

Abstracts
Abstract
This paper proposes a model for investigating explicitation, implicitation, and explicitness in translated texts. The paper highlights the need to distinguish clearly between explicitation and other kinds of translation shifts. Specifically, when comparing target text (TT) renderings with the corresponding source text (ST), the model does not assume correspondence between shifts (and non-shifts) in ideational content and explicitation status. Nor does it assume correspondence between the overall explicitation status of renderings and the explicitness of the TT as a whole from the perspective of the relevant register in the target language (TL). The model draws on systemic functional linguistics to develop procedures for a three-phase analysis of these different explicitation-related phenomena. The parameters of traceability, realisational congruency and delicacy are applied to determine explicitation status, seen as arising from choices made by the translator within the systemic potential of the TL. Explicitness is determined from the perspective of registerial instantiation by comparing frequencies of different types of rendering with those found in a comparable corpus of TL non-translations. A case study, in which the model is applied to an English-to-Arabic translation of manner of motion verbs in a literary genre, demonstrates how each phase yields new insights, from a different perspective, while providing input for comparative analysis of the choices available in the two language systems with regard to the linguistic feature of interest.
Keywords:
- explicitation,
- implicitation,
- systemic functional linguistics,
- manner of motion
Résumé
Cet article propose un modèle pour explorer les notions d’explicitation, d’implication et d’explicite dans les textes traduits. L’article souligne la nécessité de distinguer clairement entre l’explicitation et d’autres types de changements en traduction. En particulier, lorsqu’on compare le texte cible (TC) avec le texte source correspondant (TS), le modèle ne présume pas de correspondance entre les changements (et non-changements) dans le contenu référentiel et le statut d’explicitation. Il ne présume pas non plus une correspondance entre le statut d’explicitation des interprétations et la nature explicite du TC du point de vue des lecteurs du langage cible. Le modèle s’appuie sur la linguistique systémique fonctionnelle pour analyser en trois phases ces différents phénomènes liés à l’explicitation. Les paramètres de traçabilité, de congruence dans l’actualisation et de finesse sont appliqués pour déterminer le statut d’explicitation, vu comme découlant des choix faits par le traducteur dans le potentiel systémique de la langue cible (LC). La nature explicite est déterminée du point de vue de différents registres en comparant les fréquences de différents types d’interprétations avec celles trouvées dans un corpus comparable de textes originaux en LC. Une étude de cas appliquant le modèle à une traduction anglais-arabe de verbes de mouvement dans un genre littéraire montrera comment chaque phase révèle de nouveaux éléments, sous un angle différent, et fournit également des éléments pour une analyse comparative des choix disponibles dans le système linguistique de chaque langue en ce qui concerne le trait linguistique en question.
Mots-clés :
- explicitation,
- implication,
- linguistique systémique fonctionnelle,
- manière de mouvement
Resumen
Este trabajo propone un modelo para la investigación de la explicitación, la implicitación y la explicitud en textos traducidos. El trabajo destaca la necesidad de distinguir claramente entre explicitación y otro tipo de transformaciones en la traducción. Específicamente, cuando se comparan las traducciones en el texto meta (TM) con el texto fuente (TF) correspondiente, el modelo no presupone correspondencias entre la presencia (y la ausencia) de transformaciones en contenido ideativo y el estatus de explicitación. Tampoco presupone correspondencia entre el estatus general de explicitación de las traducciones y el carácter explícito del TM en su conjunto desde la perspectiva de los lectores en lengua meta (LM). El modelo se basa en la lingüística sistémico-funcional para desarrollar procedimientos para un análisis de tres fases de estos diferentes fenómenos relacionados a la explicitación. Se aplican los parámetros de rastreabilidad, congruencia de realización y refinamiento para determinar el estatus de explicitación, que se concibe como selecciones hechas por el traductor en el potencial sistémico de la LM. El carácter explícito se determina desde la perspectiva de la instanciación de registro mediante la comparación de frecuencias de diferentes tipos de traducciones con las encontradas en un corpus comparable de no traducciones en LM. Un estudio de caso que aplica el modelo a una traducción del inglés al árabe de verbos de modo de movimiento en un género literario demuestra cómo cada fase aporta nuevas percepciones, desde una perspectiva diferente, a la vez que ofrece datos para el análisis comparativo de las selecciones disponibles en los dos sistemas lingüísticos en relación con el rasgo lingüístico de interés.
Palabras clave:
- explicitación,
- implicitación,
- lingüística sistémico-funcional,
- modo de movimiento
Article body
1. Introduction and rationale
This paper develops a model for investigating explicitation-related phenomena (namely explicitation, implicitation, and explicitness) in translated language. It illustrates the application of this model using an English to Arabic translation of manner of motion verbs as a case study from the literary genre.
Early approaches to explicitation and implicitation were predominantly linguistic, focusing on types of equivalence, a paradigm that views the ST-TT relationship mainly in terms of linguistic encodings. According to Vinay and Darbelnet (1958/1995: 342-344), explicitation may be defined as a “stylistic translation technique which consists of making explicit in the target language what remains implicit in the source language because it is apparent from either the context or the situation.” Similarly, implicitation is a “technique which consists of making what is explicit in the source language implicit in the target language, relying on the context or the situation for conveying the meaning.” Subsequent studies adopt broadly similar definitions.
More recent studies have adopted a descriptive approach that looks at translations as “facts of [the] target culture … as opposed to the source-culture context that is predominant in the equivalence paradigm” (Pym 2010: 65). From this perspective, translation shifts are not viewed as mistranslations or as a means to cope with linguistic differences, but as features of translated language. This study adopts this approach, building on previous research and drawing on insights from systemic functional linguistics (SFL).
SFL views language as meaning potential, with complex systems of choices, which are all meaningful (see Halliday 1971, 1978). In this sense, for SFL, “[t]ranslation (translating/interpreting) is meaning-making activity” (Halliday 1992: 15), while shifts in translation are the result of choices made by the translator to express meaning in a particular way. The theory provides precise analytical tools for the description of linguistic features at all levels, from elements in the clause up to the level of the text and how the whole text relates to the wider language system, register, and culture. At the clause level, SFL views clauses as conflating several metafunctions. The ideational metafunction comprises an experiential mode related to the content or ideas (realised in the configuration of the clause which comprises Participants, Process, and Circumstances) and a logical mode related to relations between ideas (realised through logico-semantic relations). The interpersonal metafunction is concerned with the relations between the addresser and addressee, enacted in grammar by the systems of mood (such as indicative or imperative), and modality (for example, probability, usuality, temporality). Finally, the textual metafunction is concerned with the distribution of information in the clause and is realised by the theme and information systems (Halliday and Matthiessen 2014).
This rich architecture provides the basis for a systematic investigation of the actual choices made by a translator and those that could have been made, but were discarded during translation. It also allows those choices to be contextualised with respect to register. In brief, the model proposed in this paper describes translated language from the SFL perspective, assuming that a translation involves a relation, not only between the two texts, but also between two language systems as well as between text and register. Accordingly, the model makes an open distinction between explicitation/implicitation and explicitness. Explicitation/implicitation is defined here as a shift that takes place in the translation process between a ST element and its counterpart in the TT. A TT rendering is regarded as an explicitation (implicitation) if it realises contextually recoverable meanings of its ST counterpart in more (less) explicit lexicogrammar, in other words, by including more (less), traceable content or increasing (decreasing) congruency and/or delicacy (see the section below), provided that the TL can express the same meaning of the actual TT instance in less (more) explicit agnates.
On the other hand, explicitness is a relative feature of the translation product, and it can describe individual renderings as well as whole texts. Individually, it refers to how a certain realisation compares with other agnate realisations in terms of content, realisational congruency and/or delicacy. Thus, a TT instance that explicitates ST meanings (an explicitational shift) is said to be at a higher level of explicitness than its ST counterpart and other TL agnates. At the text level, explicitness is seen as a feature of the TT, either as a whole or with respect to a specific linguistic feature (like cohesion, cause-effect relations, manner of motion). Thus, we speak of a degree or level of explicitness that results from the entirety of shifts (explicitations, implicitations, and non-explicitations), which together contribute to a TT that is more/less explicit than the ST and/or comparable non-translations in the TL.
The distinction between explicitations/implicitations (as shifts) and explicitness (as a feature) is important because the totality of explicitations, implicitations and non-explicitations (that is, shifts in the explicitation status of individual renderings) does not provide a direct measure of the degree of explicitness of the TT in its entirety. As further explained below, this can only be determined in relation to the registerial conventions of the TL and the expectations of targeted readers. Thus, in order to gain a complete picture of both explicitation and the degree of explicitness in a translated text, it needs to be evaluated in relation to both the corresponding ST and respective TL non-translations. What is needed to this end is a theory of language that enables (1) linguistic features of the ST and TT to be related to each other, (2) the different choices made in the translation to be explained in a systematic manner, and (3) these choices to be contextualised with respect to register. SFL fulfils these requirements.
While building on this solid theoretical platform, the model contains several new and distinctive features, in addition to the above distinction between explicitation/implicitation and explicitness. It fills gaps in previous studies, both by according equal attention to implicitation, alongside explicitation, and by shedding light on how the phenomena are manifested in a language (Arabic) where they have seldom been studied before.
A notable innovation of the model is that it incorporates realisational congruency and delicacy as parameters for analysis. In SFL, realisational congruency refers to the way that is most commonly used to realise a category of meaning. The semantic category of Figure[1] is congruently realised at the clause rank, and that of sequence (of figures) at the clause complex rank, while the lower-ranking semantic categories of Participant, Process, and Circumstance have their congruent realisations in nominal groups, verbal groups, as well as prepositional phrases and adverbs, respectively. However, other incongruent mappings are possible. For example, the realisation she died due to ignorance of the rules is incongruent because two figures (around the processes of dying and ignoring) are compacted in a single clause simplex. On the other hand, the clause complex she died because she didn’t know the rules is seen as a congruent realisation of the same sequence. Shifts down the cline of congruency (from the congruent realisation to incongruent realisations) typically involve loss of information or lead to ambiguity (see Halliday and Matthiessen 1999: 227-231).[2]
Delicacy relates to the order of systems from the general to the more specific, for example rendering walk as crawl. Furthermore, in SFL, lexical choices are regarded as more specific (Matthiessen 1991: 253), and thus more delicate (Halliday and Matthiessen 1999: 87) than grammatical ones. Thus, rendering due to as caused/resulted in leads to an increase in delicacy. The conjunction because can also be seen as more delicate than the preposition due to because the former has some explicit lexical traces that signal the logico-semantic relationship, namely cause.
Last, but certainly not least, the proposed model distinguishes between explicitation/ implicitation and increased/decreased information content, thus incorporating, for the first time to my knowledge, a systematic analysis of the relation between content shifts and their status in terms of explicitation. To briefly illustrate (see also Section 2.1), a TT rendering that does not change the information content of its ST counterpart might in fact be implicitational if it omits contextual information required by TL language readers.
The next section presents a detailed description of the model and the procedures for its application. This is followed by an illustration of the application of the model to a case study of the translation of manner of motion verbs in the literary genre. A concluding section assesses the effectiveness of the model and summarizes the results of the case study, as well as noting limitations of both the model and the case study.
2. The proposed model
The proposed model is designed to be applied to a specific linguistic feature of interest (for instance, motion verbs), not the translation as a whole. The following presentation focuses on explicitation-related phenomena with reference to the ideational metafunction, but the model can be used or extended to investigate other types of phenomena and meanings.
As seen below, the model is implemented in three phases. The initial phase (inter-textual realisation) focuses on the ideational content of individual renderings of the selected language feature in the TT and classifies them as [+content], [–content] or [=content] shifts, in comparison with the ST. The second phase (inter-textual actualisation), which can be conducted in parallel with the previous one, determines the explicitation status of the same individual renderings by considering the choices available to the translator, particularly with regard to realisational congruency and delicacy. It is assumed that there is no automatic correspondence between the content shifts identified in Phase 1 and the explicitation status determined in Phase 2. The third and final phase (registerial instantiation) is a macro-level, quantitative analysis that assesses the extent to which the TT is more or less explicit (with respect to the specific linguistic feature of interest) than is typical in TL non-translations from the same register. Analyses in these three phases are both manual and corpus-based, as will be seen below.
2.1. Phase 1: identifying and classifying relevant renderings in terms of content and traceability
Phase 1 is referred to as inter-textual realisation because it is concerned with the lexicogrammatical realisation of the content of ST renderings in the TT. The ST and TT are first explored for manifestations of a certain linguistic feature. If, for instance, the focus is on a certain category of verbs, such as motion or reporting, a list is created of all such verbs in the SL based on dictionaries and available studies. The ST is then searched for these verbs. This step can also start with the TL and TT, although with potential limitations. The next step is to identify relevant TT renderings and classify them according to whether there is a shift in the ideational content of the investigated elements. Renderings are classified in terms of how much of the content of the study object is conveyed in the TT. Three types of renderings are suggested: [=content], [+content], or [–content], where [content] refers to the ideational content of the unit being investigated.
Identified content shifts and non-shifts are also considered in terms of context traceability. Context traceability is used to decide whether a rendering is inter-textually recoverable, that is, if the content added or omitted can be traced back to the context of the relevant text (the ST for [=content] and [+content] renderings, or the TT for [–content] renderings). This provides the basis for the following more fine-grained categorization of content shifts and non-shifts. Examples on these categories are given in Section 2.2 below.
Insertions and additions are both [+content] renderings, but only insertions can be traced back to the context of the ST. In other words, the inserted content in the rendering can be retrieved from contextual information elsewhere in the ST. That is, insertions are inter-textually recoverable and provide no additional information. They are [+content] renderings either due to increased delicacy compared to the ST or because of the insertion of lexicogrammatical elements. By contrast, additions are not inter-textually recoverable and increase the information content of the TT relative to the ST.
Similarly, deletions and omissions are both [–content] renderings and refer to meanings that are lexicogrammatically realised in the ST’s investigated unit, but only deletions are inter-textually recoverable from contextual information provided elsewhere in the TT. They are [–content] renderings either due to decreased delicacy compared to the ST or because of the deletion or omission of lexicogrammatical elements. By contrast, omissions are not inter-textually recoverable and reduce the information content of the TT relative to the ST.
Unpacking refers to the distribution of the ideational content of a compact linguistic unit over more units) and packing, to the repackaging of more than one unit into one compact unit. They are both [=content] renderings. They are both inter-textually recoverable shifts because in either case the content of the actual TT instance derives from the content of its ST counterpart.
Similarly, direct renderings, instances where the content and form of the investigated unit are maintained, and rewordings, instances where the content of the investigated unit is maintained through a different form (other than un/packing), are both inter-textually recoverable [=content] renderings.
With all [=content] renderings, except for those involving cultural or pragmatic meanings (as these could invoke the context in its wider concept as outside of language), traceability is limited to the unit under investigation in the ST and its counterpart in the TT. However, with [+content] and [–content] shifts, tracing a shift back is not always a straightforward endeavour, especially when dealing with lexical features. Frequently, locating a referent requires careful consideration of text beyond the clause. Such reference could be found in co-text descriptions relating, for example, to the physical and/or psychological state of the Actor (for example, a person with a foot or leg injury will limp rather than walk), or the location or ground where the action takes place (for instance, one will more probably trot than walk on hot sand). A referent could also be attributed to extra-linguistic contextual variables such as common knowledge or the author’s/translator’s assumption about the readership. These two latter variables are inherently subjective and therefore difficult to operationalise. Therefore, in the application of the model in Section 3, I only rely on the linguistic context to decide whether a shift is traceable or not. To this end, I am following research in cognitive linguistics (Firbas 1995, among others), which sets a referential distance of up to seven clauses, beyond which an item is considered to be no longer recoverable.
In summary, the output of Phase 1 is the classification of each translated rendering of the linguistic feature of interest, from the perspective of ideational content. Quantitative analysis of the results of this phase could provide valuable insights into typological commonalities and differences between the languages involved and how translators deal with units that are not lexicalised or grammaticalised in the TL. The inclusion of non-shifts and clearly defined subcategories of both shifts and non-shifts mean that this stage captures all the relevant information (and no irrelevant information) needed for the explicitation analysis in Phase 2.
2.2. Phase 2: classifying renderings in terms of explicitation status
The micro-level analysis in Phase 1 identifies potential instances of explicitation and implicitation and examines them against their ST counterparts in terms of realisation, content and traceability. The analysis in Phase 2 leads to the determination of the actual explicitation status of renderings in the TT as compared to their ST counterparts. A rendering can be classified as explicitation, implicitation, or as explicitationally/implicitationally neutral (hereafter non-explicitation). As in Phase 1, the unit of analysis at this level is the ST clause, or some element of the clause, and its translation. Phase 2 undertakes a reanalysis of all renderings considered in Phase 1, with the exception of those identified as additions or omissions, since the addition/omission of informational content means that these renderings are not, strictly speaking translations, and therefore not amenable to explicitation analysis. However, compared to Phase 1, Phase 2 involves a radical shift in perspective, in which a rendering is seen as a choice made by the translator from among those available within the systemic potential of the target language. Phase 2 thus considers each TT rendering, both in comparison with its ST counterpart and with other alternative options, available to the translator in the TL. The two parameters principally considered in this analysis are realisational congruency and delicacy.
In general terms, a shift in realisation from the incongruent to the congruent, and from the less delicate to the more delicate, results in an explicitation, and a shift in the other direction results in an implicitation. These are not hard and fast rules, though. For example, unpacking a clause simplex (such as She died due to ignorance of the rules) into a pair of juxtaposed clauses (like She died. She did not know the rules) involves a shift up the cline of congruency, but it also involves a move down the cline of delicacy (the deletion of the conjunction), which renders the translation an implicitation rather than an explicitation.
As indicated in the definitions of explicitation and implicitation (see Section 1), another relevant factor in determining the explicitation status of an individual instance in the TT is the availability of alternative agnates in the TL. This is because explicitness is a relative concept that might be perceived differently in different systems. In general terms, a TT rendering can only be regarded realisationally as more explicit (that is, an explicitation) than the actual ST counterpart if the TL allows for at least one less explicit realisation. Similarly, implicitation requires the translator to have the option of selecting at least one more explicit realisation. In practice, given the capacity of language to express almost any meaning in more than one realisation, there are nearly always more or less explicit alternatives available in the TL.[3] In the remainder of this paper, the availability of alternative agnates in the TL is assumed and (for reasons of space) there is no further discussion of this topic.
2.2.1. Explicitation status of [=content] shifts
All [=content] renderings, except for those involving cultural or pragmatic meanings, are inter-textually recoverable because the content of the TT’s actual instance derives from the content of its ST counterpart. This, however, does not mean that all [=content] renderings are non-explicitational, as explained below.
The first type of manifestation, direct renderings, can straightforwardly be classified as non-explicitational because no shift in content or realisation, and thus in congruency and/or delicacy, has taken place. For example, the Arabic غادر الغرفة بسرعة (ghādara al-ghurfata bi-surʿa)[4] is a direct rendering of he left the room in a hurry.
Unpacking shifts, generally speaking, are explicitational due to the move up the cline of realisational congruency, whereas packing shifts are implicitational due to the move down the cline of realisational congruency. For example, rendering clamber into climb with effort is a case of unpacking that involves a move up the cline of congruency. The Process clamber functions both as a Process and as an implicit Circumstance. This double functionality of an element in the semantics of the clause results in an incongruent clause configuration. Based on this, the unpacked variant in the translation is more explicit than its English counterpart.
Finally, [=content] shifts manifested by rewording could be explicitational/implicitational or non-explicitational. For example, translating the Arabic لذلك (li-dhālika) [hence] into English as it is for this reason is an [=content] rendering because both units function as cause-effect Relators. In terms of explicitation status, this is non-explicitational, because both Relators serve as cohesive/textual conjunctives (for example: therefore, however). However, two renderings which are equivalent in terms of congruency may still differ in terms of their degree of explicitness. For instance, Othman (2019) argues that a cohesive sequence of two clauses is textually more explicit than a clause complex, even where they construe the same causal relation, as the below examples show.
Two clauses: The traditional approach ignores the realities of history and material development. Consequently, it has consistently failed.
Clause complex: Since it ignores the realities of history and material development, the traditional approach has consistently failed).[5]
If this line of argument is accepted, translating a clause complex with the Relator realised as something like so/for into a cohesive sequence of clauses with the causal relation indicated using a conjunctive, along the lines of consequently, would be explicitational. A rewording in the opposite direction would be implicitational. See Othman (2019: 79-82) for other manifestations of rewording.
2.2.2. Explicitation status of [+content] shifts
As explained above, insertions, but not additions, are amenable to explicitation analysis. All insertions, assuming alternative agnates are available, make the TT more explicit. Insertions are manifested as (1) the presence of new explicitly stated elements or (2) use of a more specific item. For example, rendering crawl into يحبو متسللا ببطء (yaḥbū mutasallilan bibiṭʾin) [crawl, sneaking slowly] inserts new elements into the translation that create a move up the cline of congruency as well as the cline of delicacy. The unpacking here is manifested by spelling the rate of motion – ببطء (bibiṭʾin) [slowly] – outside the verb. The insertion involves explicitated manner – متسللا (mutasallilan) [sneaking] – taken from the co-text (in other words, it is textually recoverable) and the rendering is thus a case of explicitation.
2.2.3. Explicitation status of [–content] shifts
As explained above, deletions, but not omissions are amenable to explicitation analysis. All deletions, assuming alternative agnates are available, make the TT less explicit. Deletions are manifested by (1) leaving out ST elements – such as dropping a conjunctive when it can be inferred from the ST – or (2) opting for a less specific item – for example, translating the high-delicacy trotted as سار (sāra) [walked], a verb that is less specific in terms of manner as it does not denote the pace of motion.
As noted above, the principal innovation of Phase 2, compared to other approaches, is that it considers all inter-textually recoverable renderings, not only shifts in content, but also non-shifts. As is illustrated above, equivalence in content does not always mean non-explicitation, and a careful analysis of the parameters of congruency and delicacy is required to determine the explicitation status of [=content] renderings. In the case of content shifts, while it is true that all inter-textually recoverable [+content] and [–content] shifts are explicitational and implicitational, respectively, an analysis of the congruency and delicacy provides new insights into how these explicitational effects are realised.
In summary, the output of Phase 2 is the classification of each translated rendering of the linguistic feature of interest, from the perspective of explicitation status. In addition, a comparative analysis of Phases 1 and 2 would provide insights into the translation process (for example, how translators deal with un-lexicalised entities in the TL) as well as into realisation patterns of the language feature of interest in both languages involved.
2.3. Phase 3: evaluating the TT against register-related non-translations in the TL
Phase 3 of the model assesses the TT in terms of registerial instantiation and reassesses the overall effect of the translational renderings on the TT’s level of explicitness, understood as the extent to which the inter-textual shifts/non-shifts identified in Phases 1 and 2 are consistent with established patterns of instantiation in the TL and, therefore, with the targeted readership’s expectations. In this sense, explicitness (following Pápai 2004) can be considered a feature of the TT as compared to non-translations in the TL and/or a particular TL register. To elucidate this perspective, Phase 3 of the model examines the TT renderings collectively, in groups or categories, rather than individually as in Phases 1 and 2. Moreover, it compares the TT, not with the ST, but rather against TL patterns or preferences, identified by investigating a corpus of non-translations.
Comparison of the TT with authentic TL texts could consider (1) patterns representing the potential of the language system in its entirety, and (2) patterns that are specific to a particular register or genre. The conformity of translational instances and text features to these patterns is referred to as instantiation. Because register is always involved in any translation, the model focuses on the parameter of registerial instantiation. The underlying idea is that certain choices in the system are more appropriate than others for a particular situational context, or register. Therefore, for example, nominalised constructions in a scientific text in English can be described as registerially instantiated. The registerial instantiation of TT renderings also determines the degree of explicitness of the TT in comparison to register-related norms in the TL, that is, the level of explicitness that the readers expect.
The intra-lingual macro-level analysis in this phase is basically quantitative, based on corpus-based investigations that reveal how the TL register manifests a division of labour between or among different lexicogrammatical realisations of selected linguistic features, for instance, whether literary texts in Arabic favour the use of manner of motion verbs or no-manner verbs. The analysis compares frequencies of different features of TT realisations, which were obtained in the previous phases, with those in the corresponding corpus of non-translations. Differences between the TT and the corpus, in terms of the division of labour between or among alternative realisations of the same meaning, can then be analysed to determine whether that TT is more or less explicit in this respect than is typical in the respective register. Statistical tests are conducted in order to determine whether these differences are significant.
In summary, the quantitative analysis conducted in Phase 3 provides an indication of the overall level of explicitness of the translated text, measured as the degree of registerial instantiation of the linguistic feature of interest, as well as yielding interesting information about registerial patterns of instantiation in the languages involved. A comparative analysis of Phase 3 with Phases 1 and 2 demonstrates the extent to which ideational content, explicitation and explicitness do or do not coincide in the TT, elucidating the challenges faced by the translator and how he or she responds to those challenges.
3. Case study: manner of motion verbs
A case study was conducted to demonstrate the potential of the proposed model for investigating explicitation-related phenomena in English-into-Arabic translated literary texts with reference to manner of motion construal. The selection of manner of motion verbs as the linguistic feature for investigation was motivated by a claim in cognitive linguistics about languages and registers being different in how they lexicalise manner (Talmy 2000) and in the level of attention their speakers pay to manner in describing motion events (Slobin 2004).
Motion verbs in general construe the experience of moving in space. For example, they can provide information on path (to ascend) or manner of motion (to crawl), or both (to climb). Others denote neutral motion (such as to move) (Talmy 2000). Manner of motion verbs (henceforth, manner verbs) can be further classed into low-manner and high-manner. Low-manner verbs are high-frequency, everyday verbs that describe common or usual types of motion (Slobin 2004), such as to walk, to run, to jump, to swim, and to fly. These everyday verbs are hypernyms of more specific high-manner verbs. For example, to march, to amble, to stagger, and to stump denote different ways of walking; they are all hyponyms of to walk that construe a walking movement in a more expressive lexicogrammatical way. High-manner verbs also differ in expressiveness. For example, to worm and to crawl are both high-manner verbs that denote different ways of walking; however, the verb to worm, in the sense of “walk with difficulty by crawling or wriggling”[6] is more expressive than the verb to crawl, since the latter does not express the aspect of difficulty or the wriggling manner of motion that the former construes.
The data for the study were taken from William Golding’s Lord of the Flies (1954/1996)[7] and an Arabic translation (Golding 1954/1988, translated by Mheidli)[8] of the novel. The novel was chosen because it includes a large number of verbs that conflate manner.
3.1. Phases 1 and 2: inter-textual realisation and actualisation
3.1.1. Methods
The first two phases of the model were implemented as follows. I first created a list of 268 English manner verbs (see Othman 2019: 285) by referring to WordNet[9] and to the existing literature (Levin and Rappaport Hovav 1992, among others). The list was restricted to verbs that construe self-initiated locomotion on land, resulting in change of location for a human Actor. The software AntConc[10] was used to search the ST for the listed verbs. Since no digital version of the TT was available, relevant ST instances were manually paired with their Arabic renderings. Out of the 268 verbs searched for in the ST, 72 verbs were found. Of those 72 verbs, 38 are found only once in a sense that relates to self-initiated motion on land. Because of the low frequency of these verbs, the investigation in this phase focused on the remaining 34 verbs, whose tokens amount to a percentage of approximately 90% of the total. In total 263 renderings/tokens of these 34 verbs were considered in the analysis.
As a first step in the analysis, renderings were assigned to one of two categories: (1) ST verbs with no equivalent Arabic counterparts (henceforth zero-equivalent verbs); (2) ST verbs with equivalent Arabic counterparts (henceforth verbs with equivalents). In total 212 renderings were of verbs with equivalents, and 51 were of zero-equivalent verbs.
The first phase of the model compared the content of each individual TT rendering with its ST counterpart. Based on a prior analysis of possible manifestations of each category, for the linguistic feature under investigation,[11] each rendering was assigned to one of three categories, namely [=content], [–content], and [+content]. A total of 185 [=content], 72 [–content], and 6 [+content] renderings were identified.
In Phase 2, each of these renderings was then further classified as explicitational, implicitational or non-explicitational. As explained in Section 2.2, this stage of the analysis considers renderings as choices within the systemic potential of the TL, taking account of (1) context traceability (2) experiential congruency, and (3) delicacy. Results of this analysis, grouped by type of content shift and explicitation status are given below and summarised in Tables 1 and 2. For a fuller presentation and discussion of the methods and results, see Othman 2019.
3.1.2. Analysis: Phases 1 and 2
Table 1
Content shifts across verb categories
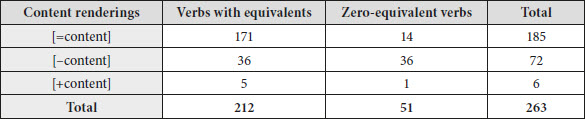
For reasons related to space, only a summary of the results of the first two phases could be provided here. As can be seen in Table 1, the category of [=content] renderings in both verb categories accounts for most of the TT instances (185 occurrences of the total 263 tokens). In part, this reflects the fact that equivalent Arabic counterparts are available for 19 of the 34 verbs investigated. However, it is also due in part to the very broad definition of [=content] renderings in this study to include any TT instance that has conveyed the same manner content through direct rendering, rewording, or packing/unpacking. The category of [–content] renderings accounts for 72 occurrences of the total 263 renderings. Unsurprisingly, the relative frequency of [–content] shifts was far higher in the renderings of zero-equivalent verbs (36, or 71% out of 51 tokens), compared to those with Arabic equivalent counterparts (36, or 17% out of 212 tokens). Three manifestations of [–content] shifts were observed: no-manner Arabic verbs, low or less expressive manner verbs, and no-motion realisations. Finally, [+content] shifts occurred very infrequently, accounting for only 6 of the total tokens.
Table 2
Explicitation status across verb categories

With respect to the relationship between the verb categories and the explicitation status, a chi-square test of independence, using the values shown in Table 2 above as a 2 × 4 contingency table, returned a result of X2 = 124.145 (p < 0.05). This means that there is a significant relation between the explicitation status and the verb category.
Across the two verb categories, there are more cases of implicitation than explicitation (20% and 8%, respectively). The lower percentage of explicitations could be attributed to a tendency on the part of the translator, where a direct equivalent is unavailable, to tone down rather than increase manner information. However, it is notable that in cases of implicitation across the two verb categories, the translator prefers to render manner verbs as less expressive manner verbs rather than into no-manner verbs or no-motion realisations.
Table 2 also shows that about one-third of all the shifts included under the category of [–content] could not be traced to their respective contexts and are thus regarded as cases of omissions, decreasing the text’s informativeness, rather than implicitations. On the other hand, [+content] shifts are all inter-textually recoverable and are thus explicitational. Again, the tendency to tone down manner information could be attributed to the translator’s style, but it could also be attributed to preferences, or norms relevant to the overall system of Arabic or the register of literary works. This is the concern of the third phase of the analysis (see next section), where these implicitational shifts, taken collectively, may eventuate as registerially instantiated (in other words, being in conformity with registerial conventions) and thus not contributing towards registerial implicitness.
3.2. Phase 3: registerial instantiation
The additional data for Phase 3 of the analysis was extracted from the International Corpus of Arabic[12], whose word count amounts to 65,000,000 words of written Modern Standard Arabic. The literary sub-corpus that was used has a total of 7,800,000 words comprising novels, short stories and plays published within the last 30 years. The corpus size might be too small to provide reliable data; however, as already mentioned, the main aim here is to demonstrate the model’s applicability.
3.2.1. Methods
Evaluating the TT renderings against register-related non-translations in the TL was achieved by comparing frequencies of the renderings in specific verb categories in the TT with the frequencies of alternative realisations of the same categories in the corpus. This was used as the basis for evaluating the registerial status of the renderings of the same category and its effect on the level of explicitness of the TT. To this end, I adopted the following procedure.
I first classified the 34 cited ST verbs into three main categories based on the basic type of motion, or motor pattern of motion that each verb encodes: run-verbs, jump-verbs and walk-verbs (Slobin 2005).
I then selected sample verbs or sub-categories from each group for analysis and found the Arabic equivalents of those verbs (from bilingual dictionaries). The selection of the ST verbs and their Arabic equivalents was based on specific manner details in addition to the frequency results from the previous phases. The Arabic verbs were then used in a first round of queries in order to find their frequencies in the corpus.
I undertook a second round of corpus queries to see how Arabic, specifically its literary register, embodies a division of labour between different mappings within selected categories of manner verbs. Further operationalisation procedures were used to determine the most probable TL alternatives for the manner verbs in each category. For example, if the manner in the Arabic verb can be encoded in a separate enhancing element derived from the verb itself, the intra-corpus comparison considered the verb itself and its derived forms, as with تسلل (tasallala) [sneak] and متسللا (mutasallilan) [sneakingly]. For further examples see Othman 2019.
A sampling frame was needed because the conducted queries returned a large number of hits. I used a research randomizer[13] to generate sets of 50 instances each, using a number range that covers the total corpus returns for each query. Then, I examined a number of sets, each time adding the total number of relevant instances and dividing by the number of sets until the last set added almost nothing to the average (see Sinclair 1999).
The results of the corpus queries for a certain verb and its most probable alternative(s), were tested (against the total number of words in the corpus) for significance using a chi-square test.[14] This provided insight into Arabic preferences for expressing manner of motion (such as expressing upward motion by means of manner verbs or no-manner verbs), which contributed to the registerial evaluation of the renderings cited in the TT. To this end, I compared the frequencies of the intra-corpus queries illustrated above and the frequencies of TT instances, by means of another chi-square test[15] (as in Table 3 below).
3.2.2. Analysis: Phase 3
Due to space limitations, here I illustrate the results by considering only two contrasting categories of renderings that occur frequently in the TT: non-explicitational renderings of verbs with equivalents and implicitational renderings of zero-equivalent verbs.
3.2.2.1. Verbs with equivalents: non-explicitations
The method adopted can be illustrated by considering the case of climbing motion. The walk-verb to climb conflates both manner and direction of motion. The ST instances of to climb were mostly rendered as تسلق (tasallaqa) [climb], in the sense of climbing up a tree or a wall, which requires the use of hands and feet/legs (Dawood 2002: 180-182). The alternative realisation queried in the corpus was صعد (ṣaʿada) [ascend], a near-synonymous no-manner of motion verb in Arabic that can replace تسلق (tasallaqa) in almost all contexts and with the same collocates. The verb صعد (ṣaʿada) conflates the direction of motion, but not its manner. Table 3 below shows the relevant tokens of the two alternatives in the corpus as well as the frequencies of تسلق (tasallaqa) and alternative no-manner realisations in the TT.
Table 3
Tokens of تسلق (tasallaqa) [climb] and alternatives in corpus and TT
![Tokens of تسلق (tasallaqa) [climb] and alternatives in corpus and TT](/en/journals/meta/2020-v65-n1-meta05678/1073642ar/media/2157710.jpg)
Table 3 shows that the corpus frequency of تسلق (tasallaqa) is about five times lower than that of صعد (ṣaʿada). This difference is statistically significant (X2 = 1,453.263; p < 0.05), indicating that, in this case, Arabic favours the use of the no-manner verb, صعد (ṣaʿada), to the manner verb, تسلق (tasallaqa). By contrast, in the TT, renderings using the manner verb outnumber the no-manner verb by a ratio of 6:1. Comparing the intra-corpus frequencies with those of the TT revealed that this difference is statistically significant (X2 = 113.455; p < 0.05). This suggests that most of the 30 TT instances of تسلق (tasallaqa) that were found inter-textually non-explicitational in Phase 2 are not registerially instantiated. Given that the alternative rendering is less explicit, the highly frequent use of تسلق (tasallaqa) in the TT means that, in this respect, it is more explicit than comparable TL non-translations. See Othman (2019: 169-174) for a registerial analysis of jumping, furtive, and rapid motion.
3.2.2.2. Zero-equivalents verbs: implicitations
In the case of zero-equivalent verbs, it is impractical to apply the procedure described above since there is a large number of possible alternative translations within the systemic potential of the language. For example, the verb to edge does not translate equivalently as one verb in Arabic, but has to be rendered as a low-manner verb (like to walk) or a no-manner verb (such as to proceed or to move) and a Circumstance of manner (slowly, gradually, unhurriedly, etc.). The question addressed here is whether Arabic, specifically the literary genre, prefers to suffice with such general verbs as to walk and to move or to further augment them with manner Circumstances.
To answer this question, given that the corpus used cannot be searched for complex syntactic patterns comprising a verb and an adverbial or prepositional phrase, one option was to look up general motion verbs and find the ratio of those augmented with manner Circumstances. Therefore, I conducted a search limited to the past tense of two highly-frequent low-manner verbs – مشى (mashā) and its synonym سار (sāra), both of which are direct equivalents of to walk – and investigated a sample of the tokens. The relevant motion instances of مشى (mashā) amounted to around 1,800 and those of سار (sāra) to around 3,500. Of these, only 207 tokens of مشى (mashā) and 155 tokens of سار (sāra) were augmented with manner of motion Circumstances. This accounts for only 7% of the total motion tokens of these two verbs. For more validity, I also examined the first 500 hits of two highly frequent no-manner verbs, خرج (kharaja) [exit] and دخل (dakhala) [enter], and found only 6 and 5 instances, respectively, that were enhanced with manner adverbials. Although they addressed only four verbs, the results of these corpus queries provide evidence that Arabic is inclined to disregard specific manner details when employing low-manner verbs (like to walk or to jump) and no-manner verbs (such as to exit or to enter). These results provide a useful frame of reference for assessing the registerial status of the [–content] shifts in renderings of the English zero-equivalent verbs in the TT.
In Phase 1, I found 51 tokens of zero-equivalent verbs in the ST. In the TT, 15 (29%) of their renderings were explicitational, manifested by unpacking. The remaining 36 (71%) renderings were implicitational shifts and omissions (see Table 2 above). Based on the results obtained from the corpus for the low-manner مشى (mashā) and سار (sāra) [walk] and the no-manner verbs خرج (kharaja) [exit] and دخل (dakhala) [enter], the relatively high frequency (29%) of augmented instances is a feature of the TT that is not registerially instantiated, which increases the explicitness of the TT in comparison with TL non-translations. By contrast, the large number (71%) of implicitations and omissions contributes to the overall level of registerial instantiation of the TT, since this feature is more in line with the Arabic preference toward low-manner and no-manner realisations. Thus, although the implicitations and omissions represent [–content] shifts in comparison to the ST, the overall effect at the registerial level is non-explicitational. In short, translating zero-equivalent high-manner verbs by means of unpacking will tend to both have a (ST-TT) inter-textually explicitational effect and contribute to registerial explicitness. On the other hand, translating such verbs using reduced-manner or no-manner alternatives, regardless of lexicogrammatical realisation, will result in renderings that are inter-textually implicitational, but do not contribute towards implicitness at the registerial level. Further research is needed to confirm this finding based on a more detailed corpus analysis.
4. Discussion and conclusions
The present article is intended to contribute both to translation studies (more specifically to the study of English-Arabic translations) and to the wider field of comparisons between English and Arabic in general. As noted above, the principal insight provided here is that there is no direct correspondence either between content shifts and explicitation status or between explicitation and explicitness. Thus, each phase yields new insights, from a different perspective, into both the process and the product of translation, while comparative analyses bring the multidimensional nature of both process and product into even sharper focus. Phase 1 enables comparison of the ideational content of the TT and the ST. Phase 2 provides information on the extent to which content shifts and non-shifts in the TT correspond to the explicitation status of the translated renderings. Phase 3 mainly focuses on explicitness measured in terms of registerial instantiation, based on an analysis of a corpus of non-translations from the same register. Phase 3 provides further insights into these choices made by the translator in light of registerial conventions and expectations of target readers. A comparison of Phases 1, 2, and 3 is particularly suggestive with regard to the challenges faced by the translator and her/his overall strategy in response to these challenges, namely the extent to which s/he was aiming to remain faithful to the original and/or produce a text that would satisfy the expectations of target readers. This comparison also provides input for an in-depth comparative analysis of the choices available in the two language systems with regard to the linguistic feature of interest.
As noted at the start, the model is designed for application in an analysis of a specific linguistic phenomenon of interest. The way the model is applied will depend upon what it is being used for. Not all components of the model will be relevant for every analysis. For example, in the case study presented here, the emphasis is on the ideational metafunction and experiential congruency. This is to be expected given the linguistic phenomenon under consideration, namely verbs. In a further case study, on causal Relators in an Arabic to English translation (see Othman 2019), the primary emphasis is on logical congruency (again reflecting the linguistic feature being investigated), but the analysis is extended to consider congruency in the textual metafunction. It is easy to see how the analysis of explicitation in the translations of other linguistic features might also involve consideration of the interpersonal metafunction. Consider for example translating between the passive voice and the active voice or the insertion/deletion of comment Adjuncts, which express the speaker’s attitude towards a proposition.
Appendices
Notes
-
[1]
“Experientially, the clause construes a quantum of change in the flow of events as a figure, or a representation of experience in the form of a configuration, consisting of a process, participants taking part in this process and associated circumstances” (Halliday and Matthiessen 1999: 52). “A sequence is a series of related figures” (Halliday and Matthiessen 1999: 50).
-
[2]
In this study, I assume that congruency, understood as the typical realisation of semantic categories, is a feature of traditional Arabic grammar too. This assumption, though not trivial, is a plausible one, despite the paucity of relevant research in Arabic.
-
[3]
However, in cases that involve SL culture-specific information or common knowledge, it is always necessary to consider alternative agnates in the TL (see Othman 2019: 95-96).
-
[4]
For the transcription of Arabic, this study follows the style used by The International Journal of Middle East Studies (IJMES). See <https://www.cambridge.org/core/services/aop-file-manager/file/57d83390f6ea5a022234b400/TransChart.pdf>.
-
[5]
These two examples are reconstructed from a clause taken from the following work: AbuSulayman, AbdulHamid A. (1991/1993): Crisis in the Muslim Mind. (Translated from Arabic by Yusuf Talal DeLorenzo) Herndon: International Institute of Islamic Thought.
-
[6]
Oxford University Press (Last update: 11 December 2019): Worm. Lexico.com. Consulted on 21 March 2020, <https://en.oxforddictionaries.com/definition/worm>.
-
[7]
Golding, William (1954/1996): Lord of the Flies. London: Faber and Faber.
-
[8]
Golding, William (1954/1988): سيد الذباب (Sayyid al-dhubāb) [Master of the flies]. (Translated from English by Fawzi Mheidli) Beirut: Dar al-Harf.
-
[9]
Princeton University (Last update: 28 June 2011): What is WordNet? WordNet. Consulted on 2 March 2020, <https://wordnet.princeton.edu>.
-
[10]
Anthony, Laurence (20 October 2016): AntConc. Version 3.4.4. Tokyo: Waseda University. Consulted on 28 January 2020, <https://www.laurenceanthony.net/software>.
-
[11]
For example, rendering low-manner into high manner verbs is classified as [+content] (see Othman 2019: 130-132).
-
[12]
Bibliotheca Alexandrina (Last update: 18 April 2014): International Corpus of Arabic. Bibalex.org. Consulted on 15 February 2020, <https://www.bibalex.org/ica/en/About.aspx>.
-
[13]
Urbaniak, Geoffrey C. and Plous, Scott (22 June 2013): Research Randomizer. Version 4.0. Consulted on 17 February 2020, <http://www.randomizer.org>.
-
[14]
To calculate the ratios representing the normalized frequencies of the Arabic verbs and to find whether they are significantly different, I used the Corpus Frequency Test Wizard. Baroni, Marco and Evert, Stefan (Last update: 1 August 2008): Corpus Frequency Test Wizard. Statistical Inference: A Gentle Introduction for Linguists (SIGIL). Consulted on 3 March 2020, <http://sigil.collocations.de/wizard.html>.
-
[15]
I used the chi-square calculator for a simple 2x2 contingency table available at the following website. Stangroom, Jeremy (Last update: 1 March 2013): Chi-Square Calculator. Social Science Statistics. Consulted on 21 March 2020, <https://www.socscistatistics.com/tests/chisquare/default2.aspx>.
Bibliography
- Dawood, Mohamed (2002): الدلالة والحركة (Aldalalat walharaka) [Semantics and motion]. Cairo: Dar Ghareeb.
- Firbas, Jan (1995): Retrievability span in functional sentence perspective. Brno Studies in English. 21(1):17-45.
- Halliday, Michael (1971): Linguistic function & literary style: An inquiry into the language of William Golding’s The Inheritors.In: Seymour Chatman, ed. Literary Style: A Symposium. Oxford: Oxford University Press, 330-368.
- Halliday, Michael (1978): Language as Social Semiotic: The Social Interpretation of Language and Meaning. London: Edward Arnold.
- Halliday, Michael (1992): Language theory and translation practice. Rivista internazionale di tecnica della traduzione. 0:15-25.
- Halliday, Michael and Matthiessen, Christian (1999): Construing Experience through Meaning: A Language-Based Approach to Cognition. London/New York: Cassell.
- Halliday, Michael and Matthiessen, Christian (2014): Halliday’s Introduction to Functional Grammar. London/New York: Routledge.
- Levin, Beth and RappaportHovav, Malka (1992): The lexical semantics of verbs of motion: The perspective from unaccusativity. In: Iggy Roca, ed. Thematic Structure: Its Role in Grammar. Berlin: Walter de Gruyter, 247-269.
- Matthiessen, Christian (1991): Lexico(grammatical) choice in text generation. In: Cécile Paris, William Swartout, and William Mann, eds. Natural Language Generation in Artificial Intelligence and Computational Linguistics. Boston: Kluwer, 249-292.
- Othman, Waleed (2019): An SFL-based model for investigating explicitation-related phenomena in Translation: Two case studies of English-Arabic translation. Doctoral dissertation, unpublished. Birmingham: University of Birmingham.
- Papai, Vilma (2004): Explicitation: A universal of translation text? In: Anna Mauranen and Pekka Kujamaki, eds. Translation Universals: Do They Exist? Amsterdam/Philadelphia: John Benjamins, 143-64.
- Pym, Anthony (2010): Exploring Translation Theories. London/New York: Routledge.
- Sinclair, John (1999): A way with common words. In: Hilde Hasselgard and Signe Oksefjell, eds. Out of Corpora: Studies in Honour of Stig Johansson. Amsterdam: Rodopi, 157-179.
- Slobin, Dan (2004): The many ways to search for a frog: Linguistic typology and the expression of motion events. In: Ruth Berman and Sven Stromqvist, eds. Relating Events in Narrative: Typological and Contextual Perspectives in Translation. Mahwah: Lawrence Erlbaum Associates, 219-257.
- Slobin, Dan (2005): Relating narrative events in translation. In: Dorit Ravid and Hava Shyldkrot, eds. Perspectives on Language and Language Development: Essays in Honor of Ruth A. Berman. Dordrecht: Kluwer, 115-129.
- Talmy, Leonard (2000): Toward a Cognitive Semantics. Vol. 1. Cambridge: MIT Press.
- Vinay, Jean-Paul and Darbelnet, Jean (1958): Stylistique comparée du français et de l’anglais. Paris: Didier.
- Vinay, Jean-Paul and Darbelnet, Jean (1958/1995): Comparative Stylistics of French and English. (Translated from French by Juan C. Sager and Marie-Josée Hamel) Amsterdam/Philadelphia: John Benjamins.
List of tables
Table 1
Content shifts across verb categories
Table 2
Explicitation status across verb categories
Table 3
Tokens of تسلق (tasallaqa) [climb] and alternatives in corpus and TT