
Résumés
Abstract
The paper investigates the notion of Translation Units (TUs) from a cognitive angle. A TU is defined as the translator’s focus of attention at a time. Since attention can be directed towards source text (ST) understanding and/or target text (TT) production, we analyze the activity data of the translators’ eye movements and keystrokes. We describe methods to detect patterns of keystrokes (production units) and patterns of gaze fixations on the source text (fixation units) and compare translation performance of student and professional translators. Based on 24 translations from English into Danish of a 160 word text we find major differences between students and professionals: Experienced professional translators are better able to divide their attention in parallel on ST reading (comprehension) and TT production, while students operate more in an alternating mode where they either read the ST or write the TT. In contrast to what is frequently expected, our data reveals that TUs are rather coarse units as compared to the notion of ‘translation atom,’ which coincide only partially with linguistic units.
Keywords:
- human translation process,
- granularity of translation units,
- production unit,
- fixation unit,
- attention in translation
Résumé
Le présent article examine la notion d’unités de traduction (UT) sous un angle cognitif. Une UT est définie comme l’unité sur laquelle l’attention du traducteur se focalise. L’attention pouvant être dirigée vers la compréhension du texte source (ST) ou la production du texte cible (TT), ou les deux, le mouvement des yeux et le rythme de frappe des traducteurs sont tous deux analysés. Nous décrivons des méthodes permettant de repérer les motifs de frappe (unités de production) et les schémas de fixation du regard sur le texte source (unités de fixation). De plus, nous comparons les performances des étudiants avec celles des traducteurs professionnels. La principale différence entre les étudiants et les traducteurs professionnels réside dans le fait que ceux-ci sont mieux en mesure de diviser leur attention et de l’accorder de façon parallèle à la lecture ST (compréhension) et à la production de TT, tandis que les étudiants tendent à alterner la lecture du ST et la rédaction du TT. Enfin, contrairement à ce qui est généralement attendu, nos données révèlent que les UT sont assez grossières, comparativement à la notion d’« atome de traduction », qui coïncide seulement partiellement avec les unités linguistiques.
Mots-clés :
- processus de traduction humaine,
- granularité des unités de traduction,
- unité de production,
- unité de fixation,
- attention en traduction
Corps de l’article
1. Introduction
There is a large body of literature on segmentation in translation which can be separated into two fundamentally different kinds: research into human translation processes seeks to find basic segments of activities in the translation process, whereas others think of the segments more statically as properties observable in the translation product i.e., correspondences in the pair of texts as a result of the translation process. Accordingly, there is a confusion in the usage of the term translation unit which sometimes refers to the former and sometimes to the latter type of unit. However, it is by no means clear that there is an isomorphism between the units that a translator has in mind during translation and the correspondences which can be found in the final translation product.
According to Vinay and Darbelnet (1958) translation units are lexicological units: they are signs, each with de Saussure’s two components the signifiant and the signifié. Such a unit is “the smallest segment of the utterance where the cohesion of signs is such that they cannot be translated separately” (Vinay and Darbelnet 1958: 16). Bennett (1994) takes the more dynamic view, seeing them as “the section of text which the translator focuses on at any one time.” According to Bennett (1994), translation units are organized in a hierarchical manner, so that each of them is “part of a larger unit, and so on up till the entire text is reached.” As an example illustrating different organization principles, Sager (1993) mentions two factors which have an impact on the “size of units of linguistic equivalence translators operate with”: i) the translation technique and ii) the nature of the document. Similarly, for Alves and Vale (2009: 254) the translation unit is the “translator’s focus of attention at a given time in the translation process.” This definition implies that the units change over time, so that different instances of a given word in the source text (ST), or a passage of the target text (TT), may belong to different TUs.
The term translation unit, thus, seems to refer to a variety of activities and/or text correspondences which may be discovered in the process data or in the product data. In order to overcome this ambiguity, we distinguish the term translation unit (TU) from alignment unit (AU) in the following way.
An alignment unit (AU) refers to translation correspondences in the product data. An AU is a pair of aligned ST and TT words which cannot be decomposed into smaller correspondences, in the sense of Vinay and Darbelnet (1958), above. Accordingly, an alignment shows “which parts of the source text correspond with which parts of the target text” (Dagan, Church et al. 1993: 1). We contemplate alignments of words and continuous or discontinuous sequences of m-to-n ST-to-TT words. For instance, the AU “life sentences ↔ domme på livstid” is a 2-to-3 translation relation which can be observed and marked in the product data, i.e., in a translated text.
A translation unit (TU), we take it, refers to units of cognitive activity, i.e., the “translator’s focus of attention” in the sense of Bennett (1994) and Alves and Vale (2009). A similar distinction is also made by Kondo (2007) and Malmkjaer (2006), who identify lexical units and cognitive units. For Malmkjaer (2006), the lexical sense is a “product-oriented TU” and the cognitive one a “process-oriented TU.” Kondo (2007: 2) assumes that cognitive units are consistent with linguistic ones but that cognitive units are “likely to be larger than lexical translation units, e.g., whole texts, paragraphs, sentences, and clauses.”
1.1. Physical Traces of Translation Units
While lexical units can be observed in texts, cognitive units and the “translator’s focus of attention” cannot. With eye-tracking and keyboard logging technology we are able to record the translators’ reading and writing behavior, i.e., sequences of keystrokes and word fixations in time, so-called user activity data (UAD). In order to infer from the UAD the translator’s cognitive activities of attention, we rely on the “eye-mind assumption” (Just and Carpenter 1980), which hypothesizes that “there is no appreciable lag between what is being fixated and what is being processed” (Just and Carpenter 1980: 331). Similarly, Anderson (1980: 81) points out that “we are attending to that part of the visual field which we are fixating.” A similar assumption can be made with respect to typing activities: it is likely that the translator’s focus of attention is close to what s/he writes, and that units of text production coincide to some extent with the entities of the translators’ cognitive processes. With these considerations, we can re-construct a TU as a set of reading and writing activities. A TU consists of:
writing activities to produce a chunk of TT within a certain lapse of time;
reading activities of the ST, sufficient to gather what translation(s) should be produced; and
the ST segment(s) of which the produced TT is a translation.
1.2. Divided and Alternating Attention
The interaction and dependencies between reading and writing activities have been discussed in the translation process literature. Dragsted (2010) points out that ST comprehension and TT production are present during translation, but “cannot easily be separated as two distinct activities.” She distinguishes between integrated coordination where TT production takes place almost simultaneously with ST reading and sequential coordination where ST comprehension and subsequent TT production occur independently, sometimes associated with a pause.
Ruiz, Paredes et al. (2008) use the terms vertical translation to describe translation as a sequential process in which the ST must be fully understood before any TT production can take place and horizontal translation as an integrated process where linguistic features of the SL are instantly replaced in the TT. They find that lexical and syntactic code-to-code links between the SL and TL must exist during horizontal translation processing.
Similarly, Jensen (2008) distinguishes between serial and parallel translation production. In a serial production, TT writing takes place only when a ST segment has been fully comprehended whereas during parallel production TT writing and ST reading occur simultaneously.
The common observation of these authors is that the translators’ attention can focus on the ST, on the TT or on both texts at the same time. Attention is considered to be the “select allocation of cognitive processing resources” (Anderson 2000: 47). Whereas, at some times the focus of a translator’s attention will switch back and forth between understanding the ST and production of the TT, at other times it may be focused on the two tasks simultaneously. Accordingly, there are two different kinds of attention that might play a role in translation:
Alternating attention: This refers to the mental flexibility that allows individuals to shift their focus of attention and move between tasks with different cognitive requirements;
Divided attention: This refers to the ability to respond simultaneously to multiple tasks or multiple task demands. It represents a higher level of attention.
Below we will investigate the amount of alternating and divided attention found in student and professional translators. We show that the former type of behavior is prevalent in novices, while divided attention predominates in that of experienced translators, especially those who are touch typists. The cognitive process of coordinating reading and writing activities and transforming ST meaning into TT expressions is more demanding for students than for professionals.
1.3. Production Units and Fixation Units
To measure and quantify the amount of alternating and divided attention, we will analyze the UAD of 24 translations. Three types of phenomena will be investigated:
units of TT production (PUs);
units of ST fixations (FUs); and
the relationships and overlap between the two types of units.
In line with the observations above we assume that the observable production units (PUs) and fixation units (FUs) are indicative of the indirectly observable cognitive processes of attention, i.e., the processed TUs. We will quantify how TUs vary between student and professional translators
We define a FU (a fixation unit) as a sequence of two or more ST fixations where the time interval between the end of one fixation and the beginning of the next fixation does not exceed a given time threshold. Since reading is generally less linear than writing, and readers are likely to skip e.g., function words (Radach, Kennedy et al. 2004), we allow long saccades between non-adjacent words in the ST. An FU border occurs either if the gaze leaves the ST, or if two successive fixations on the ST are separated by a long gap in time, which exceeds a predefined FU segmentation threshold. Further, we distinguish between two types of FUs: alternating and divided FUs. For a FU to be “divided,” at least one keystroke must simultaneously be typed (i.e., attention is divided between ST reading and TT typing), while no simultaneous keystrokes are observed for alternating FUs (i.e., attention is alternating between ST reading and TT typing). Note that this distinction coincides with Dragsted’s (2010) integrated and sequential coordination, Ruiz, Paredes et al.’s (2008) vertical and horizontal translation and Jensen’s (2009) parallel and serial translation production.
We define a text production unit (PU) as a sequence of:
successive keystrokes in time that are not interrupted by a pause longer than a given PU segmentation threshold. Only deletion and insertion keystrokes are considered. Navigation activities, using the mouse or combinations of keystrokes, are ignored;
successive keystrokes in text that produce a coherent piece of text. Text producing and deleting activities are part of the same PU only if they are in close proximity to each other.
The boundary of a PU is thus defined as lying between two successive keystrokes that are separated by more than a certain delay in time, or if the second keystroke contributes to production or revision of a different piece of text. Thus, deletions and corrections are possible in one PU if they are within the vicinity of the current cursor position. A correction or insertion of text more than two AUs away would result in a PU boundary.
1.4. Cognitive Plausible Segmentation
Note that not all conceivable PUs are similarly likely to reflect a unit of the translator’s focus of attention. Recall that a TU encloses a coherent set of signs that should correspond to grammatical units. We therefore expect PUs to satisfy two properties:
they should represent complete meaning entities rather than arbitrary sequences of characters;
they should align with AU boundaries, rather than crossing their lines.
The paper investigates various PU segmentation thresholds so as to maximize the likelihood that the PUs comply with these properties of the TUs. We will see that both claims cannot be verified in our data.
In section 2 we describe the experimental setup for data acquisition, the hardware and software used to collect the UAD as well as details about the translation task. In section 3 we describe translation progression graphs as visualization of the experimental data and illustrate the structure of the UAD. Section 4 looks into details and analyses a data segment in depth. It draws first conclusions on the properties between FUs and PUs. Section 5 applies the technique to a set of 24 translations and correlates the isolated PUs and FUs. Finally, section 6 looks at the effects of divided and alternating attention, and section 7 concludes the paper.
2. Data acquisition
We base our research on a translation experiment in which 12 professional and 12 student translators participated. All student translators were in their final year of MA in Translation and Interpreting studies, with L1 Danish and L2 English. The students had between no and 2 years of professional experience. The professional translators had all completed an MA in Translation and Interpreting studies; they were all state-authorized translators from English into Danish with 8 to 30 years of professional experience.
All 24 translators produced translations using the Translog (Jakobsen 1999) software.[1] Translog is a data-acquisition software for all kinds of computer-based reading and writing experiments. It presents the ST in the upper part of the monitor, and the TT is typed in a window in the lower part of the monitor. When the start button is pressed, the ST is displayed and eye movement and keystroke data begin being registered. The task of the translator was to type the translation in the lower window. After having completed the translation, the subject pressed a stop button, and the translation, together with the UAD, was stored in a log file.
Each translator was given a short introduction to the software and how to operate it.[2] To enable us to keep track of all their activities, it was decided not to allow translators to use any additional resources since that would have distracted their attention away from the monitor, or to a workspace (e.g., electronic dictionaries, web-pages etc.) which cannot be controlled from within Translog. A translation session lasted usually no longer than ½ hour, (including introduction) so that we can assume a comparable level of concentration during the entire translation time. Translators received remuneration for their effort.
The collected UAD was then transformed into a relational data structure which allowed us to map eye movements and keyboard actions onto ST and TT positions and vice versa. In order to do so automatically, the relational data structure requires, besides the preparation of the keyboard and eye movement data, also the alignment information between the ST and the TT. Carl (2009) and Carl and Jakobsen (2010) describe how keyboard actions are mapped on TT words and further how TT words are mapped on ST words, so that we can determine for (almost) each keystroke to which ST translation it contributes.
2.1. Preprocessing the Keyboard Data
We have manually aligned the ST and TT for all 24 translations, using the DTAG toolkit (Kromann 2003). The DTAG tool allows (and actually recommends) annotation of various degrees of alignments as fuzzy or syntactic and suggests various strategies to align multi-word units and discontinuous translations.
Keystroke activities are transformed from the Translog native ‘event-oriented’ representation into a semantically motivated XML representation. This representation keeps only the text-modifying information and discards the navigation activities. For instance, text can be deleted in very many different ways, typically through backspace or by pressing the delete key. A piece of text can also be deleted by first highlighting it and then hitting the delete or backspace key or even by overwriting the highlighted sequence with other characters. Highlighting of the text can, again, be achieved by various means, e.g., by using the mouse or by a combination of using shift and left, right, up, or down keys, or even pressing shift control and left, right, up, or down keys, etc. All these events are coded differently in Translog output, and the full information is needed to replay the translation session in a natural way.
For an analysis of how a translation emerges, a more reduced representation is sufficient. For our intended analysis it is enough to observe that the sequence in question was deleted. We are not so much interested in how the cursor was moved to a particular position in the text, but rather that the text was modified at a particular point in time. To know what happens to the text, we are basically only interested in knowing the text insertions and the deletions that take place at any point in time.
2.2. Preprocessing the Gaze Data
Conversion of the eye-tracking data into word fixations is more difficult. To capture the reading behavior of the translators, we used a Tobii 1750 remote eye-tracker. The Tobii software provides the X/Y coordinates of the left and right eye every 20 ms together with pupil dilation and other information. In order to understand what words the person reads, i.e., what words s/he looks at, the X/Y gaze-sample points need be mapped on the word locations. For this so-called gaze-to-word mapping (GWM) we used a software (Špakov 2008) which is part of an experimental Translog implementation. GWM consists of a fixation detector which groups sequences of gaze-sample points into fixations and in a second step maps the fixations on the word positions, currently only for the Translog ST window.[3]
Because of various sources of noise, such as free head movement, changes in pupil dilation due to the luminosity of the screen and the environment, as well as physiological parameters of the translator (humidity of eyes, colour of pupils, etc.), the mapping of these pixel positions on the words is not straightforward. GWM (as similar other programs) makes use of a number of filters and heuristics, as well as a model of the underlying text to guess which word was most likely looked at. Precision is estimated to be 80% by Dragsted and Hansen (2008) while Jensen (2008) reports detection rates (recall) between 65% and 75%. We will show below that, in some cases, stretches of fixations are either entirely missing or misplaced, and consequently we have to use methods to deal with these imprecisions.
GWM was set to produce a minimal fixation duration of 150 ms and the maximum diameter of a fixation was set to 30 pixels, so that no two gaze-sample points in one fixation are separated by more than 30 pixels.
3. Translation Progression Graphs
The notion of a progression graph was introduced by Perrin (2003) to conceptualize and visualize writing progression. The translation progression graph in Figure 1 depicts the development of the work of a professional translator (P13), showing keystrokes, gaze behavior and various kinds of PU and FU segmentations. The horizontal axis represents the translation time in ms, and the vertical axis plots the ST from the beginning (bottom), to the end (top).[4]
As described in Carl (2009), keystrokes which actually create the TT, are associated with the ST words which they are a translation of and are represented as single dots in the graph. All keystrokes that contribute to the translation of the n-th ST word are represented as single dots in the n-th line from the bottom of the graph.
The gray line plots the translator’s gaze activities on the ST. Single fixations are marked with a dot on the fixation line. The graph shows three types of PUs with the PU thresholds of 400 ms, 800 ms and 1500 ms. It also shows two types of FUs with FU threshold of 400 ms and 800 ms.
3.1. PUs and FUs in Progression Graphs
The upper part of Figures 1 and 2 show three types of PU patterns and two types of FU patterns. The lower pattern (around 170) shows the 400 ms PU segmentation, above (around 190) the 800 ms PU segmentation is shown and around 210 is plotted a PU pattern as achieved with a 1500 ms PU segmentation threshold. Successive PUs are shown in two alternating lines so that their borders are easier to distinguish.
As defined above, all keystrokes are part of the same PU for which adjacent pairs are separated by less than the PU segmentation threshold. The more time one allows between successive keystrokes, the longer the PU will be. If all intervals separating successive keystrokes exceeded the PU threshold, then each keystroke would form a proper PU. If no interval exceeds the threshold, then all coherent keystrokes are collected into a single PU. Accordingly, there are many more PUs for the shorter 400 ms segmentation threshold than there are for the 1500 ms threshold.
Different segmentation thresholds do not have a major impact on the size and number of FUs. An FU boundary coincides in most cases with the end of a gazing activity on the ST, and the number of FUs essentially reflects the fact that the eyes constantly wander from the ST window to the TT window and (perhaps) to the keyboard, or elsewhere. A different segmentation threshold does not appear to have any great impact.
Above the 400 ms FU segments in the graphs are also indicated the type of segment, alternating (A) or divided (D). Translator P13 (in Figure 1) has many more segments than translator S5 (Figure 2), and P13 has many D-type FUs, while S5 has many more A-type FUs.
Figure 1
Translation progression graph of a professional translator (P13)

The graph shows keystrokes, eye movements, two types of FU segmentation and three types of PU segmentation. An “A” and” D” in the top line indicate whether the FU is alternating or divided, respectively.
Figure 2
Translation progression graph of a student translator (S5)

The graph shows keystrokes, eye movements, two types of FU segmentation and three types of PU segmentation.
3.2. Progression Graphs and Translation Phases
Translators vary greatly with respect to how they produce translation. The translation process can be divided into three phases, which we refer to as skimming, in which the translator acquires a preliminary notion of the content of the ST, drafting in which the actual translation is typed, and revision in which some or all of the translated text is reread, typos are corrected and sentences possibly reformulated or rearranged in light of the better understanding of the contents of the ST that has been acquired by the time this stage is reached.
Figure 2 shows a long initial skimming phase between seconds 0 to 40 in which the entire text is read, followed by a drafting phase until second 560 and a final revision phase. While the reading progression during skimming is well represented, the fixation data in the drafting phase is very sparse in a number of places and gaze data appear to be missing. This may be due to a different sitting or head position of the translator during skimming and the drafting and/or because in contrast to drafting, skimming involves linear reading, which has proved to give better data. Discontinuous gaze movements during translation drafting troubles the system to an extent that in some cases the data can be too noisy to be processed by GWM.
In the drafting phase in Figure 2, there is only substantial reading data in 3 positions, around sec. 240, words 51-57: “found guilty of four counts of murder following,” between sec. 360-380, words 100-116: “the awareness of other hospital staff put a stop to him and to the killings” and between sec. 436 to 468, words 123-135: “the motive for the killings was that Norris disliked working with old people.”
At all other positions, only single fixations are registered, which in many cases did not trigger a FU segment.[5] Reading data from about sec. 164 to 232 appears to be completely missing. Since GWM does not produce data for TT fixations, this may also indicate that TT correction was being done in this period.
The revision phase in Figure 2 starts with a longer fragment of TT correction between secs 560 to 660, in which words 102 to 106 “awareness of other hospital staff” is modified, as well as words 17-22 “the killing of four of his patients” and words 34-36 “women in 2002.” Between secs 660 to 690 half of the ST is re-read and finally at sec. 690 “acting strangely” is modified.
Translator P13 in Figure 1 has a very different translation progression. Her translation has only a very short skimming phase of 10 secs, starting with the first fixation on word 31 “killed” followed by the reading of the title words 1-7: “Killer Nurse receives four life sentences.” The fixations on word 146 (“problems”) may originate from ‘random’ gaze movements as the translator moves back and forth between the ST and the TT, and can be considered as “noise.”
During the drafting phase, translator P13 moves constantly back and forth between the ST and the TT, where most of the time the gaze is on, or shortly ahead of the words currently being typed. The first 20 secs of the drafting phase (secs 10-30) is the longest period of time in the drafting phase in which no gaze data on the ST is registered. The translation session ends with a very brief revision phase (secs 280-310) in which no keystroke activities are performed.
4. Analysis of PUs and FUs for P13
This section looks closer at different ways of segmenting the first 76 keystrokes of translator P13 in Figure 1. As noted above, translator P13 starts producing the first keystrokes 10 seconds after the beginning of the translation session. From secs 10 to 40 she produces 76 keystrokes, which (basically) translate the first 6 AUs from English into Danish. These 6 AUs are reproduced in Figure 3, as they appear in her final translation.
Figure 3
Manually aligned AUs of the product data of translator P13

9 ST words are translated into 8 TT words, in 6 AUs.
While Figure 3 shows the static aspect of the data, Figure 4 schematically reproduces the process of how these translations evolve in time.
Figure 4
First 30 seconds (secs. 10-40) of the progression translation graph of a professional translator (P13)

The graph is an expansion of the first 30 s of Figure 1 and shows the translation progression for the production of the 6 AUs from Figure 3, including several PU and FU segmentation patterns.
The graph in Figure 4 shows the temporal distribution of the first 76 keystrokes of the translation in the bottom line, as well as various fragmentations into PUs, as produced with a 400 ms, 800 ms and 1500 ms PU segmentation threshold. Note that there are many more PUs with the 400 ms PU segmentation threshold than there are with the 1500 ms segmentation threshold. Figure 4 also shows patterns of FUs generated with 400 ms and 800 ms FU segmentation threshold. The AUs of Figure 3 are reproduced in Figure 4; borders of the 6 AUs are marked with dotted lines.
No eye movements are registered between time-stamps 10,000 and 30,000 (secs 10 and 30), in which AU1 to AU2 are generated. Between secs 30 and 40, a number of ST fixations are registered, which are plotted as (gray) lines above the keystroke data. Between secs 30 and 32, when producing AU5, a sequence of 5 fixations is recorded. The latter four of these fixations are clustered into one FU with the 400 ms segmentation threshold whereas all 5 fixations are subsumed into one FU when applying the 800 ms FU segmentation threshold. Since no keystrokes occur simultaneously during these reading events, the FUs are labeled alternating (A) on the top line. A second FU occurs between secs 35 and 37 when producing AU6. This FU consists of 4 fixations. Since some of the fixations occur simultaneously with keystroke events, this FU is classified as a divided (D) in the top line of Figure 4.
In the remainder of this section, we look closer at the time segment 10,000 to 30,000, in which the first 4 AUs are produced. We discuss properties of the PUs and show how these properties generalize to the entire translation session. In sections 5 and 6 we apply these criteria to all 24 translations.
4.1. Characteristics of 400 ms PU Segmentation
Details of the keystroke segmentations for the first 4 AUs (time 10,000 to 30,000) are reproduced in Tables 1 and 2. During these 20 seconds 56 keystrokes are produced (20 keystrokes are produced for AU5 and AU6). Each different PU segmentation groups the keystroke data differently with different properties of the produced PUs.
The 400 ms segmentation in Table 1 groups the 56 keystrokes into 10 PUs. Due to the pauses of 894 ms and 488 ms after “y” and “j” respectively, the word Mordersygeplejerske is segmented into 3 PUs. Note that the suffix ske is later deleted and thus does not appear in the final translation in Figure 3.[6] On the other hand, the two words modtager and fire are written smoothly so that here two AUs are grouped into one PU.
The “start” column in Table 1 indicates the time at which the typing of the PU began. The “dur” column shows the time needed to complete the PU and “pause” shows the interval of time from the last keystroke in the PU to the first keystroke in the next PU. Note that duration is 0 if the PU contains only one keystroke, since only inter-keystroke durations are measured. The “AU” column shows which AUs are generated by each PU. Thus, the first three PUs all contribute to the translation of the first AU1 while the fourth PU contains AU2 and AU3.
Table 1
Properties of PU as generated with 400 ms segmentation

A number of corrections occur in the following segments: first the letter “s” is written and then, in the next segment, deleted. The deletion is indicated in parentheses “(s).” Then “li” is produced and then deleted “(li).” Finally the translation domme på livstid is typed but segmented into 2 PUs due to the delay of 536 ms after på.
4.2. Classification Schema of PUs
The degree to which a PU coincides with a word in the TT translation or an AU boundary in the ST is indicated by its type. A PU can start and/or end at a word boundary. For instance, livstid is a complete word and PU10 starts and ends at a word separator. Mordersy in contrast is the beginning of a word while erske is the ending of that word. Accordingly, PU1 starts at a word boundary and PU3 ends with it.
In addition, a word (or segment) in the target language can start and/or end at an AU boundary. For instance, livstid is the last part of a compound which is grouped in AU4 (see Figure 3), and so it ends but does not start at the boundary of AU4. The sequence domme på is the beginning of that same compound and so PU9 starts, but does not end, at the AU4 boundary.
The type of a PU thus consists of four positions (bits), each of which can take two values: the first two positions indicate properties for the beginning of the PU and the last two positions indicate properties of its end. The values indicate whether or not the PU aligns with word borders in the target language and whether or not it aligns with borders of the AUs of which it is a translation. These values are represented by the letters [SWAU] which have the following meanings:
‐ S |
First/last character of PU was a word separator (space, comma, semicolon, colon) or immediately followed a separator. |
‐ W |
First/last character of PU was not a word separator (and did not immediately follow a separator). |
‐ A |
First/last character of PU was at a AU boundary. |
‐ U |
First/last character of PU was not at a AU boundary. |
Thus, “SAWU,” as in the first line of Table 1 indicates that the PU Mordersy starts at the beginning of a word (S), and it aligns with the beginning of an AU (A). The last two letters indicate that this PU ends in the middle of a word (W) and in the middle of an AU (U). Ideally, as discussed in the introduction, a PU should start and end with a word separator and/or an AU boundary, such as modtager fire in line 4 of Table 1. These pauses (and the resulting segmentation) in the middle of a word indicate (perhaps) that attention is focused on spelling or typing problems, rather than on a fresh segment to be translated. Thus, a PU of type “WUWU” (e.g., line 2: geplej) indicates that the segment neither starts nor ends at a word or an AU boundary. Such segments provide little insight into the cognitive processes of translators, since they do not coincide with meaning units, as e.g., words and AUs do. In the introduction we argued that PUs should represent signs, with a signifié, which is difficult to see in the case of geplej or li.
Four out of the 10 segments in Table 1 are of this type, indicating that a 400 ms segmentation threshold does not correspond to the “cognitive” rhythm of segmentation that we are looking for. We shall see that longer thresholds produce a higher percentage of units that coincide with meaning units, such as words or phrases.
Table 2
Segmentation 800 ms (above) and 1500 ms (below) of the same 36 keystrokes from Table 1

The notation “s(s)” and “[s]” are equivalent, meaning typing and deletion of the bracketed expression.
4.3. Segmentation Threshold and Types of PUs
The PU pattern in the upper part of Figure 4 and in Table 2 (800 ms segmentation threshold) generates only half the number of PUs compared with those for the 400 ms segmentation threshold. Only one of these (20%) is of the type “WUWU,” while the remaining four (80%) either start or end with a word separator. In the 1500 ms segmentation (lower part in Table 2) all PUs have linguistically plausible beginnings or endings. On the one hand, a segmentation with a higher threshold produces longer PUs and subsumes more than one AU. Thus, the average length of 400 ms, 800 ms and 1500 ms segments of the first 56 keystrokes in Tables 1 and 2 are 5.6, 11.2 and 18.7 keystrokes respectively. On the other hand they are linguistically and cognitively more plausible.
Table 3
Number and properties of FU and PU for translator P13, generated under various segmentation thresholds

Table 3 provides the figures for the entire translation of P13 with various thresholds for FU and PU segmentation. It shows the number of FUs and PUs, their average length in characters (#char), the percentage of linguistically plausible SASA and S.S.[7] segments and the percentage of linguistically implausible WUWU segments. With 400 ms, 800 ms and 1500 ms segmentation thresholds, translator P13 produces 98, 39 and 23 PUs. The optimum PU segmentation threshold seems to be around 1000 ms, where a maximum number of PUs are linguistically plausible. In section 5.4. we obtain similar results for an average over all 24 translators.
4.4. Alternating and Divided FUs
Table 3 also shows the relation between divided (D) and alternating (A) FUs with changing FU segmentation thresholds. As the FU segmentation threshold increases and the FUs become longer, fewer FUs will be generated. At the same time the chances increase that a keystroke occurs during those longer FUs. Consequently, the percentage of alternating FUs (%A) decreases and the percentage of divided FUs (%D) increases. Table 3 also shows that the number of PUs decreases much more quickly than the number of FUs, as the segmentation threshold increases. Thus, there are more than 20 times the number of PUs with the 200 ms segmentation (355) than there are with the 2500 ms segmentation threshold (14), whereas for FUs the ratio is close to 2:1 (55:25).
These results indicate that the computation of divided and alternating FUs depends on the setting of the segmentation threshold: with higher thresholds we arrive at fewer FUs but a higher percentage of divided FUs.
It also indicates that there is a trade-off between the length and the linguistic plausibility of the keystroke segmentation: shorter PUs contain roughly the number of characters that can be expected in AUs (Kondo 2007) such as typical dictionary entries and machine translation systems (i.e., on average below 10 characters), but they do not correspond to word boundaries. Longer PUs are more likely to start or end at word boundaries, but are much longer than what one would expect to be ‘translation atoms.’
This seems to indicate that TUs and attentional segments are not minimal units but rather correspond to a maximal segment that a translator is able to process. In the next section we show that the maximal segments change according to the experience and training of the translator.
Table 4
Translation time (T-time) and number of PUs for different kinds of segmentation thresholds for the 12 professional and 12 student translators

5. Properties of Production Units
This section investigates various PU segmentation thresholds for all 24 translations. As mentioned earlier in section 2, an English text of 160 words was translated into Danish by 12 professional and 12 student translators. There is a large variance in both overall time needed to complete the translation and in the number of PUs produced, as shown in Table 4. Professionals took on average slightly more than 5 minutes to translate the text (320 seconds), whereas students took more than 6 minutes (379 seconds). That is, professional translators need on average 84% of the time needed by students to complete the translation. For both groups there was approximately a factor of 3 between the fastest and slowest translator.
Below we discuss the figures in Table 4 from various different angles. We look at the average length of different kinds of PUs in terms of characters and time, the inner PU typing speed and the relation between PUs and AUs. We omit here a discussion on the translation quality and how to measure it. For more detail on this aspect, see Carl and Buch-Kromann (2010).
Figure 5
Number (vertical) and length (horizontal) of PUs in terms of AUs covered

5.1. Relating PUs and AUs
Figure 5 relates various PU segmentation types and the number of AUs that they cover. The 200 ms segmentation threshold produces more than 9000 PUs for all 24 translations, more than 6000 of which cover only one AU, and 3 PUs which cover 5 AUs. For the 1000 ms segmentation threshold these figures are 427 PUs which cover one AU and 59 PUs which are 5 AUs long. As the segmentation threshold increases, the graphs become flatter, indicating that longer PUs are segmented. While the shapes of the graphs for the 200 ms and 400 ms thresholds differ considerably, there is not much difference between the 800 ms, 1000 ms and 1500 ms segmentations. We take it that smaller segmentation thresholds lead to arbitrary segments, induced by motor skills or local decisions (such as immediately correcting typos), while the relative stability of segments as obtained with a segmentation threshold of 800 ms or higher represents a rhythm that better corresponds to the cognitive activity.
With a segmentation threshold of 1500 ms the longest PU is produced by translator P15, with 183 characters. With a threshold of 800 ms the longest PU is produced by translator P14, which comprises 18 AUs and the following 153 characters:[8]
[…] fordi Norris ikke kunne lide at arbejde med [g]aeldre mennesker. Alle hans ofte var s[v][a]vagelige aeldre kvin[ger ]der med hjerteproblemer. ALle [sic] ville…
[…] that Norris disliked working with old people. All of his victims were old weak women with heart problems. All of them could… (source text)
This PU starts with a subordinate clause, that is, the second half of a sentence; it then contains a whole sentence and ends with the beginning of a third sentence at word position 150.
Figure 6
Translation time (horizontal) and number of PUs (vertical) for students and professional translators and different segmentation thresholds
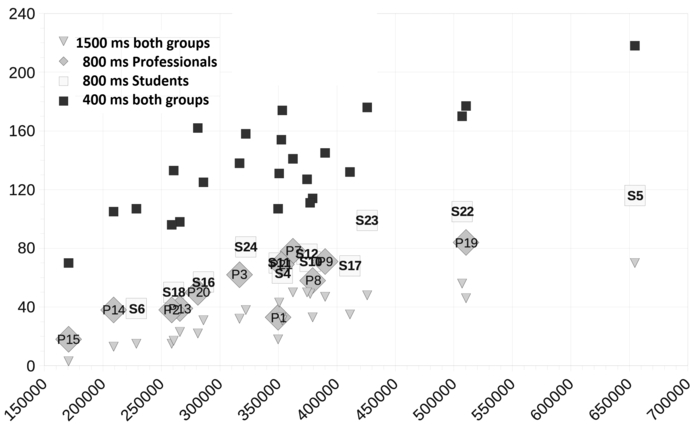
The graph shows a strong correlation between the translation time and the number of PUs for three types of segmentation thresholds.
5.2. Length and Duration of PUs
Students produce the translations on average with 30% more PUs than professionals, and there is a factor of almost 4 between the smallest and largest number of PUs produced for both groups. Figure 6 indicates the relation between the translation time and the number of PUs produced. It shows three different PU segmentations: the small black rectangular symbols represent the distribution of the 400 ms PU segmentation, the triangular symbols those of the 1500 ms PU threshold. The bigger squares and diamonds are 800 ms segmented PUs. Diamonds represent the students and the squares professional translators. As the segmentation threshold increases, fewer PUs are generated, but all segmentations indicate a strong correlation between translation time and the number of PUs. That is, the more the translation is fragmented, the longer is the translation time. The PUs produced by professionals are, on average, longer and the time needed per PU is (on average) higher for professionals than for the students.
Table 5
Average duration and length of PUs with various segmentation thresholds, and average typing speed for professional and student translators

The average duration and length for various PU segmentation thresholds is given in Table 5. Students generate, depending on the PU thresholds, on average, 15% to 30% shorter PUs in length as well as in duration. They also produce more segments than professional translators, as we have already shown above in Table 4 and in Figure 6.
5.3. Typing Speed
However, the typing speed in terms of characters per time within each PU does not seem to vary much between professionals and students. Table 5 shows that average and median speed between successive keystrokes decreases with a growing PU threshold. For instance, with the 800 ms segmentation threshold, professionals produce 5.44 keystrokes per second, while students produce 5.7 keystrokes per second.[9] Typing behavior of students is more fragmented than that of professionals, with more and longer pauses, but when actually writing the segments, the speed in which successive keystrokes are produced seems to be identical for both groups.
5.4. Optimal Segmentation Threshold
Table 6 shows the distribution of PU types with different PU thresholds. It gives an overview of the number of PUs produced with 6 different thresholds and shows the percentage of linguistic boundaries, similar to Table 3. The table does not make a distinction between students and professional translators. With increasing segmentation time, the number of generated segments decreases, and the percentage of meaningful segments increases. A dramatic change of this effect can be observed up to approximately 800 ms: the meaningless “WUWU” segments fall below 10% and the linguistically coherent ones grow to above 50%. Beyond this margin, values change less quickly.
Table 6
Number and properties of PUs for different segmentation thresholds

SASA: PUs start and end with a word separator and an AU boundary; S.S.: PUs start and end with a word separator; WUWU: PUs start and end in the middle of a word
We take it that the “optimal” PU segmentation threshold is around 1 sec. The likelihood of PUs to be consistent with linguistic entities (i.e., word and AU) is maximal for typing pauses of one second or more.
6. Properties of Fixation Units
Another observation can be made with respect to gaze patterns. As pointed out in the introduction, we distinguish between divided and alternating FUs. Divided FUs are characterized by keystroke activities while the translator reads a ST segment. Alternating FUs are characterized by the absence of this parallel keyboard activity during ST reading.
6.1. Alternating and Divided FUs
As with PUs, student and professional translators behave differently in their reading habits: Figures 7 and 8 show that students tend to work more in alternating mode than professional translators, while more divided FUs are observed for professionals than for students. This complies with an observation made by Sharmin, Špakov et al. (2008) that students struggle more with ST comprehension than professional translators: in many instances, all attention is absorbed by reading and understanding the ST, and thus no TT production can take place at the same time. Skilled professional translators, in contrast, may already start typing the translation of a passage while still reading/understanding the end of that ST passage. Accordingly gaze patterns on the ST and typing activities of the TT may overlap, PUs become longer, and translation production time becomes shorter. These findings are underpinned by the strong correlation of translation time and the amount of alternating FU pattern shown in Figure 7: more alternating FUs will correspond with longer total translation time. A reverse effect is visible in Figure 8: the more a translator produces divided FUs, the shorter is the total translation time.
Figure 7
Translation time (horizontal) and number of alternating FUs (vertical) for students and professional translators for the 200 ms FU segmentation threshold

A strong correlation can be seen between the number of alternating FUs and translation time. Students tend to show more alternating FUs than professionals.
Figure 8
Translation time (horizontal) and number of divided FUs (vertical) for students and professional translators (200 ms segmentation threshold)

A negative correlation can be observed between the number of divided FUs and translation time.
6.2. Duration of FUs
The average duration of the FUs differs with respect to their types (alternating vs. divided) and depends on whether they are produced by students or by professional translators. As already shown in Table 3, the number of FUs does not depend as much on the segmentation threshold as is the case for PUs. Similarly in Table 7, for all 24 translations, when increasing the FU threshold from 200 ms to 800 ms, the number of FUs is reduced by only approximately 14% from 677 to 585 and 22% from 708 to 550 for professional translators and students respectively, while the duration of FU increases by approximately 20% each time the segmentation threshold is doubled.
Table 7
Divided and alternating FU for professional and student translators for different kinds of segmentation

Only a fraction of the overall gazing time is spent on the ST during translation. In addition, students have longer FUs than professionals (roughly 20%). Table 7 shows figures for the entire ST reading time for all divided and alternating FUs. The table shows that professionals and students spent on average 57.85 and 71.41 secs. respectively on ST reading (with the 200 ms FU segmentation threshold). That is, professional translators need approximately 83% of the time for ST reading that students need. Given the average entire translation time of these two groups to be 320 and 379 seconds (see Table 4) we obtain ST reading time of 18% and 24%, for 200 ms and 800 ms FU segmentation thresholds respectively. Interestingly, students and professionals spent the same fraction of their total translation time on ST reading.
A still finer distinction can be made when looking at ST reading time during skimming, drafting and revision. Our data reveals that during drafting on average 19.31% (or 24.05%, when taking the 800 ms FU segmentation threshold) of the gazing time was focused on the ST. During skimming 80% of the gaze time was observed to be spent on ST reading,[10] while revision seems to be mainly concentrated on the TT. These results approximate the findings of Dragsted (2010), who measures 20% of gaze activities on the ST and Jensen (2009), who finds that “far the most attention is devoted to the TT.”
Whereas for professional translators half of the FUs overlap with text production (i.e., divided attention), this is only the case for roughly 1/3 of the student’s gaze pattern.[11] Notice also that the duration of alternating FUs is slightly longer than the duration of divided FUs (e.g., 1025 ms vs. 976 ms for 200 ms, professionals), but as the FU segmentation thresholds increase, this difference disappears.
Given that professionals need 84% of the student’s time to translate the texts (cf. Table 4), we suspect that the main factor that distinguishes student and professional translators is the latter’s ability to divide their attention on ST reading while producing TT. Divided attention also makes it possible for the translator to produce longer, uninterrupted PU. Translation Units are accordingly of different quality in experienced (professional) and less experienced (students) translators.
7. Conclusion
The paper investigates patterns of activity of student and professional translators. An English text of 160 words was translated by 12 professional and 12 student translators into Danish.[12] All keystrokes and eye movements – so-called user activity data (UAD) – were recorded using the Translog software (Jakobsen 1999). The goal was to determine the properties and shapes of Translation Units (TUs), i.e., entities of text which the translator focuses on at a given point in time and to determine differences and similarities in the shape and processing of these entities between the two groups.
Since the translators’ focus of attention cannot be directly observed in the UAD, we segment 1) the recorded keystroke data into units of text production (PUs) and 2) the source text fixations into fixation units (FUs). The UAD of these two modalities can be segmented in many different ways. We seek to find a segmentation which is likely to reflect units of attention and cognitive activity. The underlying assumption is that – if properly chosen – the properties of the generated FUs and PUs reflect entities of coherent cognitive activities and thus indicate boundaries of the hidden TUs. The progression of FUs and PUs would then reveal the progression of the translator’s focus of attention during her translation.
Various thresholds of maximal delay between two successive keystrokes are explored to group sequences of keystrokes into linguistically and cognitively intelligible PUs. PUs are considered intelligible if their boundaries coincide with word boundaries. Our investigation shows that pauses in writing activity of approximately 1000 ms length produce the highest percentage of intelligible segments. This lapse of time can thus be considered to indicate a shift of attention to another TU. However, only approximately 50% of the PUs coincide with our criteria of intelligibility, while more than 40% either end or begin in the middle of a word. We also note that these kinds of segments are rather long, on average 17.6 and 12.5 characters for experienced and student translators respectively, where some PUs can have more than 150 characters and include more than one sentence. PUs represent, thus, a rather rough approximation of TUs.
Another set of segmentation thresholds is used to group successive source text (ST) fixations into fixation units (FUs). While the choice of the PU segmentation threshold has a great impact on the properties of the segmented PUs, we find that this is not so for different FU segmentation thresholds. The properties, shapes and number of FUs do not depend as much on the segmentation threshold as the PUs do.
The gaze can, in principle, freely float over the ST or between the source and the target text regardless of whether the translator produces text at the same time in the target window or not. We therefore distinguish between divided FUs, in which keystrokes are observed while the translator is reading a ST segment, and alternating FUs, in which no keystrokes occur in parallel. We find in our data that experienced professional translators are better able to divide attention between ST reading and TT production, while students operate more in alternating mode. This finding seems to indicate that experienced (professional) and less experienced (students) translators process translation in quite different ways, as is also suggested in translation process literature (e.g., Göpferich 2007).
The segmentation of the reading and writing activities and their properties allows us to differentiate behavior of student and professional translators. Our findings are summarised as follows:
The number of PUs strongly correlates with translation time: the longer the translation time, the more the translation is fragmented into segments (Figure 6).
Professional translators are better able to process ST reading and TT production in parallel; they show more patterns of divided FU than do students (Figure 8).
Student translators process more in an alternating fashion; they show more sequential reading and text production patterns than professionals (Figure 7).
Alternating attention is strongly correlated with translation time: the more the translator sequentially reads ST and produces TT, the more time will be needed for translation (Figure 7).
Professional translators produce translations quicker than students (Table 4).
Professional translators produce longer PUs than students in terms of time, as well as in terms of characters (Table 5).
Professional and student translators type approximately at the same speed within PUs (Table 5).
Longer PUs coincide better with word boundaries than shorter PUs (Table 6).
PUs do not necessarily coincide with word boundaries (Table 6).
Only a small percentage of PUs coincide with single AUs (Figure 5).
It should be stressed that our results are based on a small translation corpus of 160 words from English into Danish, and the findings are necessarily biased towards the working style and experiences of our translators. The results indicate, however, that translators process maximal segments which seem to correspond to capacity and experience (professional and students) of the translator rather than a minimal unit or a “translation atom,” as frequently referred to in the literature. We also find that the way in which translations are processed seems to be quite different in both groups. In a further study we intend to investigate properties of these segments in more depth so as to produce an inventory of cognitive operations associated with each TU.
Parties annexes
Appendix
Source Text
Killer nurse receives four life sentences
Hospital Nurse Colin Norris was imprisoned for life today for the killing of four of his patients. 32 year old Norris from Glasgow killed the four women in 2002 by giving them large amounts of sleeping medicine. Yesterday, he was found guilty of four counts of murder following a long trial. He was given four life sentences, one for each of the killings. He will have to serve at least 30 years. Police officer Chris Gregg said that Norris had been acting strangely around the hospital. Only the awareness of other hospital staff put a stop to him and to the killings. The police have learned that the motive for the killings was that Norris disliked working with old people. All of his victims were old weak women with heart problems. All of them could be considered a burden to hospital staff.
Source:The Independant, 4 March 2008
Notes
-
[1]
The software can be downloaded from www.translog.dk, visited on 24 August 2011.
-
[2]
The Translog Editor has the same basic editing functions as Microsoft Word and should be immediately understandable for any contemporary translator.
-
[3]
At the time of the experiments, GWM was not able to compute and map fixations on the emerging target text words in the lower part of the screen.
-
[4]
The entire ST of 160 words (including punctuation marks) is reproduced in the Appendix.
-
[5]
At least two successive fixations within a time limit are required for a FU.
-
[6]
This deletion is visible in the progression graph in Figure 1, around sec. 45.
-
[7]
The dot “ . “ is a wildcard and stands for any character, in this case “A” or “U.”
-
[8]
Deletions are shown in square brackets. The notation “[ger]” would mean that first ger was produced (including a blank space) and then deleted.
-
[9]
Note that here is only measured the lapse of time between 2 or more keystrokes inside a PU, Inter-PU pauses are not taken into account.
-
[10]
It is unclear where the remaining 20% of gaze time was spent, since our data only indicates ST reading time.
-
[11]
These numbers seem to diverge from those reported in Jensen (2009: 232) due to the way “parallel” and “serial” attention is computed: for him the entire time of parallel attention was 8 per cent for professional translators and 5 per cent for students.” To approximate his numbers, we would have to calculate 50% and 30% from the 19% ST gaze time, which brings us to 9.5% and 5.7% respectively for professional and student translators.
-
[12]
The ST is reproduced in the Appendix.
Bibliography
- Alves, Fabio and Vale, Daniel Couto (2009): Probing the Unit of Translation in time: aspects of the design and development of a web application for storing, annotating and querying translation process data. Across Language and Cultures. 10(2):251-273.
- Anderson, John R. (2000): Cognitive Psychology and its Implications. New York: Worth.
- Bennett, Paul (1994): The Translation Unit in Human and Machine. Babel. 40(1):12-20.
- Carl, Michael (2009): Triangulating product and process data: quantifying alignment units with keystroke data. Copenhagen Studies in Language. 38:225-247.
- Carl, Michael and Buch-Kromann, Matthias (2010): Correlating Translation Product and Translation Process Data of Professional and Student Translators. In: François Yvon et Viggo Hansen, eds. Proceedings of the 14th Annual Conference of the European Association for Machine Translation (EAMT 2010, Saint-Raphaël, 27-28 May 2010). Visited on 24 August 2011, http://www.mt-archive.info/EAMT-2010-TOC.htm.
- Carl, Michael and Jakobsen, Arnt Lykke (2010): Towards statistical modelling of translators’ activity data. International Journal of Speech Technology. 12(4):125-138.
- Dagan, Ido, Church, Kenneth. W. and Gale, William A. (1993): Robust bilingual word alignment for machine aided translation. In: Proceedings of theWorkshop On Very Large Corpora: Academic And Industrial Perspectives (Columbus, 22 June 1993), 1-8. Visited on 24 August 2011, http://aclweb.org/anthology-new/W/W93/W93-0300.pdf.
- Dragsted, Barbara (2010): Coordination of reading and writing processes in translation: An eye on uncharted territory. In: Gregory M. Shreve and Erik Angelone, eds. Translation and Cognition. Amsterdam: John Benjamins, 41-62.
- Dragsted, Barbara and Hansen, Inge G. (2008): Comprehension and production in translation: a pilot study on segmentation and the coordination of reading and writing processes. Copenhagen Studies in Language. 36:9-12.
- Göpferich, Susanne (2007): Translationsprozessforschung. Tübingen: Gunter Narr.
- Jakobsen, Arnt Lykke (1999): Logging target text production with Translog. Copenhagen Studies in Language. 24:9-20.
- Jensen, Cristian (2008): Assessing eye-tracking accuracy in translation studies. Copenhagen Studies in Language. 36:157-174.
- Jensen, Kristian T. H. (2009): Distribution of attention between source text and target text during translation. In: Sharon O’Brien, ed. Continuum studies in translation – Cognitive exploration of translation. London: Continuum International Publishing Group, 215-237.
- Just, Marcel Adam and Carpenter, Patricia A. (1980): A theory of reading: from eye fixations to comprehension. Psychological Review. 87(4):329-354.
- Kondo, Fumiko (2007): Translation Units in Japanese-English Corpora: The Case of Frequent Nouns. In: Proceedings from Corpus Linguistics Conference Series (Birmingham, 27-30 July 2007). Article 203, 15 pp. Visited on 24 August 2011, http://www.birmingham.ac.uk/research/activity/corpus/publications/conference-archives/2007-birmingham.aspx.
- Kromann, Matthias (2003): The Danish dependency treebank and the DTAG treebank tool. In: Joakim Nivre and Erhard Hinrichs, eds. Proceedings of the Second Workshop on Treebanks and Linguistic Theories. Växjö: Växjö University Press, 217-220.
- Malmkjaer, Kirsten (2006): Translation Units. In: Keith Brown, Anne H. Anderson, Laurie Bauer, et al., eds. Encyclopaedia of Language and Linguistics. London: Elsevier, 92.
- Perrin, Daniel (2003): Progression Analysis (PA): Investigating Writing Strategies at the Workplace. Pragmatics. 35:907-921.
- Radach, Ralph, Kennedy, Alan and Rayner, Keith (2004): Eye Movements and Information Processing During Reading. Hove: Psychology Press.
- Ruiz, Carmen, Paredes, Natalia, Macizo, Pedro, et al. (2008): Activation of lexical and syntactic target language properties in translation. Acta Psychologica. 128(3):490-500.
- Sager, Juan C. (1993): Language Engineering and Translation. Consequences of Automation. Amsterdam: John Benjamins.
- Sharmin, Selina, Špakov, Oleg, Räihä, Kari, et al. (2008): Where on the screen do translation students look? Copenhagen Studies in Language. 36:30-51.
- Špakov, Oleg (2008): GazetoWord Mapping (GWM) tool, COM interface description, Version 1.2.3.60. Technical report, University of Tampere.
- Vinay, Jean-Paul and Darbelnet, Jean (1958): Stylistique comparée du français et de l’anglais. Paris: Didier.
Liste des figures
Figure 1
Translation progression graph of a professional translator (P13)
Figure 2
Translation progression graph of a student translator (S5)
Figure 3
Manually aligned AUs of the product data of translator P13
9 ST words are translated into 8 TT words, in 6 AUs.
Figure 4
First 30 seconds (secs. 10-40) of the progression translation graph of a professional translator (P13)
The graph is an expansion of the first 30 s of Figure 1 and shows the translation progression for the production of the 6 AUs from Figure 3, including several PU and FU segmentation patterns.
Figure 5
Number (vertical) and length (horizontal) of PUs in terms of AUs covered
Figure 6
Translation time (horizontal) and number of PUs (vertical) for students and professional translators and different segmentation thresholds
Figure 7
Translation time (horizontal) and number of alternating FUs (vertical) for students and professional translators for the 200 ms FU segmentation threshold
Figure 8
Translation time (horizontal) and number of divided FUs (vertical) for students and professional translators (200 ms segmentation threshold)
Liste des tableaux
Table 1
Properties of PU as generated with 400 ms segmentation
Table 2
Segmentation 800 ms (above) and 1500 ms (below) of the same 36 keystrokes from Table 1
The notation “s(s)” and “[s]” are equivalent, meaning typing and deletion of the bracketed expression.
Table 3
Number and properties of FU and PU for translator P13, generated under various segmentation thresholds
Table 4
Translation time (T-time) and number of PUs for different kinds of segmentation thresholds for the 12 professional and 12 student translators
Table 5
Average duration and length of PUs with various segmentation thresholds, and average typing speed for professional and student translators
Table 6
Number and properties of PUs for different segmentation thresholds
SASA: PUs start and end with a word separator and an AU boundary; S.S.: PUs start and end with a word separator; WUWU: PUs start and end in the middle of a word
Table 7
Divided and alternating FU for professional and student translators for different kinds of segmentation