulsion R et l’optimum O se trouvent de part et d’autre de la droite AB. Un autre optimum local peut parfois (mais pas toujours) être trouvé de l’autre côté de la droite AB à la condition que le point O se retrouve plus loin de AB que ne l’est le point R. Dans ce cas, cet optimum partiel est sous-optimal par rapport à l’optimum trouvé de l’autre côté de la droite AB.
Figure 7
Traçage des angles permettant d’annuler les forces (problème d’attraction-répulsion)
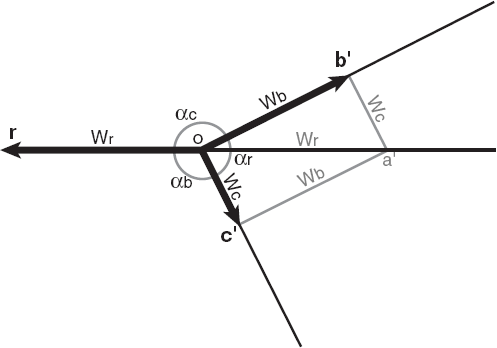
Figure 8
Superposition des vecteurs et de la carte géographique

Figure 9
Détermination du point optimal O (problème d’attraction-répulsion)

Le problème d’attraction-répulsion et la nouvelle économie géographique
En formulant le problème d’attraction-répulsion en 1985, j’étais loin de soupçonner son importance. Petit à petit, moi-même et plusieurs autres économistes spatiaux nous sommes rendus compte que le concept de force de répulsion était essentiel pour comprendre la théorie de la rente foncière, la théorie de la location et la théorie des systèmes urbains. De mon côté, ce concept m’a permis d’élaborer à la fois la théorie topodynamique (Tellier, 1995 et 2005) et le modèle topodynamique (Tellier, 2002). Chez d’autres, le problème d’attraction-répulsion a donné naissance à la nouvelle économie géographique élaborée par certains des plus prestigieux économistes- mathématiciens au monde.
Combes et al. (2006 : 4) écrivent dans l’avant-propos de leur livre : « il n’est pas inutile de rappeler qu’économistes et géographes considèrent l’espace économique comme le produit d’un système de forces, certaines poussant vers l’agglomération des activités humaines – les forces centripètes –, les autres vers leur dispersion – les forces centrifuges ». Alfred Weber fut le premier à développer une telle approche en développant le concept de force d’attraction. Avec la formulation du problème d’attraction-répulsion, le pendant des forces d’attraction, les forces de répulsion, ont fait leur entrée dans la théorie économique spatiale. Se sont ajoutés au cours des dernières années, dans le cadre de la nouvelle économie géographique, les concepts de forces d’agglomération et de dispersion qu’il est prudent de continuer à distinguer, malgré leur proche parenté, des concepts de forces d’attraction et de répulsion. Nous verrons pourquoi.
Les modèles de la nouvelle économie géographique sont des modèles d’équilibre [1] général à vocation mésoéconomique (on y traite de régions en faisant abstraction des gouvernements nationaux) basés sur la microéconomie et supposant une concurrence imparfaite et l’existence d’une préférence des consommateurs pour la variété et de rendements d’échelle croissants. La nouvelle économie géographique se distingue du modèle néoclassique traditionnel qui, lui, suppose une concurrence parfaite et des rendements d’échelle constants. Le principal objectif de la nouvelle économie géographique est l’étude de la polarisation des activités économiques et des disparités économiques macrospatiales.
Paul Krugman peut être considéré comme l’initiateur de la nouvelle économie géographique. Il est l’auteur ou le co-auteur de trois des quatre plus importants modèles de la nouvelle économie géographique. Ces quatre modèles sont le modèle de Krugman, le modèle de Krugman et Venables, le modèle de Krugman et Livas, et le modèle de Fujita et Thisse.
Le modèle de Krugman (1991) comporte deux régions, deux secteurs (agricole et industriel), deux groupes de firmes (les firmes agricoles confinées à leur région et les firmes industrielles pouvant passer d’une région à l’autre) et deux groupes de travailleurs (les qualifiés travaillant dans le secteur industriel et pouvant migrer d’une région à l’autre, et les non-qualifiés travaillant dans le secteur agricole et confinés à leur région d’origine). Ce modèle donne naissance à des effets cumulatifs favorisant l’une des deux régions et donnant lieu à un schéma centre-périphérie. La croissance de la région centrale y est vue comme bénéficiant de forces d’attraction qualifiées de forces d’agglomération, la survie de la région périphérique dépendant des forces de répulsion qualifiées de forces de dispersion liées au fait que les firmes agricoles et les travailleurs non qualifiés n’ont pas la possibilité de migrer. Les forces d’agglomération sont vues comme des forces centripètes alimentées par la migration des travailleurs qualifiés, les rendements d’échelle croissants et les effets de croissance du marché local (home market effects), tandis que les forces de dispersion sont perçues comme des forces centrifuges liées à l’immobilité des travailleurs agricoles et à la congestion progressive de la région centrale.
Le modèle de Krugman et Venables (1995) modifie le modèle de Krugman, d’une part, en excluant la possibilité pour les travailleurs qualifiés de migrer dans l’autre région et, d’autre part, en permettant aux firmes d’utiliser des biens intermédiaires (ce qu’excluait le modèle de Krugman). Ces modifications ont des effets radicaux sur l’évolution dynamique du modèle en termes d’agglomération et de dispersion. Alors que le modèle de Krugman donnait naissance à un déséquilibre interrégional croissant, la région centrale attirant de plus en plus de firmes et de travailleurs qualifiés, le modèle de Krugman et Venables fait apparaître une courbe en cloche. Cette courbe permet de distinguer deux phases : une première phase, dite de divergence, au cours de laquelle la région gagnante, qui attire de plus en plus de firmes, domine de plus en plus la région perdante et une seconde phase, dite de convergence, où la région gagnante se sature et se congestionne, ce qui conduit les firmes à la déserter au profit de la région antérieurement perdante.
Le modèle de Krugman et Livas (1996) va encore plus loin dans l’étude de la courbe en cloche en introduisant dans le modèle de Krugman des forces de répulsion liées aux coûts urbains, c’est-à-dire aux prix fonciers et aux coûts de transport découlant des mouvements pendulaires (entre les lieux de résidence et les lieux de travail). Évidemment, l’introduction de ces coûts dans le modèle a pour effet de consolider les bases théoriques de la courbe en cloche. Ottaviano, Tabuchi et Thisse (2002) ont encore approfondi l’étude du rôle des coûts urbains dans la nouvelle économie géographique. Évidemment, la prise en compte des prix fonciers a conduit à faire appel au modèle d’utilisation du sol de von Thünen (1826) qui est à l’origine même de l’économie spatiale.
Enfin, le modèle de Fujita et Thisse (2002) complète le mariage entre la microéconomie moderne, les modèles d’équilibre général et l’économie spatiale classique en introduisant dans le modèle hérité de Krugman à la fois la modélisation de la concurrence spatiale héritée de Hotelling et la modélisation de l’utilisation du sol héritée de von Thünen. Dans ce modèle plus général devenu un classique, on retrouve la fameuse courbe en cloche, mais dans un contexte beaucoup plus complexe que celui imaginé au départ par Krugman. En effet, le modèle de Fujita et Thisse se prête à une analyse des phénomènes d’agglomération à plusieurs échelles spatiales différentes et non plus seulement au niveau de deux régions englobantes.
Les modèles de Krugman, de Krugman et Venables et de Krugman et Livas font apparaître des forces d’agglomération et de dispersion au niveau des régions. Ces forces sont définies par rapport à des espaces bi-dimensionnels (des surfaces, c’est-à-dire les régions elles-mêmes) et non par rapport à des points précis de l’espace. Ce sont ce que nous appellerions des macroforces résultant du jeu à la fois des économies d’agglomération et d’un ensemble de microforces (celles qui s’exercent sur chacune des entreprises et chacun des travailleurs). Or le problème d’attraction-répulsion traite avant tout des microforces puisqu’il est défini par rapport à des points et non pas des surfaces, et qu’il ignore généralement les économies d’agglomération. Il est important de toujours garder cela en tête comme nous l’avons fait remarquer ailleurs (Tellier, 2004).
Ces distinctions sont importantes parce qu’il a été démontré que, s’il est vrai que les points d’attraction ont de fortes chances de s’imposer comme localisations optimales pour un grand nombre d’activités, il n’est pas impossible qu’un système ne comprenant que des forces d’attraction donne lieu à une dispersion des activités. En effet, une suite de milliers de problèmes d’attraction-répulsion successifs donne un éparpillement presque [2] aléatoire des localisations optimales si ces problèmes ne sont pas interdépendants (c’est-à-dire si les points d’attraction sont choisis tout à fait au hasard sans que les localisations optimales des problèmes antérieurs aient plus de chances que les autres points d’être choisis comme points d’attraction dans le choix des localisations subséquentes) (Tellier et al., 1984).
Par ailleurs, il est vrai qu’en tant que tels, les points de répulsion ne sauraient s’imposer comme localisation optimale pour une quelconque activité, du moins si ces points de répulsion ne sont pas en même temps des points d’attraction, ce qui n’est nullement impossible. Par exemple, un centre-ville peut être vu à la fois comme un point d’attraction et un point de répulsion. Cela dit, l’introduction de points de répulsion dans un système ne se traduit pas forcément par une baisse du niveau de polarisation et d’agglomération (Tellier et Polanski, 1989). En effet, l’introduction de points de répulsion dans le système a plus d’effet sur la répartition spatiale de la polarisation que sur le niveau de polarisation même. Plus il y a de points de répulsion dans le système, plus la polarisation se fait au bénéfice de la périphérie de l’espace considéré, alors que, s’il n’y a que des points d’attraction, la polarisation se fait au bénéfice du centre de l’espace considéré (Tellier et al., 1984). En somme, en présence de points de répulsion, un phénomène d’agglomération dispersée ou d’agglomération-dispersion est tout à fait possible, ce que ne laisse pas entrevoir la dichotomie agglomération-dispersion si on ne le précise pas.
En se prêtant à une analyse des phénomènes d’agglomération à plusieurs échelles spatiales différentes, le modèle de Fujita et Thisse ouvre la voie à un mariage en séparation de concepts des notions de force d’attraction, de force de répulsion, de force d’agglomération et de force de dispersion. Il s’agit là d’un développement théorique significatif. Une autre possibilité de faire converger les deux approches passe par la réconciliation des modèles de la nouvelle économie géographique et du modèle topodynamique.
Originalité du modèle topodynamique
Alors que les modèles de la nouvelle économie géographique ont une forme économétrique, le modèle topodynamique découlant lui aussi du problème d’attraction-répulsion est tout à fait atypique. Ce modèle mathématique ne recourt à aucun outil de l’économétrie (régressions, tests statistiques, variables instrumentales, etc.) et pourtant il permet de produire des projections de population et de production plus vraisemblables et cohérentes s’étendant sur une période de temps plus longue que l’immense majorité, sinon la totalité, des modèles économétriques traditionnels. Les seuls modèles classiques qui s’en rapprochent sont les simulations de type Monte Carlo.
Le modèle topodynamique découle directement des simulations théoriques faites sur ordinateur par Tellier, Ceccaldi et Tessier (1984) et par Tellier et Polanski (1989) à partir du problème d’attraction-répulsion. Lors de ces simulations, il a été observé qu’en générant des milliers de problèmes d’attraction-répulsion triangulaires définis au hasard, la distribution spatiale des localisations optimales calculées variait systématiquement selon un certain nombre de paramètres, tels que :
i, |
l’indice d’interdépendance des problèmes de localisation successifs (i est la probabilité qu’un des points de référence par rapport auxquels un nouveau problème de localisation est défini, soit choisi parmi les solutions optimales des problèmes antérieurs) ; |
a, |
la proportion de forces d’attraction dans le système, par opposition aux forces de répulsion ; |
r, |
l’ampleur relative des forces de répulsion par rapport aux forces d’attraction (la valeur des forces de répulsion est choisie aléatoirement entre 0 et r, où r est une valeur entre 0 et 1, tandis que celle des forces d’attraction est choisie aléatoirement entre 0 et 1) ; |
m, |
la probabilité qu’une activité existant au temps t disparaisse au temps t+x (cette probabilité est décrite comme un indice de mortalité, ce qui peut correspondre à la fermeture d’une entreprise, par exemple, mais aussi à son simple déménagement ; on considère alors que l’activité meure à son site actuel pour renaître à son nouveau site). |
Il a été observé que :
plus le niveau d’interdépendance est élevé, plus le niveau de polarisation est élevé ;
plus la proportion de points d’attraction est élevée, plus la polarisation se fait dans la zone centrale de l’espace borné considéré et plus la proportion de points de répulsion est élevée, plus la polarisation se fait en périphérie de l’espace borné considéré ;
plus l’ampleur des forces de répulsion est importante comparée à celle des forces d’attraction, plus l’effet explosif des forces de répulsion est prononcé ;
plus la probabilité qu’une activité localisée à une localisation optimale meure, plus la distribution spatiale des localisations optimales évolue rapidement.
Le modèle topodynamique part de ces constatations et les utilise pour produire des projections de population, de production ou de production par habitant. Il pourrait aussi être utilisé pour étudier l’évolution spatiale de tout phénomène socioéconomique dont il est raisonnable de croire qu’il a une logique spatiale. Le concept de base est de trouver les valeurs des quatre paramètres énoncé plus haut qui permettent de reproduire aussi fidèlement que possible l’évolution d’une distribution spatiale (de population, de production ou d’autre chose) entre une année t et une année t+x. Quand cela est fait, il s’agit de calculer des correctifs tenant compte des particularités locales. Cela fait, l’ordre est donné à l’ordinateur de partir de la distribution observée à l’année t+x et de poursuivre la simulation, à l’intérieur des paramètres définis en prenant en compte les correctifs, jusqu’aux horizons que l’on choisit.
L’analyse topodynamique comporte plusieurs étapes successives que nous ne décrirons pas ici en détail. Nous renvoyons le lecteur, sur ce point, à Tellier (1992a, 1992b et 1995). Ses deux grandes étapes sont :
l’estimation des valeurs optimales des paramètres clés du modèle qui permettent de reproduire aussi exactement que possible une évolution observée entre deux dates, par exemple, entre 1981 et 2001 ;
la production de projections en simulant l’évolution de la répartition spatiale des populations ou des productions à l’aide du modèle, défini par les valeurs optimales des paramètres, appliquée à la distribution spatiale des populations ou des productions observée en l’an 2001.
Chaque combinaison de valeurs différentes des paramètres i, a, r et m correspond à un scénario particulier. Afin de déterminer les valeurs optimales de i, a, r et m qui permettent de reproduire une évolution observée, une soixantaine de scénarios sont simulés sur ordinateur à partir du schéma spatial de départ (celui de 1981) dans le but de déterminer lequel donne les résultats les plus semblables à ceux du schéma spatial final observé en 2001.
Comparer mathématiquement deux distributions spatiales est loin d’être aussi simple que certains pourraient le croire. Traditionnellement, le modèle topodynamique a eu recours à onze indices descriptifs (définis mathématiquement dans Tellier, 1992b). Il s’agit d’un indice ponctuel :
EQ, l’écart quadratique entre les valeurs simulées et les valeurs observées en chacun des points de la distribution ;
de quatre indices de concentration-éparpillement, soit les indices :
B, la moyenne des distances au centre de gravité ;
C, un indice de concentration ;
E, un indice d’éparpillement ;
Y, un indice de déconcentration par rapport au centre géométrique ;
de quatre indices définis par rapport au centre de gravité, soit les indices :
F, la distance standardisée entre le centre de gravité et le centre géométrique ;
H, la distance en kilomètres entre le centre de gravité et le centre de gravité observé en 2000 ;
x, la coordonnée x du centre de gravité et
y, la coordonnée y du centre de gravité ;
et de deux indices de domination des subdivisions les plus peuplées :
L, le paramètre de la relation rang-taille ;
T, un indice d’éloignement du centre urbain principal.
En plus de ces onze indices, le modèle topodynamique a recours aux ellipses de dispersion pour comparer l’évolution des schémas de localisation. Les ellipses de dispersion sont un outil particulièrement précieux pour porter un jugement sur la cohérence des projections, comparées aux évolutions observées jusqu’ici. Les deux axes d’une ellipse de dispersion sont perpendiculaires et leurs longueurs respectives sont calculées de la même manière que les composantes principales en analyse multivariée. Dans le contexte du modèle topodynamique, l’accent est mis sur les évolutions observées et projetées des ellipses de dispersion. Il s’agit de vérifier si le mouvement projeté des ellipses s’inscrit tout à fait dans le prolongement de leur mouvement observé.
L’un des grands défis de l’approche topodynamique a été de partir de cette série d’indices (série qui aurait pu être encore plus considérable) pour arriver à définir un seul et unique indice synthétique à optimiser. Après analyse, il est apparu que les valeurs optimales des paramètres clés doivent idéalement répondre à trois critères mathématiquement différents, à savoir qu’elles doivent permettre de reproduire sur ordinateur l’évolution observée de telle façon :
que soient minimisés les écarts quadratiques entre les populations observées et prédites de chaque ville du système (ce critère n’est aucunement spatial et il concerne les villes prises une à une, donc à un niveau micro) ;
que les écarts soient répartis afin que soient préservées les caractéristiques de l’évolution du système en termes de concentration ou de polarisation (c’est-à-dire de relation des différentes masses urbaines entre elles dans l’espace) (ce critère est avant tout mésospatial) ;
que les écarts soient aléatoirement répartis dans l’espace afin que les caractéristiques attachées à l’évolution de l’ensemble du système soient préservées, entre autres, en ce qui concerne le déplacement du centre de gravité des populations (il faut éviter, par exemple, que toutes les populations du nord-est soient surestimées et toutes les populations du sud-ouest, sous-estimées…)(ce critère est essentiellement macrospatial).
Ces trois critères sont si différents qu’il a longtemps semblé quasi impossible de les fondre pour former un critère synthétique unique. Cependant, il a été finalement possible de le faire en définissant un indice synthétique à maximiser. Cet indice appelé indice de conformité globale est la moyenne des trois indices de conformité suivants :
l’indice de conformité EQM* du point de vue des écarts quadratiques moyens, cet indice étant égal à (EQMmax – EQMobtenue) / EQMmax, c’est-à-dire à la différence entre la somme maximale possible EQMmax des écarts quadratiques dans le cas examiné et la somme EQMobtenue des écarts quadratiques produits par un scénario donné, divisée par la somme maximale possible EQMmax ;
l’indice de conformité C* du point de vue des indices de concentration C, cet indice étant égal à (∂Cmax – ∂Cobtenu) / ∂Cmax, c’est-à-dire à la différence entre l’écart maximum possible ∂Cmax entre l’indice C de concentration observé et l’indice C’ simulé et l’écart obtenu ∂Cobtenu entre l’indice C de concentration observé et l’indice C’ simulé, divisée par l’écart maximum possible ∂Cmax ;
l’indice de conformité H* du point de vue du déplacement du centre de gravité, cet indice étant égal à (∂Hmax – ∂Hobtenue) / ∂Hmax, c’est-à-dire à la différence entre la distance maximale possible ∂Hmax entre le centre de gravité observé et le centre de gravité simulé et la distance obtenue ∂Hobtenue entre le centre de gravité observé et le centre de gravité simulé, divisée par la distance maximale possible ∂Hmax.
La valeur des indices de conformité varie entre 0 et 1, la valeur 1 correspondant à une totale conformité des simulations avec les évolutions observées. L’indice de conformité globale étant la moyenne de ces trois indices, il varie lui aussi entre 0 et 1. Le meilleur des soixante scénarios simulés est celui qui a l’indice de conformité globale le plus élevé.
Il convient de noter que l’un des défis des prochaines années sera de perfectionner la procédure d’identification du scénario optimal à l’aide de l’analyse combinatoire. Il apparaît que plusieurs combinaisons de valeurs différentes de i, a, r et m peuvent correspondre à des valeurs très semblables de l’indice de conformité globale. L’analyse combinatoire devrait permettre de rendre beaucoup plus efficace la recherche du scénario optimal en rendant plus systématique le choix des scénarios à analyser. Bien que considérable, le nombre de soixante scénarios demeure infime si on considère l’infinité de scénarios possibles. L’analyse combinatoire devrait permettre de choisir ces scénarios suivant une logique itérative de type algorithmique, ce qui conduirait à un perfectionnement considérable de l’approche topodynamique.
Une fois les valeurs optimales de i, a, r et m estimées, l’approche topodynamique estime, à l’aide d’un scénario moyen correspondant à la moyenne d’une dizaine de simulations complètes effectuées en utilisant les valeurs optimales des paramètres, les correctifs requis pour tenir compte des écarts entre les valeurs obtenues sur ordinateur pour chaque ville ou région grâce au scénario moyen et les évolutions observées pour les mêmes villes ou régions. Les correctifs calculés pour chaque ville ou région sont alors intégrés au modèle pour générer à partir du schéma spatial le plus récent (en l’occurrence, la distribution spatiale de 2001) les projections avec correctifs.
La lecture des résultats des différentes projections se fait à l’aide d’horizons prédéterminés : par exemple, aux horizons 2015, 2025 et 2060. Évidemment, les projections pour 2060 sont plus contrastées que celles pour 2015 ou 2025. Elles constituent un test pour la vraisemblance et la cohérence des projections obtenues. Alors que les projections démographiques ou économétriques traditionnelles deviennent rapidement invraisemblables ou même aberrantes au-delà d’un horizon de 10 ou 15 ans, les projections topodynamiques présentent l’intérêt notable de demeurer vraisemblables et cohérentes même à des horizons de 50 ou 60 ans. Cela dit, il convient de toujours garder à l’esprit que des projections ne sont pas des prévisions. Une projection correspond à l’état d’un système qui est susceptible d’exister si un certain nombre de tendances caractéristiques de ce système se perpétuent dans le temps. Évidemment, si ces tendances changent, les projections sont forcément modifiées. C’est d’ailleurs parce qu’elles ne sont pas des prévisions que les projections sont utiles : elles indiquent ce qui est susceptible de se réaliser si les tendances actuelles se maintiennent, des politiques appropriées pouvant faire en sorte que les évolutions indésirables annoncées par les projections soient déviées de leur cours.
La valeur d’une projection dépend avant tout de la fiabilité de ses bases théoriques. Par exemple, les projections démographiques traditionnelles basées sur la distinction entre croissance naturelle et migration ainsi que sur les composantes de la croissance naturelle (fécondité, mortalité, etc.) deviennent moins fiables dès que les phénomènes sur lesquels elles s’appuient deviennent instables ou imprévisibles. La force des projections topodynamiques tient à la très grande inertie des macro-évolutions géo-économiques sur lesquelles elles se basent. Ainsi, il convient de se demander quelle prévision démo-économique pouvait être faite, il y a soixante-cinq ans, en 1942, qui soit avérée aujourd’hui. Aucune des prévisions qui ont pu être faites à l’époque n’ont pu entrevoir ni le baby boom d’après-guerre, ni la chute de la natalité depuis les années 1960, ni l’effritement du mariage, ni l’incroyable expansion économique qui a suivi la Seconde Guerre mondiale, ni la stagflation observée dans les années 1970. Il y a, cependant, une chose qui était déjà prévisible et qui s’est effectivement réalisée à peu près au rythme qui était prévu, et c’est la poursuite en Amérique du Nord du mouvement topodynamique des populations et des activités économiques vers le sud-ouest, mouvement que les statistiques permettaient d’identifier à partir de 1790. Les mouvements topodynamiques demeurent une des bases les plus fiables de la prospective de long terme à cause de leur stabilité et de leur lenteur exceptionnelles. C’est ce filon que le modèle topodynamique exploite en tablant sur la nature entropique du monde des localisations où des centaines de milliers de décisions de localisations impliquant toutes des forces d’attraction et des forces de répulsion interagissent pour produire des tendances géoéconomiques qu’il s’agit de reproduire sur ordinateur à l’aide de milliers de problèmes d’attraction-répulsion interdépendants choisis aléatoirement suivant quelques paramètres. Le défi n’est pas de reconstituer la logique de chacune des centaines de milliers de décisions de localisations du réel, ce qui serait impensable. Il consiste plutôt à simuler l’ensemble du système dans une perspective entropique (comme lorsqu’il s’agit d’étudier le processus de diffusion d’un gaz dans l’atmosphère en renonçant à suivre la trajectoire de chacune des particules de ce gaz).
L’originalité du modèle topodynamique tient au fait qu’il utilise le problème d’attraction-répulsion pour produire, dans un contexte profondément différent de celui des modèles de la nouvelle économie géographique, des projections démo-économiques, que les modèles de la nouvelle économie géographique cherchent aussi à produire. Il fait cela sans avoir recours à des régressions, ni à l’économétrie traditionnelle, ni à aux modèles d’équilibre général et ni à la microéconomie non spatiale.
Une grande partie de la différence entre les deux approches tient à la conception de l’espace. Le modèle topodynamique a, depuis le début, été conçu dans le contexte d’un espace continu comprenant une infinité de points (bien que, lors des applications concrètes, le nombre de points soit élevé, mais fini). Cela s’est fait d’abord en considérant un espace plan, puis, quand est venu le moment de faire des projections à l’échelle de la planète entière, une version sphérique du modèle a été mise au point (Tellier, 2002) [3]. La principale richesse des données que l’approche topodynamique tente d’exploiter, c’est leur désagrégation spatiale. Plus les données sont désagrégées, plus le modèle topodynamique peut extraire d’informations utiles à des fins de projection. De leur côté, les modèles de la nouvelle économie géographique ont traditionnellement été conçus dans le contexte d’un espace discret. Les premiers modèles ne prenaient même en compte que deux régions. Donc, leur espace se résumait à deux points.
Conclusion : de la convergence possible du modèle topodynamique et des modèles de la nouvelle économie géographique
Le modèle de Fujita et Thisse laisse entrevoir la convergence prochaine des deux approches. En effet, ce modèle ouvre la voie à une réconciliation de toutes les échelles spatiales, de la plus micro (se rapprochant de l’espace continu du modèle topodynamique) à la plus macro, celle des grandes régions de Krugman. Cette convergence est susceptible de produire des fruits dans les domaines de la méthodologie en enrichissant l’économétrie axée sur les régressions par l’introduction de processus de type Monte Carlo et en déplaçant l’accent de la recherche de l’exactitude au niveau des diverses équations constitutives du modèle vers la recherche de l’exactitude au niveau de l’ensemble du système décrit par les équations. Du point de vue théorique, cette convergence des deux approches permettrait d’introduire le concept d’inertie topodynamique dans la nouvelle économie géographique et, inversement, de mieux faire comprendre le concept d’inertie topodynamique à la lumière des phénomènes de déséquilibre spatial à la Myrdal (1957) étudiés par la nouvelle économie géographique. Cela devrait se faire en faisant systématiquement appel à l’histoire économique qui est un champ d’intérêt commun à l’approche topodynamique et à la nouvelle économie géographique.
Il convient de souligner le caractère novateur de l’approche topodynamique qui propose une voie non économétrique à l’étude des phénomènes spatio-économiques. Cette voie est infiniment plus complexe que l’approche traditionnelle basée sur des régressions. Dans le modèle topodynamique, il ne s’agit plus d’ajuster des droites à des nuages de points, mais bien d’ajuster l’évolution d’un système théorique de problèmes de localisation interdépendants à l’évolution d’un système de localisation observé. Ce problème est extrêmement complexe du point de vue mathématique [4] et le défi méthodologique est moins de le complexifier (ce qui est relativement facile) que de le simplifier sans trahir les objectifs fondamentaux du modèle et, pour ce faire, de mettre à contribution les ressources les plus avancées de l’analyse combinatoire.
Plutôt que de considérer les possibilités méthodologiques offertes par cette avenue originale, il est tentant de tuer la démarche dans l’oeuf en refusant de voir les portes qu’elle pourrait permettre d’ouvrir en l’attaquant systématiquement au nom du refus du changement et au nom de toutes les critiques philosophiques, sociologiques et anti-économiques habituelles. L’approche topodynamique et la nouvelle économie géographique s’inscrivent dans un courant scientifique où la confrontation au réel sert de test.
Un mariage du modèle topodynamique et des modèles de la nouvelle économie géographique est possible, entre autres, en rationalisant à l’aide de ces derniers les correctifs du modèle topodynamique. L’approche topodynamique part du fait que l’évolution des phénomènes géo-économiques est le produit d’un nombre considérable de forces d’attraction et de répulsion en interaction et qu’il existe dans l’espace géo-économique des effets systémiques perceptibles au niveau macro qu’il y a lieu de tenter de reproduire, à l’aide du problème d’attraction-répulsion, un peu comme les météorologues reproduisent sur ordinateur les effets systémiques du mouvement des zones cycloniques et anticycloniques. De son côté, la nouvelle économie géographique part de la microéconomie pour étudier les jeux d’agglomération-dispersion qui marquent les évolutions géoéconomiques. Les deux approches partagent le même point de départ théorique. Elles étudient les mêmes phénomènes de polarisation de l’espace économique. Rien n’empêche qu’elles convergent.
Parties annexes
Notes
-
[1]
Un modèle d’équilibre général se caractérise par une certaine circularité, en ce sens que le système est pour ainsi dire bouclé. Le terme équilibre peut porter à confusion dans la mesure où certains pourraient croire qu’un tel modèle ne peut produire que des équilibres, ce qui est faux. Au contraire, les modèles de la nouvelle économie géographique se concentrent le plus souvent sur l’étude d’évolutions marquées par des déséquilibres qui peuvent soit se résorber, soit s’accentuer.
-
[2]
Presque parce que peu de localisations optimales se retrouvent sur la frontière ou très près de la frontière externe de l’espace convexe considéré lors des simulations, ce qui constitue une régularité non aléatoire.
-
[3]
Le passage du plan à la sphère présente un avantage notable. En effet, sur la sphère, tout point de répulsion peut être remplacé par un point d’attraction situé à son antipode.
-
[4]
Le modèle topodynamique est aussi particulièrement lourd du point de vue informatique. Une application du modèle sur un micro-ordinateur de forte puissance requiert une semaine de calculs, jour et nuit.
Bibliographie
- CHEN, Pey-Chun, HANSEN, Pierre, JAUMARD, Brigitte et TUY, Hoang (1992) Weber’s Problem with Attraction and Repulsion. Journal of Regional Science, vol. 32, no 4, pp. 467-486.
- COMBES, Pierre-Philippe, MAYER, Thierry et THISSE, Jacques-François (2006) Économie géographique. L’intégration des régions et des nations. Paris, Economica.
- FUJITA, Masahisa et THISSE, Jacques- François (2002) Economics of Agglom-eration. Cities, Industrial Location, and Regional Growth. Cambridge, Cambridge University Press.
- HOTELLING, Harold (1929) Stability in Competition. Economic Journal, vol. 39, no 153, pp. 41-57.
- KRUGMAN, Paul R. (1991) Increasing Returns and Economic Geography. Journal of Pol-itical Economy, vol. 99, no 3, pp. 483-499.
- KRUGMAN, Paul R. et ELIZONDO, R. Livas (1996) Trade Policy and the Third World Metropolis. Journal of Development Economics, vol. 49, no 1, pp. 137-150.
- KRUGMAN, Paul R. et VENABLES, A. (1995) Globalization and the Inequality of Nations. Quarterly Journal of Economics, vol. 100, no 4, pp. 857-880.
- KUHN, Harold W. et KUENNE, Robert E. (1962) An Efficient Algorithm for the Numerical Solution of the Generalized Weber Problem in Spatial Economics. Journal of Regional Science, vol. 4, no 2, pp. 21-34.
- MYRDAL, Gunnar Karl (1957) Economic Theory and Underdeveloped Regions. London, Duckworth.
- OTTAVIANO, Gianmarco, TABUCHI, Takatoshi et THISSE, Jacques-François (2002) Ag-glomeration and Trade Revisited. International Economic Review, vol. 43, no 2, pp. 409-436.
- OTTAVIANO, Gianmarco et THISSE, Jacques-François (2005) New Economic Geography: What about the N? Environment and Planning A, vol. 37, no 10, pp. 1707-1725.
- TELLIER, Luc-Normand (1972) The Weber Problem: Solution and Interpretation. Geographical Analysis, vol. 4, no 3, pp. 215-233.
- TELLIER, Luc-Normand (1985) Économie spatiale : rationalité économique de l’espace habité. Chicoutimi, Gaëtan Morin éditeur.
- TELLIER, Luc-Normand (1992a) From the Weber Problem to a «Topodynamic» Approach to Locational Systems. Environment and Planning A, vol. 24, no 6, pp. 793-806.
- TELLIER, Luc-Normand (1992b) Introduction to Topodynamic Analysis: A New Approach to Forecasting the Spatial Distribution of Population and Activities. INRS Urbanisation, Collection Villes et développement.
- TELLIER, Luc-Normand (1995) Projecting the Evolution of the North American Urban System and Laying the Foundations of a Topodynamic Theory of Space Polarization. Environment and Planning A , vol. 27, no 7, pp. 1109-1131.
- TELLIER, Luc-Normand (2002) Étude prospective topodynamique du positionnement de la grande région de Montréal dans le monde aux horizons 2012, 2027 et 2060. Département d’études urbaines et touristiques, UQAM, Études, matériaux et documents 18.
- TELLIER, Luc-Normand (2004) Et si les économies d’agglomération n’existaient pas, notre monde serait-il différent ? Organisations et territoires, vol. 13, no 3, pp. 77-80.
- TELLIER, Luc-Normand (2005) Redécouvrir l’histoire mondiale, sa dynamique économique, ses villes et sa géographie. Montréal, Éditions Liber.
- TELLIER, Luc-Normand, CECCALDI, Xavier et TESSIER, François (1984) Simulation des phénomènes de polarisation et de répulsion à partir du problème de Weber. Document de travail no 70, Institut de mathématiques économiques, Université de Dijon.
- TELLIER, Luc-Normand et POLANSKI, Boris (1989) The Weber Problem: Frequency of Different Solution Types and Extension to Repulsive Forces and Dynamic Processes. Journal of Regional Science, vol. 29, no 3, pp. 387-405.
- THÜNEN, Johann Heinrich von (1826) Der Isolierte Staat in Beziehung auf Landwirtschaft und Nationalökonomie. Hamburg, Puthes.
- WEBER, Alfred (1957) [1909] Alfred Weber‘s Theory of the Location of Industries. Chicago, University of Chicago Press.
Liste des figures
Figure 1
Traçage des angles de 120 degrés (problème de Fermat)
Figure 2
Superposition des vecteurs et de la carte géographique
Figure 3
Détermination du point optimal O (problème de Fermat)
Figure 4
Traçage des angles permettant d’annuler les forces (problème de Weber)
Figure 5
Superposition des vecteurs et de la carte géographique
Figure 6
Détermination du point optimal O (problème de Weber)
Figure 7
Traçage des angles permettant d’annuler les forces (problème d’attraction-répulsion)
Figure 8
Superposition des vecteurs et de la carte géographique
Figure 9
Détermination du point optimal O (problème d’attraction-répulsion)