Abstracts
Résumé
La recherche présentée vise à tester l’un des fondements du modèle d’enseignement de la lecture préconisé au Québec depuis 1979. Ce modèle suppose que les enfants apprennent à lire par la reconnaissance globale des mots. Des enfants de la région montréalaise ont été enregistrés à la fin de la première année, pendant qu’ils lisaient un texte à haute voix. Les résultats obtenus invalident le modèle québécois en montrant que tous les enfants utilisent des stratégies de décodage. Des différences majeures apparaissent entre les lecteurs forts qui ont automatisé les mécanismes de décodage de base et les lecteurs faibles qui affichent des retards importants. L’analyse confirme que tous les types de lecteurs sont influencés par les caractéristiques orthographiques des mots.
Abstract
This study examines one of the principal characteristics of the model for teaching reading in Quebec from 1979. This model assumes that children learn to read by global word recognition. An analysis was conducted of video recordings of Montreal region finishing-Grade 1 students’ oral reading of a text. The results do not support the Quebec model by showing that all students use decoding strategies. Major differences were seen however between skilled readers who used automated decoding strategies and those who were weak and who showed significant learning delays. This analysis confirms, among other findings, that the different types of readers were influenced by orthographic characteristics of words.
Resumen
La investigación presentada consiste en poner a prueba uno de los fundamentos del modelo de enseñanza de la lectura preconizado en Quebec desde 1979. Este modelo supone que los niños aprenden a leer por el reconocimiento global de las palabras. Para ello, algunos niños de la región de Montréal fueron registrados en video, a finales del primer año escolar, mientras leían un texto en voz alta. Los resultados obtenidos invalidan el modelo quebequense mostrando que todos los niños utilizan estrategias de decodificación. Las diferencias mayores aparecen, además, entre los buenos lectores que han automatizado los mecanismos de decodificación de base y los malos lectores, los cuales muestran retrasos importantes. El análisis confirma también que todos los lectores están infuenciados por las características ortográficas de las palabras.
Zusammenfassung
Die vorliegende Arbeit hat sich zum Ziel gesetzt, eine der Grundlagen des Lektüremodells zu überprüfen, das in Québec seit 1979 verwendet wird. Dieses Modell geht davon aus, dass die Lerner mit Hilfe einer globalen Erfassung der Wörter lesen lernen. Kinder aus dem Raum Montréal wurden am Ende des ersten Lernjahres beim lauten Lesen eines Textes mit der Videokamera gefilmt. Die dabei gemachten Observationen ergaben, dass das Québecker Modell nicht stimmt, da die Kinder beim Lesen Dekodierungsstrategien verwendeten. Außerdem ergaben sich entscheidende Differenzen zwischen den guten Lesern, die die grundlegenden Dekodierungsstrategien beeits automatisiert haben, und den schwachen Lesern, die hinter den anderen zurückbleiben. Die Analyse bestätigt unter anderem, dass alle Lernertypen vor allem von den orthografischen Charakteristiken der Wörter beeinflusst werden.
Article body
Introduction
Le curriculum québécois 2000 (Gouvernement du Québec, 2001) définit la compétence en lecture que doivent atteindre les enfants dès le premier cycle du primaire comme la capacité à « lire des textes variés » mais, dans la description qui est donnée des composantes de cette compétence, seuls figurent les processus de compréhension ; aucune référence explicite n’est faite aux processus de lecture (encart 1).
Cette conception de la lecture et de son apprentissage est celle qui caractérise l’approche whole-language qu’on applique de façon exclusive au Québec depuis vingt ans (Pierre, dans ce numéro, p. 3-35). Elle sous-tend tout autant les méthodes d’enseignement approuvées par le ministère de l’Éducation que les méthodes d’évaluation qu’il préconise, comme en témoignent deux documents d’accompagnement du curriculum (Gouvernement du Québec, 2002a et b). Ces documents visent à préciser à la fois le concept de compétences sur lequel repose le nouveau curriculum et comment évaluer les niveaux de compétence. Quatre niveaux sont distingués pour la compétence en lecture dans lesquels lecture et compréhension sont toujours confondues sans que ni l’une ni l’autre ne soient définies sinon en référence à des comportements particuliers qui confirment les fondements béhavioristes du modèle par compétences, malgré les prétentions constructivistes des concepteurs du curriculum.
Encart 1
Critères d’évaluation de la compétence 1 : «Lire des textes variés »
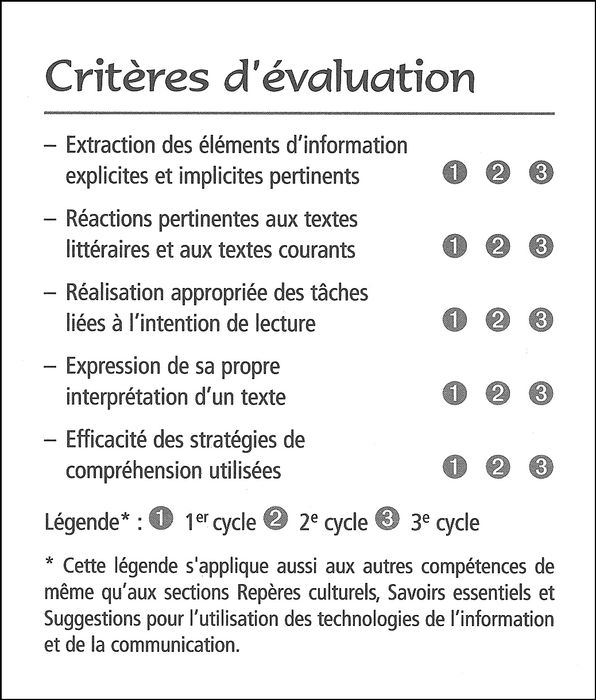
Le niveau 1 présente un mélange de comportements face au livre, typiques de la prématernelle, sinon de la garderie, avec l’émergence de stratégies logographiques qu’on associe à la reconnaissance de mots familiers ou déjà vus en classe, sans préciser comment ces comportements se manifestent et évoluent entre la maternelle et la première année ni en quoi ils sont différents des comportements de reconnaissance globale qu’on attribue aussi au lecteur de niveau 4. Aucune allusion n’est faite à l’acquisition des concepts de l’écrit ni à celle de la conscience phonologique. On sait, par les recherches récentes, que ces concepts ont déjà atteint un certain niveau quand les enfants arrivent en première année et qu’ils sont préalables [1] à l’apprentissage de la lecture (Brodeur, Deaudelin, Bournot-Trites, Siegel et Dubé, dans ce numéro ; Morais, Pierre et Kolinsky, dans ce numéro).
Le niveau 2 ne fait que paraphraser, avec les mêmes confusions [2], les stratégies de lecture introduites par le programme de 1979 (Gouvernement du Québec, 1979) ; depuis lors, on retrouve ces dernières dans toutes les méthodes québécoises : a) stratégies idéographiques (avec support imagé) et logographiques [3] (sans support imagé) pour la reconnaissance globale des mots ; b) stratégies d’anticipation qu’on réduit aux stratégies contextuelles sans distinguer le contexte imagé et le contexte linguistique. Les stratégies graphophonétiques sont mentionnées, mais toujours en association avec les stratégies d’anticipation comme dans le programme de 1979 et sans préciser ce qu’on entend par là ni quelles sont les connaissances que les enfants doivent maîtriser sur le code pour les appliquer.
En ce qui concerne la lecture, les seuls éléments nouveaux introduits par le niveau 3 sont la capacité d’identifier des mots nouveaux, sans préciser par quel comportement cette capacité se manifeste, et la référence à l’utilisation de la ponctuation. Pourquoi la ponctuation et non les autres indices syntaxiques et morphologiques ?
La description du niveau 4 [4] laisse entendre que tous les enfants maîtrisent les stratégies de lecture à la fin de la deuxième année primaire, y compris les stratégies orthographiques, morphologiques et syntaxiques qui n’ont jamais été mentionnées dans les niveaux précédents, et que les enfants appliquent toutes ces stratégies sans problème pour comprendre des textes variés. Tout au long de cette description, à chaque niveau, la lecture est au service de la compréhension et n’est pas définie en tant qu’objet d’enseignement, comme c’était le cas dans le programme de 1979 :
Niveau 1. L’élève fait semblant de lire […], il cherche aussi à donner du sens aux écrits qu’il rencontre […]. Dans les textes qu’il aborde, il reconnaît quelques mots familiers ou déjà vus en classe […].
Niveau 2. Afin de construire du sens, l’enfant utilise des stratégies de reconnaissance et d’identification des mots […].
Niveau 3. Pour comprendre l’essentiel d’un texte […], il utilise les stratégies appropriées […] dont la reconnaissance et l’identification des mots […].
Niveau 4. Afin de comprendre les textes qu’il lit, l’élève a recours aux principales stratégies apprises.
Gouvernement du Québec, 2001, p. 20
Contexte théorique
L’apprentissage du décodage : un stade obligé
En maintenant le modèle whole-language dans le curriculum 2000, le Québec s’isole de la plupart des pays qui l’avaient adopté et qui le rejettent aujourd’hui en tenant compte des recherches qui en ont invalidé les fondements [5]. Dans la perspective de ce modèle, les processus de décodage n’interviennent que si les stratégies d’anticipation (stratégies contextuelles, sémantiques, syntaxiques, morphologiques) n’ont pas permis la reconnaissance globale du mot. On suppose, par ailleurs, qu’il n’est pas nécessaire d’enseigner ces processus, mais que les enfants les acquerront naturellement si on leur permet de vivre des situations de lecture significatives et variées et d’exercer les stratégies d’anticipation (Pierre, dans ce numéro, p. 3-35 ; Pierre, à paraître). Pourtant, il est maintenant bien établi scientifiquement que, contrairement à ce que présupposaient Goodman (1967) et Smith (1971, 1975a) sur lesquels le modèle whole-language est fondé, ce sont les mauvais lecteurs qui utilisent les stratégies d’anticipation alors que les bons lecteurs utilisent les stratégies de décodage qui sont plus efficaces et cognitivement plus économiques. Par ailleurs, l’état de la recherche sur l’identification des mots en psycholinguistique cognitive et en neuropsychologie (Morais, Pierre et Kolinsky, dans ce numéro) laisse maintenant peu de doute sur le fait que la maîtrise des mécanismes de décodage est la principale composante de l’expertise en lecture et que les difficultés d’apprentissage de la lecture ne sont pas liées au fait que les enfants utilisent trop le décodage, mais au fait qu’ils ne savent pas l’utiliser (Alegria, Leybaert et Mousty ; 1994 ; Morais, Mousty et Kolinsky, 1998 ; Morais, Pierre et Kolinsky, dans ce numéro ; Siegel, 1998 ; Stanovich, Siegel, Gottardo, Chiappe et Sidhu, 1997 ; Stanovich et Stanovich, 1997 ; Vellutino, Scallon et Sipay, 1997). Un autre courant de recherches montre finalement que, à un stade de leur développement, tous les enfants qui apprennent à lire dans un système d’écriture alphabétique ont recours au décodage non pas comme « stratégie de dépannage », selon l’expression québécoise, mais comme stratégie d’apprentissage de la lecture. L’apprentissage de la lecture relèverait donc de principes de développement qui seraient relativement indépendants des méthodes d’enseignement, que les méthodes viendraient contrer ou renforcer selon le cas.
Le modèle développemental de référence a longtemps été celui de Frith (1985, 1986) qui prévoit trois stades. La conception qui sous-tend le modèle whole-language correspondrait au premier stade qu’on appelle logographique de logos, mot, et graphein, écrire, en grec. Bien que les âges des sujets varient d’une recherche à l’autre, ce stade commencerait autour de 3-4 ans et s’étendrait jusqu’au premier semestre de la première année, alors que commence l’enseignement de la lecture, dans la plupart des pays. À ce stade, on dit que les enfants reconnaissent les mots globalement, mais en fait, les recherches ont montré qu’ils s’appuient sur certains traits visuels qui caractérisent les mots. Par exemple, très tôt, les enfants disent « McDonald » en voyant le logo caractéristique lorsqu’il est une reproduction couleur exacte, mais ils ne le reconnaissent plus dès qu’on enlève la couleur ou qu’on écrit le mot en caractères réguliers. Ces enfants ne lisent pas. Ils reconnaissent un ensemble pictural de la même manière qu’ils reconnaissent des images qui leur sont familières. Parce qu’ils ne s’appuient que sur des indices visuels spécifiques aux mots (la forme typique du M) ou au contexte extralinguistique (la couleur jaune sur fond rouge) ou sur des connaissances limitées du code écrit (le nom de la lettre M), les enfants du stade logographique ne peuvent reconnaître que des mots familiers, des mots qu’ils ont déjà appris à reconnaître. Ils font par ailleurs beaucoup d’erreurs fondées sur des similitudes visuelles entre les mots, l’erreur la plus typique étant la confusion entre des lettres qui partagent des traits visuels communs comme p et q, d et b.
Pour certains chercheurs, ces comportements ne sont pas directement liés à l’apprentissage de la lecture. Pour eux, la première étape d’apprentissage de la lecture se situe au moment où l’enfant prend conscience que certaines lettres, comme la première lettre de leur nom, peuvent être associées à des sons ou que certains mots riment entre eux parce qu’ils partagent les mêmes sons (Blachman, 1991 ; Ehri, 1997 ; Morais, Cary, Alegria et Bertelson, 1979 ; Morais, Mousty et Kolinsky, 1998 ; Morais, Pierre et Kolinsky, dans ce numéro ; Rack, Hulme, Snowling et Wightman, 1994 ; Scallon et Vellutino, 1996 ; Vellutino et Scallon, 1991). Les débuts de l’apprentissage de la lecture seraient, selon eux, directement reliés au développement de la conscience phonologique, c’est-à-dire à la prise de conscience que les mots à l’oral sont constitués d’unités plus petites comme les syllabes dans « cha-peau » qui se décomposent en attaques « ch » « p » et en rimes « a » « eau» qui correspondent respectivement à des phonèmes consonantiques [ʃ] et [p] vocaliques [ɑ] et [o].
Dans cette perspective, le premier stade d’apprentissage de la lecture serait le stade alphabétique qui est considéré comme le stade 2 dans le modèle de Frith (1985, 1986). Au cours du stade alphabétique, les enfants développent leur conscience du principe alphabétique qui régit notre système d’écriture en cherchant à établir les correspondances entre les graphèmes [6] et les phonèmes [7] (Ehri, 1991, 1997, 1999 ; Gough, 1993 ; Gough, Juel et Griffith, 1992 ; Morais, Pierre et Kolinsky (dans ce numéro) ; Stanovich, 1991 ; Harris et Coltheart, 1986 ; McBride-Chang, 1999 ; Morais, Cary, Alegria et Bertelson, 1979 ; Morais, Mousty et Kolinsky, 1998). Cette prise de conscience que les mots sont constitués d’unités plus petites qui correspondent à des unités phonologiques se traduit dans la lecture orale par le découpage des mots en unités graphémiques en procédant de gauche à droite selon le sens de la lecture, ce qui correspond à ce que Morais, Pierre et Kolinsky (dans ce numéro) appellent le décodage séquentiel. L’étendue de ce stade et les comportements qu’il inclut sont variables selon l’interprétation que les auteurs font des premiers comportements de lecteurs. Toutefois, les chercheurs s’entendent généralement pour reconnaître que cette période s’étend jusqu’au deuxième semestre de la première année et pour certains enfants, jusqu’au premier semestre de la deuxième année du primaire.
Le passage du stade alphabétique au stade orthographique, qui conduit à la lecture experte, se manifesterait par le fait que les apprentis lecteurs cessent de découper les mots et qu’ils les reconnaissent instantanément. Cette reconnaissance ne serait toutefois pas globale comme le présupposaient Goodman et Smith. L’illusion de la reconnaissance globale viendrait de ce que les enfants auraient appris, comme les lecteurs adultes, à traiter les unités graphémiques en parallèle (Morais et al., dans ce numéro ; Stanovich, 1991), c’est-à-dire simultanément, en s’appuyant sur leurs connaissances des correspondances graphèmes-phonèmes et des règles contextuelles qui régissent le fonctionnement de ces correspondances : par exemple, la règle du « g » dur [g] devant « a » et « o » « garage » et du « g » doux [ʒ] devant « e » et « i » « gentil » ou les règles morphologiques qui dictent de ne pas prononcer les marques du pluriel des verbes en oralisant les mots « les enfants mangent ». Au contraire des enfants du stade logographique qui donnent aussi l’illusion de reconnaître les mots globalement, les enfants du stade orthographique peuvent reconnaître spontanément, sans avoir recours au décodage séquentiel, des mots qu’ils n’ont jamais vus et qui présentent des structures orthographiques irrégulières, comme le mot [fam] « femme » (Barron, 1986 ; Doctor et Coltheart, 1980 ; Seidenberg, Waters, Barnes et Tannenbaum, 1984).
Le décodage : une question de langue
Diverses modulations de ce modèle de base ont été proposées dont le modèle de Seymour (1994, 1997) qui remet en question le caractère développemental de ces stades en faisant valoir, d’une part, que le système orthographique de l’anglais reposerait sur deux principes fondateurs, l’un alphabétique, l’autre morphologique et, d’autre part, que les méthodes d’enseignement peuvent influencer le cours du développement. Dès le début de l’apprentissage, les enfants apprendraient donc à utiliser simultanément des stratégies logographiques et alphabétiques. À l’inverse, d’autres font valoir que le modèle de Frith, comme celui de Seymour ne valent que pour l’anglais (Cadosso-Martin, 1995 ; Cossu, Schankwiller, Liberman, Tola et Katz, 1988 ; Cossu, Gugliotta et Marshall, 1995 ; Goswami, 1999 ; Goswami, Gombert et de Barrera, 1998 ; Sebastian et Vacciano, 1995 ; Wimmer, 1997 ; Wimmer et Hummer, 1990 ; Wimmer et Goswami, 1994). Leur position s’appuie sur un certain nombre de recherches qui montrent que l’apprentissage de la lecture est plus facile en espagnol, en italien ou en allemand dont les systèmes orthographiques sont plus transparents qu’en anglais. Le degré de transparence d’un système orthographique est défini en fonction du degré de complexité des correspondances graphèmes-phonèmes. Un système orthographique serait dit transparent lorsque les correspondances graphèmes-phonèmes seraient relativement directes et prévisibles (De Francis, 1989). En outre, ces auteurs disent ne pas avoir retrouvé chez leurs sujets de comportements de type logographique. Pour eux, l’apprentissage de la lecture commence par le stade alphabétique, tout au moins dans les langues dont le système orthographique est relativement transparent.
Si on a longtemps pensé que le français avait un système aussi opaque que l’anglais, certains chercheurs, comme Sprenger-Charolles (1992), croient que c’est plutôt un système intermédiaire. Si, effectivement, le français a recours à des digraphes (graphèmes de deux lettres comme « ai » « ou » « au » « an » « on » « un » pour les voyelles ; « ch » « qu » « gn » pour les consonnes) et à des trigraphes (graphèmes de trois lettres comme « eau » « aim » « aou » « aon »), comme l’anglais, les règles de correspondances avec les phonèmes qu’ils représentent et les règles contextuelles [8] qui régissent leur utilisation seraient plus stables et plus aisément prévisibles (Catach, 1986 ; Ducart, Honvault et Jaffré, 1995). Par ailleurs, la structure syllabique serait plus simple en français qu’en anglais. Alors que les syllabes fermées qui finissent par une consonne, comme « porte » [pɔrt], seraient plus fréquentes en anglais, les syllabes ouvertes qui finissent par une voyelle, comme « Pa-mé-la » [pa][me][la], domineraient en français (Delattre, 1965, 1966). En outre, les problèmes de liaisons entre les mots, ajoutés au fait qu’en français, l’accent tonique délimiterait moins bien les frontières des mots qu’en anglais (DeJean, De La Batie et Bradley, 1995 ; Delattre, 1940, 1947) rendraient leur identification plus difficile, ce qui expliquerait que les enfants francophones privilégieraient des stratégies graphophonétiques plutôt que logographiques (Sprenger-Charolles, 1992 ; Sprenger-Charolles, Siegel et Béchennec, 1997 ; Sprenger-Charolles, Siegel et Bonnet, 1998).
Cette hypothèse n’a toutefois été que partiellement confirmée. Le passage par un stade logographique dans l’apprentissage de la lecture reste objet de débats (Bastien et Bastien-Tognazzo, 1993 ; David, dans ce numéro ; Ehri, 1992, 2000 ; Gough, Juel et Griffith, 1991 ; Wimmer et Hummer, 1990). Ainsi, l’effet de familiarité des mots, qui est un indicateur du recours à des stratégies logographiques, joue de façon différente et quelquefois contradictoire selon les recherches menées par Sprenger-Charolles. Par contre, l’effet de longueur et de régularité orthographique des mots, qui traduisent le recours au décodage, jouent de façon systématique et cohérente d’une recherche à l’autre. De même, les corrélations positives significatives qu’elle a obtenues entre les indicateurs de décodage en première année et les indicateurs de traitement orthographique en deuxième année appuient l’hypothèse selon laquelle l’apprentissage des stratégies de décodage est un stade nécessaire à la maîtrise des stratégies orthographiques qui sont la marque des lecteurs accomplis.
Hypothèses de la recherche
S’ils confirment que l’apprentissage du décodage est un stade nécessaire dans l’apprentissage de la lecture en français, les résultats de Sprenger-Charolles laissent ouvertes plusieurs questions importantes du point de vue didactique mais aussi du point de vue psycholinguistique (David, dans ce numéro). La première est l’impact que les méthodes d’enseignement peuvent avoir eu sur ses résultats. Comme le confirme Sprenger-Charolles, les enfants de ses échantillons provenaient tous de classes dans lesquelles les enseignantes utilisaient des approches éclectiques. C’est la situation dominante en France (Mettoudi et Yaïche, 1993) où, malgré l’influence de Foucambert (1976), l’approche whole-language a eu un impact plus marginal qu’au Québec [9]. Or, depuis la publication classique de Chall (1967), les recherches qui ont comparé l’efficacité des méthodes d’enseignement ont généralement montré un effet plus significatif, sur l’apprentissage de la lecture, des méthodes qui faisaient une place à l’enseignement du décodage (Adams, 1990 ; Bruck, Genesee et Caravolas, 1997 ; Chall, 1999 ; Content et Leybert, 1992 ; Dahl, Scharer, Lawson et Grogan, 1999 ; Freppon et McIntyre, 1999 ; McIntyre et Freppon, 1998 ; Readance et Baron, 1997 ; Stanovich, 1998 ; Stanovich et Stanovich, 1997 ; Vellutino, 1991).
Si les recherches antérieures ne permettaient pas de cibler avec précision l’influence des méthodes, cela devient maintenant possible grâce aux données accumulées par les recherches expérimentales et développementales. On peut penser, avec Seymour (1994, 1997), que, contrairement aux enfants français qui apprennent à lire avec des approches éclectiques, les enfants québécois qui apprennent à lire avec une approche whole-language feront davantage appel à des stratégies logographiques. Toutefois, si l’on accepte l’hypothèse que l’apprentissage de la lecture répond à des contraintes de développement cognitif relativement indépendantes des méthodes d’enseignement, on peut aussi penser que certains enfants apprendront implicitement les règles de décodage alors que d’autres n’y parviendront pas par eux-mêmes et accuseront du retard dans l’acquisition des stratégies graphophonétiques. Ainsi, à la fin de la première année, on peut s’attendre à ce que les enfants québécois se distinguent par le recours à des stratégies de lecture différentes qui manifesteront des niveaux de développement différents. Les meilleurs lecteurs auront amorcé le stade orthographique, c’est-à-dire qu’ils auront automatisé les processus de décodage de base et commencé à intégrer les processus de traitement orthographique. Les lecteurs les plus faibles utiliseront surtout des stratégies logographiques et n’auront pas intégré les stratégies de décodage de base. Les lecteurs moyens, qui représenteront la majorité des enfants, se situeront entre les deux, c’est-à-dire au stade alphabétique.
La différence entre les trois groupes se manifestera également par l’influence que les caractéristiques des mots auront sur le choix et l’application des stratégies de reconnaissance des mots. Sur la base des études antérieures, on peut ainsi poser comme hypothèse que la familiarité des mots aura plus d’influence sur les lecteurs faibles que sur les lecteurs moyens et forts alors que la longueur et la complexité orthographique des mots auront plus d’influence sur les lecteurs moyens et forts.
Méthodologie de la recherche
Collecte des données
Si les recherches expérimentales ont permis de comprendre les processus de lecture au-delà des apparences et des illusions créées par la rapidité avec laquelle ces processus sont exercés, elles prêtent flanc aux critiques des pédagogues, comme McQuillan (1998) et Weaver (1998), qui leur reprochent leur manque de validité écologique. C’est sur cet argument que Goodman (Cambourne, 1982) avait construit son modèle et qu’il avait mis au point la méthode de cueillette et d’analyse des méprises qui devait lui permettre de démontrer que les lecteurs procèdent par anticipation et que les résultats qui émanent des recherches expérimentales ne sont pas transposables en situation naturelle de lecture. Les résultats que nous avons obtenus dans nos recherches antérieures sur le rôle de l’anticipation dans la compréhension de textes en situation naturelle ne soutiennent toutefois pas ces allégations (Pierre, dans ce numéro, p. 3-35).
Encart 2
Texte expérimental

La méthodologie adoptée pour la présente recherche vise le même objectif : vérifier dans quelle mesure les résultats obtenus dans les recherches expérimentales et développementales se transposent dans une situation naturelle de lecture, mais cette fois en regard des processus de reconnaissance et de décodage des mots. Pour la collecte de données, nous avons fait lire aux enfants un texte, Le funambule (encart 2), tiré d’une méthode de lecture québécoise (Gaouette, 1999, p. 108-109) qui est proposé pour la période de mai-juin.
L’analyse des 83 mots à contenu (noms, verbes, adjectifs) a permis de confirmer que le texte posait de nombreux problèmes de décodage qui nous permettraient de vérifier nos hypothèses tout en évitant les effets de plafonnement auxquels Sprenger-Charolles a été confrontée en raison de la trop grande simplicité de son matériel de lecture. Le tableau 1 présente la distribution des mots du texte selon les variables qui ont été prises en compte dans l’analyse.
Tableau 1
Distribution des mots selon les variables retenues pour l’analyse des résultats
Démarche de lecture
La démarche de lecture utilisée est une adaptation de la démarche proposée dans les méthodes québécoises. Sur la base de l’analyse que nous en faisions, à la lumière des recherches existantes, nous avons toutefois clarifié les ambiguïtés de cette approche telle qu’elle est appliquée présentement. La première était la confusion entre lecture et compréhension. La compréhension étant définie, à la suite de Kintsch et van Dijk (1983), comme l’habileté à extraire les connaissances (base sémantique du texte) et à les intégrer dans ses connaissances antérieures, les stratégies sémantiques et contextuelles sont clairement des stratégies de compréhension. La lecture étant définie, à la suite de Morais (1993) et de Stanovich (1991), comme la capacité à identifier les mots dans un texte, les stratégies graphophonétiques sont clairement des stratégies de lecture. Quant aux stratégies syntaxiques et morphologiques, elles peuvent être utilisées, soit pour soutenir la compréhension, soit pour soutenir la lecture selon que l’on considère la structure de surface ou la structure de base (Chomsky, 1979), distinction qui n’est pas faite dans les méthodes québécoises.
Ces distinctions fondamentales établies, on pouvait adapter l’application de la méthode en tenant compte d’une autre implication des recherches existantes : la lecture ne découle pas de la compréhension. Toutefois, dans une situation de lecture naturelle, les deux étant menées en parallèle, c’est-à-dire simultanément, la quantité de ressources cognitives qui est investie pour exercer l’une influence l’autre. Autrement dit, quand l’enfant lit un texte qui est au-dessus de son niveau de lecture autonome, mesuré par sa capacité à lire le texte sans aide, il lui est plus difficile de comprendre parce que toutes ses ressources cognitives sont centrées sur la lecture. À l’inverse, quand le texte qu’il lit est au-dessus de son niveau de compréhension autonome, parce qu’il n’a pas toutes les connaissances antérieures et que le texte comporte beaucoup de connaissances implicites, comme c’était le cas du texte que nous avons utilisé dans notre étude, il éprouve plus de difficultés à le lire : toutes ses ressources cognitives sont investies dans la compréhension. Pour identifier les processus de lecture qui sont mis en oeuvre par des apprentis lecteurs en situation naturelle de lecture, il faut donc contrôler la compréhension, c’est-à-dire l’empêcher d’influencer la lecture. Mais il faut aussi permettre aux processus de lecture de se manifester et non pas les inhiber comme on le fait dans les méthodes québécoises, en poussant les enfants à deviner ou à sauter les mots.
Dans cette perspective, nous avons mis au point la méthode de lecture guidée interactive en appliquant trois principes fondamentaux. Pour maximiser le recours par les enfants (E) aux stratégies de lecture, l’adulte (A) doit s’assurer : 1) qu’ils comprennent le texte au fur et à mesure qu’ils le lisent ; 2) qu’ils traitent tous les mots ; 3) qu’ils mettent en oeuvre les stratégies de lecture au niveau où ils les maîtrisent. Cela signifie que l’expérimentateur, tout en aidant l’enfant à comprendre par lui-même, lui donne les informations manquantes au fur et à mesure qu’il en a besoin :
A – Est-ce que tu sais ce que ça fait un funambule ?
E – C’est quelqu’un qui marche sur un fil en dormant ?
A – Es-tu sûr de ça ?
A – Comment on appelle ça quelqu’un qui marche en dormant ?
E – J’sais pas.
A – Un somnambule. Un funambule c’est quelqu’un qui marche sur un fil, mais il ne dort pas. Qu’est-ce qui arriverait s’il dormait ?
E – Il tomberait.
A – T’as bien raison.
Il l’incite par ailleurs à lire par lui-même et le soutient durant sa lecture, mais cette fois sans lui fournir les informations qui lui manquent, le but étant de l’amener dans ce que Vygotsky (1978) appelle sa « zone proximale de développement », c’est-à-dire la zone de développement entre ce qu’il sait et ce qu’il est prêt à apprendre :
A – Maintenant, est-ce que tu vois le mot funambule dans le text e ?
A – Oui, montre-moi-le ?
A – Comment tu sais que c’est le mot funambule ?
E – Parce que c’est le titre du texte ?
A – Ah oui ? Et comment tu sais ça ?
E – Parce que c’est écrit plus gros et en couleur.
A – Dis donc, tu en sais des choses ! Mais est-ce qu’il n’y a pas une autre façon de savoir que c’est le mot funambule ?
E – En le lisant.
A – Et bien, montre-moi donc comment tu fais pour le lire.
E – Fun-a...
E – Fuma...
A – Qu’est-ce que ça fait a avec m ?
E – En...
A – Maintenant, n avec en ?
E – Nen.
S – Maintenant, essaie de relire depuis le début.
E – Funam...
E – Funambul.
A – C’est ça. Maintenant, tu sais lire le mot funambule.
Sélection des sujets
En mars-avril 2000 et 2001, 150 enfants ont été sélectionnés au hasard et reçus en entrevues. Le tableau 2 présente les caractéristiques individuelles des 44 sujets qui ont fait partie de cette analyse.
Tableau 2
Caractéristiques des sujets

La répartition des sujets dans les trois groupes a été établie à partir de la lecture préalable de 25 mots tirés du texte. Les mots étaient ordonnés par niveaux de difficultés en fonction de leur familiarité et de leur complexité orthographique. La même grille d’analyse que pour les mots du texte a été appliquée (tableau 3). Les 12 enfants qui forment le groupe de lecteurs faibles avaient un score entre 20 % et 30 % [10] ; les scores allaient de 31 % à 65 % pour les 19 enfants du groupe de lecteurs moyens et de 66 % à 100 % pour les 13 enfants qui forment le groupe de lecteurs forts. Le nombre de garçons et de filles est à peu près équivalent dans les trois groupes. L’âge moyen est de 83,81 mois, ce qui correspond à l’âge que les sujets de Sprenger-Charolles avaient à la fin de la première année. Les 44 sujets provenaient de 36 écoles différentes de la grande région de Montréal et représentaient les différents milieux socioéconomiques.
Comme le confirme le tableau 3, tous les sujets ont appris à lire avec une des méthodes accréditées par le ministère de l’Éducation. Or, la condition d’accréditation est d’appliquer le curriculum, donc une approche whole-language. Selon les réponses à un questionnaire, 40 % des enseignantes utilisaient les méthodes Mémo (Guillemette, Létourneau et Raymond, 1989) et En-Tête (Gaouette, 1999), les premières développées après la réforme de 1979 et les seules en vigueur pendant plus de dix ans. On pouvait donc penser qu’elles avaient bien intégré le modèle québécois. On en compte toutefois 22 % qui utilisaient des méthodes plus récentes alors que 14 % déclaraient utiliser un matériel d’appoint, sans en préciser la nature. Par ailleurs, 86 % disaient combiner différentes méthodes et du matériel d’appoint ; ce qui correspond à la tendance que nous observons depuis quelques années.
Tableau 3
Répartition des trois types de lecteurs selon le matériel didactique utilisé

Légende : TL (types de lecteurs) ; Fa (élèves faibles), Mo (élèves moyens), Fo (élèves forts) ; M.A. (matériels d’appoint), C.M. (combinaison de méthodes) ; T (Total), Auc. info (aucune information).
Chaque enfant a été vu individuellement, chez lui ou à l’école. Les entrevues qui étaient enregistrées sur vidéo ont été menées par des étudiantes du baccalauréat en éducation préscolaire-primaire de l’Université de Montréal, qui avaient été formées, dans le cadre du cours de didactique de la lecture que nous donnions en deuxième année du baccalauréat, à appliquer cette démarche. Quarante-quatre enregistrements vidéo ont été sélectionnés de manière à obtenir des nombres à peu près équivalents par groupe de lecteurs, par sexe et par âge, et de manière à ne retenir que les enregistrements qui respectaient les principes de la démarche.
Attribution des scores
Tous les enregistrements ont été visionnés et analysés par le même assistant de recherche [11]. L’analyse consistait à retranscrire chacun des mots en alphabet phonétique international (API) tel qu’ils avaient été lus par l’enfant en distinguant chaque essai. Ainsi, si un enfant s’y prenait à quatre reprises pour lire un mot, la transcription portait sur chacun des quatre essais.
Sept stratégies ont été identifiées après analyse des vidéos. Comme l’indique la description des stratégies au tableau 4, quatre critères ont permis de les distinguer : 1) le mode de reconnaissance des mots selon que la reconnaissance était spontanée et sans pause « funambule » ou qu’elle impliquait le décodage séquentiel des mots mesuré par des pauses entre les unités constitutives des mots « fu-nam-bul » ou « fu-nam-bu-le » ; 2) l’unité de traitement choisie par l’enfant qui pouvait être le mot, la syllabe, le graphème ou la lettre ; 3) le niveau d’automatisation mesuré par le nombre d’essais requis avant de reconnaître un mot ; 4) le niveau d’autonomie mesuré par le nombre de fois où l’expérimentateur est intervenu pour le guider dans sa reconnaissance du mot. Des points ont été attribués à chacune des stratégies sur une échelle de 0 à 6, 0 correspondant à la non-reconnaissance du mot, 6 à la reconnaissance spontanée et sans aide ; c’est le total des scores ainsi obtenus qui a été pris en compte dans les analyses.
Tableau 4
Critères d’évaluation des stratégies de reconnaissance des mots

Analyse des résultats
Choix des tests statistiques [12]
Le nombre de sujets dans les trois groupes de lecteurs étant inférieur à 30, on a utilisé des tests non paramétriques pour vérifier les hypothèses (Conover, 1971). Le test de Kruskall-Wallis a été retenu pour tester les hypothèses sur les différences entre les trois groupes de lecteurs. Ce test compare les distributions des rangs attribués aux scores obtenus. Suivant la suggestion de Conover, lorsque les différences apparaissaient significatives globalement, on comparait ensuite les groupes deux à deux pour permettre de situer les différences. Le test de Mann-Whitney a été utilisé pour comparer les fréquences d’utilisation des stratégies. Le test de Wilcoxon pour échantillons appariés a été retenu pour évaluer l’effet des variables lexicales et orthographiques sur les différences entre les scores. Pour tenir compte des nombres inégaux dans les différentes catégories établies pour les analyses, les scores bruts ont été ajustés en appliquant la formule score/nombre de mots*100. Les tests de Kruskall-Wallis et de Mann-Whitney ont été appliqués sur les scores bruts, les tests de Wilcoxon sur les scores ajustés. Le seuil de signification a été fixé à p < 0,05 pour toutes les analyses. Les résultats individuels ont été colligés et traités sur SPSS 10.0.
Influence du modèle québécois
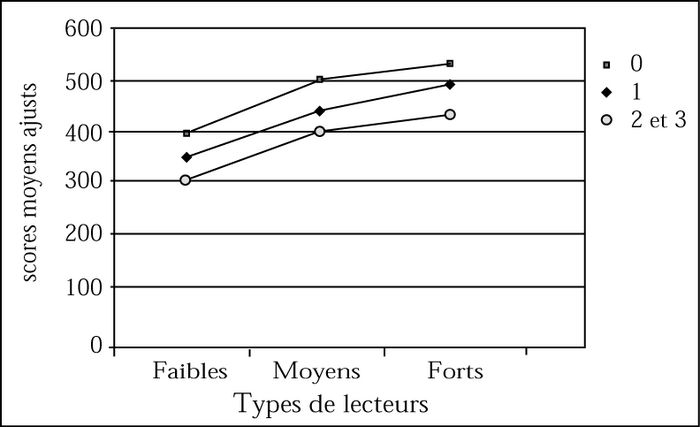
Les premières analyses visaient à vérifier l’influence du modèle québécois sur les stratégies de lecture utilisées par les trois groupes de lecteurs. La première hypothèse selon laquelle la distribution des scores totaux serait différente pour les trois groupes de lecteurs a été vérifiée (p < 0,000). La comparaison entre les moyens et les forts n’a pas fait ressortir de différences significatives (p > 0,078), mais elle en a fait ressortir entre les moyens et les faibles (p < 0,001).
Pour vérifier si ces différences se traduisaient dans le recours à des stratégies différentes, nous avons ensuite comparé les fréquences d’utilisation des 7 stratégies. Étant donné les fréquences faibles d’utilisation de certaines stratégies, nous les avons combinées pour répondre aux exigences des tests statistiques. Les regroupements ont été faits en fonction des critères de reconnaissance et d’autonomie.
On obtient ainsi deux types de stratégies (figure 1). Le type 1 regroupe les stratégies 6-5-4, c’est-à-dire celles qui ont permis aux lecteurs de reconnaître les mots sans aide, et le type 2 regroupe les stratégies 3-2-1, celles pour lesquelles les lecteurs ont bénéficié d’aide de telle sorte que s’ils avaient lu seuls, il est probable qu’ils n’auraient pas reconnu les mots.
Figure 1
Fréquences d’utilisation des stratégies par les trois types de lecteurs

La comparaison entre les distributions des fréquences d’utilisation des stratégies de type 1 fait apparaître des différences significatives entre les trois groupes (p < 0,000). Contrairement aux analyses sur les scores globaux, l’application du test de Mann-Whitney révèle des différences significatives entre les forts et les moyens (p < 0,041). Les différences sont également significatives entre les forts et les faibles (p < 0,000) et les moyens et les faibles (p < 0,001). Autrement dit, comme l’illustre la figure 1, les lecteurs forts utilisent plus fréquemment les stratégies de type 1 que les lecteurs moyens qui les utilisent plus fréquemment que les lecteurs faibles. Les mêmes analyses appliquées sur les stratégies de type 2 confirment que ce sont les lecteurs faibles qui les utilisent plus fréquemment. Ici aussi, les différences apparaissent statistiquement significatives entre les lecteurs forts et les lecteurs moyens (p < 0,041), de même qu’entre les lecteurs faibles et les lecteurs moyens (p < 0,001), les lecteurs faibles et les lecteurs forts (p < 0,000). Autrement dit, les trois groupes de lecteurs se différencient de façon significative par le degré d’autonomie dont ils font preuve pour reconnaître les mots. Alors que les lecteurs forts ont reconnu, sans aide, 77 mots sur 83, les lecteurs moyens en ont reconnu 70 et les lecteurs faibles 48, c’est-à-dire à peine plus de la moitié.
Influence de la familiarité et de la longueur des mots
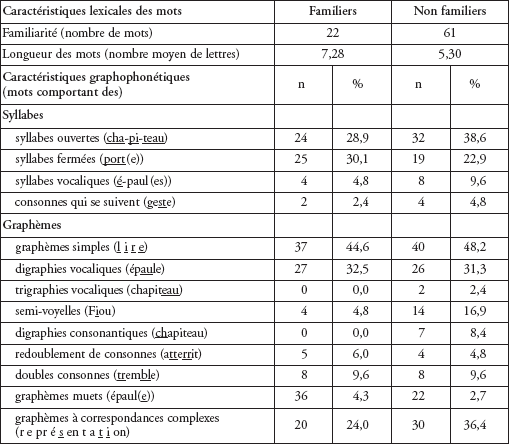
La deuxième série d’analyses visait à vérifier les hypothèses sur l’influence de la familiarité comme indicateur du recours à des stratégies logographiques et de la longueur des mots comme indicateur du recours à des stratégies de décodage sur les scores obtenus par les trois types de lecteurs. On supposait que les lecteurs faibles seraient plus sensibles à la familiarité des mots alors que les lecteurs moyens et forts seraient plus sensibles à la longueur des mots.
Les mots avaient été classés familiers lorsqu’ils faisaient partie du vocabulaire visuel que les enfants avaient étudié en classe. Les comparaisons entre les distributions des scores prises globalement pour les mots familiers et non familiers montrent des différences significatives entre les trois groupes. Toutefois, les comparaisons deux à deux révèlent que si les différences sont toutes significatives pour les mots non familiers, elles ne sont significatives qu’entre les lecteurs moyens et les lecteurs faibles pour les mots familiers (p < 0,000). Il n’y a pas de différence significative entre les lecteurs moyens et les lecteurs forts.
Figure 2
Influence de la familiarité des mots

L’application du test de Wilcoxon sur les différences de scores ajustés entre les mots familiers et non familiers (figure 2) confirme que les scores des trois groupes de lecteurs sont significativement inférieurs pour les mots non familiers (p < 0,000) lorsqu’on les prend globalement. Toutefois, les comparaisons deux à deux montrent que les différences ne sont significatives que pour les lecteurs forts (p < 0,023) et les lecteurs moyens (p < 0,000), la moyenne du test étant supérieure au seuil de signification pour les lecteurs faibles (p > 0,117). Autrement dit, contrairement à ce que prévoyait notre hypothèse, les lecteurs faibles ont eu recours au décodage comme les lecteurs moyens et les lecteurs forts même pour reconnaître les mots familiers. Le fait qu’ils aient éprouvé autant de difficultés à décoder les mots familiers que les mots non familiers montre toutefois qu’ils maîtrisaient moins bien les mécanismes de décodage de base.
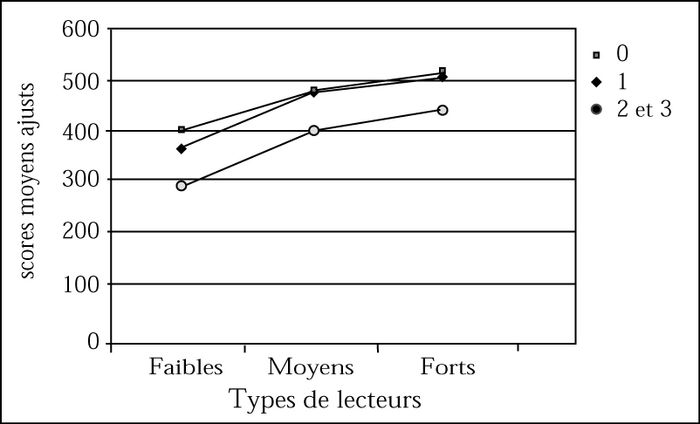
L’influence de la longueur des mots a été mesurée en fonction du nombre de lettres. Les mots ont été divisés en trois catégories : mots longs (9 lettres et +) ; mots moyens (5 à 8 lettres) ; mots courts (2 à 4 lettres). Contrairement à ce qu’on a obtenu pour la familiarité, les différences sont statistiquement significatives entre les distributions des trois catégories de mots pour les trois niveaux de lecteurs globalement. Elles sont également statistiquement significatives quand on compare les lecteurs moyens et les lecteurs faibles pour les trois catégories de mots (p < 0,05). Toutefois, aucune différence significative ne ressort lorsque l’on compare les distributions des scores des lecteurs moyens et forts pour les trois catégories de mots (p > 0,05).
Figure 3
Influence de la longueur des mots

Comme l’illustre la figure 3, les comparaisons entre les scores moyens ajustés confirment qu’ils sont significativement plus faibles pour les mots longs que pour les mots courts, et ce, pour les trois types de lecteurs. Toutefois, les différences entre les mots longs et moyens ne sont statistiquement significatives que pour les lecteurs faibles (p < 0,004). Autrement dit, les lecteurs faibles sont plus sensibles à la longueur des mots que les lecteurs moyens et les lecteurs forts, ce qui confirme qu’ils tentent d’utiliser le décodage mais sans le maîtriser. Ils commencent à éprouver des difficultés dès que les mots ont plus de 5 à 8 lettres, alors que les lecteurs moyens et forts n’ont plus de difficultés qu’avec les mots de 9 lettres et plus.
Influence de la complexité orthographique des mots
Comme l’a confirmé l’analyse des stratégies, à la fin de la première année, les enfants décodent de gauche à droite, syllabe par syllabe. Il était donc acceptable de supposer que la complexité des syllabes influencerait leur performance. Cette hypothèse a été vérifiée en distinguant : 1) les syllabes ouvertes dont on pouvait supposer qu’elles étaient plus simples parce que plus fréquentes en français et 2) les syllabes complexes qui incluaient a) les syllabes fermées « port(e) » et b) les syllabes vocaliques « é-paul(e) ». Les comparaisons entre les trois groupes de lecteurs sont apparues significatives globalement pour les trois catégories de mots (p < 0,005) ainsi que pour les comparaisons entre lecteurs moyens et faibles ; par contre, aucune différence significative n’a été obtenue en comparant les distributions des lecteurs moyens et forts. Lorsque l’on compare, par ailleurs, les scores moyens ajustés globalement et deux à deux, toutes les différences apparaissent significatives dès que les mots comportent plus d’une syllabe complexe, ce qui vaut pour les trois types de lecteurs.
Figure 4
Influence du nombre de syllabes complexes
Le traitement des syllabes est lié aux graphèmes qui les composent, d’où notre hypothèse sur l’influence qu’aurait le nombre de graphèmes complexes dans les mots, qui correspond à ce que Sprenger-Charolles appelle l’effet de régularité des mots. Trois catégories de mots ont été établies : 1) 0 graphème complexe ; 2) 1-2 graphèmes complexes ; 3) 3 graphèmes complexes et plus. Les comparaisons des distributions des scores confirment que toutes les différences sont significatives pour les trois catégories de mots et les trois types de lecteurs pris globalement et deux à deux.
Figure 5
Influence du nombre de graphèmes complexes

Les scores pour les mots ayant 3 graphèmes complexes et plus sont significativement plus petits que les scores pour les deux autres catégories, et ce, pour les trois groupes de lecteurs pris globalement et deux à deux (p < 0,004). Les différences sont significatives pour les lecteurs faibles et les lecteurs forts quand on compare les mots qui ont un graphème complexe à ceux qui n’en ont pas, mais elles ne le sont pas pour les lecteurs moyens.
La complexité des graphèmes est définie par deux dimensions : d’une part, le nombre de lettres qui composent un graphème « o » « au » « eau » ; d’autre part, le nombre de correspondances phoniques pour un même graphème [o] comme dans « chapiteau » vs [ɔ] comme dans « port(e) ». Le fait que [o] peut correspondre à deux phonèmes distincts, c’est-à-dire être prononcé de deux façons différentes, est traité comme des correspondances complexes. Comme pour les autres analyses, les mots ont été regroupés en trois catégories pour vérifier l’influence du nombre de correspondances complexes : 1) les mots qui ne comportent que des correspondances simples comme « Paméla » (0 correspondance complexe) ; 2) les mots qui comportent 1 correspondance complexe « porte » et 3) les mots qui en comportent 2 ou 3 « représentation ». Les différences entre les distributions des scores sont statistiquement significatives entre les trois groupes globalement, mais lorsqu’on les compare deux à deux, les différences ne sont significatives qu’entre les lecteurs faibles et les lecteurs moyens.
Figure 6
Influence du nombre de correspondances complexes
Comme dans le cas des syllabes complexes, les scores sont significativement différents pour les trois groupes de lecteurs entre les mots qui comportent deux ou trois correspondances complexes et ceux qui en comportent une ou zéro, les différences entre les deux dernières catégories n’étant significatives que pour les lecteurs faibles. Autrement dit, les lecteurs faibles éprouvent des difficultés dès qu’il y a une correspondance complexe dans un mot alors que les moyens et les forts en éprouvent seulement pour les mots qui en comportent plus d’une.
Pour tester les hypothèses sur l’influence des lettres et des graphèmes muets, deux catégories de mots ont été établies : 1) ceux qui ne comportent pas de lettre ni de graphème muet et 2) ceux qui en comportent. Les comparaisons entre les trois groupes de lecteurs confirment que les distributions des scores sont différentes pour les trois groupes de lecteurs globalement et deux à deux. Les différences entre les scores sont significativement plus petites quand les mots comportent des lettres et des graphèmes muets globalement ; toutefois, les comparaisons deux à deux ne montrent des différences significatives que pour les lecteurs moyens et forts. On ne peut conclure pour les lecteurs faibles.
Figure 7
Influence du nombre de graphèmes muets

Les scores des mots ayant des lettres et des graphèmes muets sont significativement plus petits pour les trois groupes pris globalement (p < 0,000). Lorsque l’on compare les groupes deux à deux, les différences ne sont toutefois significatives qu’entre les lecteurs moyens (p < 0,001) et les lecteurs forts (p < 0,003). On ne peut conclure pour les lecteurs faibles (p < 0,05).
Interprétation des résultats
Décoder pour comprendre
Le premier constat qui se dégage de cette recherche est qu’à la fin de la première année du primaire, il y a des différences importantes entre les enfants avec certains qui sont déjà des lecteurs autonomes et d’autres qui lisent à peine la moitié des mots d’un texte de leur niveau. Or, comme le montrent les recherches rapportées par Morais (1993) et Pierre (dans ce numéro, p. 3-35), la compréhension est liée à la capacité de reconnaître les mots. Contrairement à ce que prétendaient Goodman et Smith, des enfants qui reconnaissent à peine la moitié des mots d’un texte ne peuvent le comprendre par eux-mêmes et, par conséquent, ils ne peuvent anticiper les mots comme l’illustre la situation reproduite à l’encart 3.
Encart 3
Simulation de la lecture du texte expérimental par un lecteur de première année

Cet exemple simule le type de situation dans laquelle un lecteur de première année de notre recherche s’est retrouvé face au texte qu’il devait lire. Les mots qui sont écrits dans un autre code sont ceux qu’il ne savait pas décoder. Selon Goodman et Smith, cela ne devait pas être un obstacle. L’enfant aurait dû s’appuyer sur les informations que lui donnait le texte pour anticiper les mots qu’il ne reconnaissait pas spontanément et l’anticipation aurait dû lui permettre de les reconnaître globalement. Ce n’est pas ce qui est arrivé, comme le montrent les données rapportées dans cet article. Seulement 4 enfants sur les 44 de la recherche ont deviné des mots et un seul l’a fait à plusieurs reprises. En outre, contrairement à ce que prétendait Goodman (1967, 1969), les mots devinés n’étaient pas des méprises, ils n’étaient même pas proches sémantiquement. Par contre, ils étaient proches graphophonologiquement, ce qui démontre que les enfants essayaient bien de les décoder.
Le deuxième constat de cette recherche est que, malgré l’utilisation d’une approche whole-language, à la fin de la première année, les enfants québécois, tout comme les enfants français vus par Sprenger-Charolles, ont recours au décodage pour reconnaître les mots, mais avec des degrés d’autonomie et d’automatisation variables. Ils sont donc tous au stade alphabétique, mais à des niveaux différents.
Si l’on décompose la figure 2 (figure 8), on peut voir que la progression dans le degré d’autonomie avec lequel les trois groupes de lecteurs ont appliqué les stratégies de décodage est marquée par la différence entre les stratégies 3+2+1 (décodage avec aide) combinées et la stratégie 4 (décodage sans aide). Il ressort ainsi clairement que le passage commence à s’opérer chez les lecteurs moyens et qu’il est à peu près accompli chez les lecteurs forts. La comparaison entre la stratégie 4 et les stratégies 5 et 6 permet, par ailleurs, de montrer la progression dans le degré d’automatisation des stratégies de décodage.
Figure 8
Fréquences d’utilisation des stratégies par les trois types de lecteurs

On peut voir ainsi que sur 83 mots, les lecteurs faibles n’ont pu reconnaître instantanément et sans aide que 29 mots, qu’ils en ont décodé seuls 19, qu’ils ont eu besoin d’aide pour en décoder 25 et qu’ils n’en ont pas reconnu 10 comparativement à 45, 24, 8 et 5 pour les lecteurs moyens et à 53, 24, 5 et 1 pour les lecteurs forts. Autrement dit, alors que les lecteurs faibles amorcent seulement le stade alphabétique, les lecteurs moyens et les lecteurs forts en sortent puisqu’ils chevauchent le stade alphabétique et le stade orthographique en fonction des mots à lire. La différence entre les lecteurs faibles et les deux autres groupes a été significative sur tous les critères considérés, alors que la différence entre les lecteurs moyens et les lecteurs forts s’est surtout manifestée par un niveau moindre d’automatisation des stratégies de décodage et une moins grande autonomie dans leur application de la part des lecteurs moyens.
La différence entre les lecteurs moyens et les lecteurs forts s’est révélée particulièrement au niveau du traitement des lettres et des graphèmes muets que les lecteurs moyens oralisaient systématiquement « bouge » alors que les lecteurs forts lisaient les mots comme ils les auraient dits à l’oral [buʒ]. Le traitement des graphèmes morphologiques qui, en français, sont muets – mais qui s’expriment dans les liaisons – « son épaule bouge » par rapport à « ses épaules bougent » exige le recours à des stratégies orthographiques. Avant que les enfants n’aient une connaissance explicite des règles syntaxiques et morphologiques qui régissent les règles de décodage des morphèmes grammaticaux, la seule façon pour eux de reconnaître les mots est de pouvoir activer dans leur lexique mental une représentation de la racine du mot « bouge » en lui appliquant une règle contextuelle fonctionnelle du genre : chaque fois qu’il y a un « les » devant un mot, il y a un « s » à la fin du mot et on ne le prononce pas. Cela suppose que les enfants sachent opérer des traitements différents en parallèle, ce qui est la marque du stade orthographique.
Le passage au stade orthographique des lecteurs forts est aussi confirmé par le fait qu’ils sont davantage capables que les deux autres groupes de traiter les correspondances complexes, sans toutefois en avoir maîtrisé toutes les difficultés. Le fait qu’ils soient capables instantanément, en lisant des mots comme « geste » ou « représentation », d’associer le bon phonème à un graphème qui peut correspondre à deux phonèmes différents, témoigne qu’ils ont commencé à construire un lexique mental qui leur permet d’activer la représentation du mot directement dans leur mémoire, sans passer par la médiation phonologique [13], du moins dans le cas de mots familiers (Morton, 1989). Dans le cas de mots non familiers, certains auteurs supposent que la correspondance est établie par analogie avec des mots qui posent les mêmes problèmes et qui font déjà partie de leur lexique mental (Sebastian et Vacciano, 1995). On se trouve donc là face à des stratégies de plus haut niveau qui témoignent de l’accès au stade orthographique. Or, pour pouvoir appliquer tous ces traitements en parallèle, il faut que les mécanismes de décodage soient automatisés (Morais, Pierre et Kolinsky, dans ce numéro).
Ainsi, contrairement à ce que suppose le modèle québécois, même avec une approche whole-language, le passage au stade orthographique ne se fait pas directement à partir du stade logographique. Autrement dit, les mots ne se fixent pas dans la mémoire des enfants à force de les regarder ou à force que d’autres les lisent pour eux. La preuve en est que les lecteurs faibles n’ont même pas reconnu plus facilement les mots qui auraient dû leur être familiers, c’est-à-dire les mots qu’ils avaient vus probablement très souvent en classe puisqu’ils faisaient partie des étiquettes-mots dans leurs méthodes de lecture. Si les lecteurs moyens et forts ont eu plus de facilité à les reconnaître, c’est parce qu’ils savaient les décoder et que ces mots faisaient partie de leur lexique mental (Ehri, 1997). Autrement dit, contrairement à ce que suppose le modèle québécois, les stratégies de décodage ne sont pas des stratégies de dépannage qu’on peut appliquer de façon facultative quand les stratégies d’anticipation ne fonctionnent pas.
De même, les enfants ne peuvent apprendre les stratégies de décodage au hasard des mots qu’ils rencontrent. Comme le confirme également la présente recherche, la complexité orthographique des mots détermine une progression dans l’apprentissage du décodage.
Tableau 5
Mots qui ont obtenu les scores les plus et les moins élevés parmi les mots familiers et non familiers (83 mots)

Comme cela apparaît au tableau 5, les mots qui ont obtenu les scores les plus élevés sont des mots d’une syllabe, qu’ils soient familiers ou non, alors que les mots qui ont obtenu les scores les plus faibles sont des mots de plus de deux syllabes qui comportent soit des syllabes complexes, des graphèmes complexes, des correspondances complexes ou des graphèmes muets. Le fait que des mots comme « porte » « perdu » « pied » « épaule » et « botte », qui sont des mots courts et très familiers à l’oral et à l’écrit, aient posé autant de problèmes à tous les enfants, mais particulièrement aux lecteurs faibles, est en soi une preuve que le décodage est une stratégie d’apprentissage. Après trente ans d’expérience à observer des enfants du préscolaire et du premier cycle du primaire, nous avons de bonnes raisons de penser que la plupart des enfants reconnaissaient ces mots globalement en maternelle et au début de la première année, du moins dans des contextes appropriés. S’ils ne les reconnaissent plus à la fin de la première année, c’est parce que le besoin d’apprendre à décoder a pris le pas sur la reconnaissance globale, comme on peut le vérifier en observant ces enfants lire sur les vidéos. Contrairement à ce que suppose le modèle québécois, leur « stratégie d’attaque des mots », comme disent les Américains, est spontanément le décodage. Le problème, c’est qu’ils n’ont pas les connaissances sur le code qui leur seraient nécessaires pour décoder. Les mots « porte » et « botte », si familiers qu’ils soient, comportent chacun trois complexités orthographiques sur 6 lettres : une syllabe fermée « port » « bot », une correspondance complexe (le graphème < o > qui se dit [o] comme dans « mot » ou [ɔ] comme dans « orange », deux consonnes qui se suivent dans le cas de « porte » et un redoublement de consonnes dans le cas de « botte », ce qui explique qu’ils se situent respectivement au 32e et au 78e rang sur 83 mots. Quant au mot « é-pau-le », la difficulté qu’il pose est attribuable surtout au fait qu’il débute par une syllabe vocalique, ce avec quoi les enfants de première année ont encore beaucoup de difficultés en raison, entre autres, des problèmes de liaisons qui leur sont associés « unépaule » par rapport à « dezépaules ». La difficulté du mot « pied », très familier, 4 lettres, vient d’une part de la semi-voyelle [j] qui correspond au graphème i, du graphème « e » qui se prononce « e » comme le « é » de « épaule » et du « d » qui est un graphème morphologique muet qui permet de rappeler le lien sémantique avec les mots qui ont la même racine « piédestal ».
Ainsi, à partir de nos résultats, on peut dire que les enfants de la fin de la première année savent relativement bien décoder des mots d’une et deux ou trois syllabes, qu’ils soient familiers ou non, lorsque les syllabes sont ouvertes. Toutefois dès que les mots comportent plus de trois syllabes, ils commencent à éprouver des difficultés et c’est là que les lecteurs faibles se différencient des deux autres groupes. Les difficultés s’amplifient lorsque les mots comportent des syllabes et des graphèmes complexes et plus ils en comportent plus les lecteurs moyens se différencient des lecteurs forts. Le niveau supérieur de difficulté serait la capacité de décoder des mots qui comportent plus d’une syllabe complexe, plus de trois graphèmes complexes, plus d’une correspondance complexe et des graphèmes muets.
Conclusion
On ne peut certes pas, à partir de cette seule recherche, conclure sur l’inefficacité des méthodes québécoises. Là n’était pas notre intention. Toutefois en se référant aux recherches de Sprenger-Charolles, on peut tout au moins constater que les enfants québécois n’apprennent pas différemment des enfants français et qu’un certain nombre d’entre eux ne sont pas au stade où ils devraient être pour amorcer la deuxième année. À la lumière des recherches existantes, on peut penser que cela tient à des facteurs cognitifs, sociaux et linguistiques mais aussi à des facteurs didactiques liés à l’approche whole-language.
Bien qu’on le prétende constructiviste (programme 1979) ou socioconstructiviste (curriculum 2000), le modèle québécois ne tient pas compte des facteurs de développement qui conditionnent l’apprentissage de la lecture. Les enfants d’aujourd’hui commencent à apprendre à lire bien avant de commencer leur première année et le niveau de développement qu’ils ont atteint à ce moment-là est déterminant pour la suite de l’apprentissage. Il est fort probable, comme l’ont montré d’autres recherches, que les lecteurs forts avaient déjà un niveau élevé de conscience de l’écrit et de conscience phonologique à leur entrée en première année (Bruck, Genesee et Caravolas, 1997 ; De Jong et Van Der Leij, 1999 ; Goswami, 1999 ; Morais, Moutsy et Kolinsky, 1998 ; Perfetti, Beck, Bell et Hughes, 1988 ; Scallon et Vellutino, 1996 ; Share, 1995 ; Snow, Burns et Griffin, 1998). Comme l’a montré Stanovich (1986), par ailleurs, on peut penser, sans risque de se tromper, que c’est là que le fossé a commencé à se creuser avec les lecteurs faibles.
Le second problème du modèle québécois est qu’il est fondé sur un modèle didactique qui avait été conçu pour l’anglais en reprenant les mêmes arguments. S’il est possible, comme le suppose Seymour (1997), qu’en raison des caractéristiques du système orthographique de l’anglais, on soit justifié d’accorder une certaine importance aux stratégies logographiques, le même raisonnement ne peut s’appliquer pour le français. S’il est vrai, par ailleurs, comme l’écrivait Smith (1972) que le système orthographique de l’anglais est très complexe, il est faux de croire comme Giasson et Thériault (1983) que les enfants francophones doivent apprendre plus de 500 règles de décodage pour apprendre à lire. Il est encore plus faux d’affirmer, comme Foucambert (1976), que le système d’écriture du français est un système idéographique. Le système orthographique du français est un système alphabétique et il est différent de celui de l’anglais.
Mais l’erreur la plus fondamentale du modèle québécois est de confondre la lecture et la compréhension. S’il est vrai que le but fonctionnel de la lecture est la compréhension, ce que personne ne met en doute, on ne peut plus croire aujourd’hui que la lecture découle de la compréhension ni même qu’elle soit dépendante de la compréhension. On peut très bien savoir lire un texte qu’on ne comprend pas, mais on ne comprendra jamais un texte qu’on ne sait pas lire, à moins que quelqu’un d’autre le lise pour nous. Par ailleurs, il n’est pas plus vrai qu’on apprend à lire en apprenant à comprendre qu’il n’était vrai qu’on apprenait à comprendre en apprenant à décoder, comme on le pensait dans les méthodes antérieures à 1979. Le rôle de la compréhension est d’extraire les connaissances que l’auteur a injectées dans le texte pour les intégrer dans nos structures de connaissances. Le rôle de la lecture est de décoder les mots de façon à pouvoir les reconnaître pour leur attribuer un sens. La lecture est nécessaire parce que le médium choisi par l’auteur est celui de l’écriture et que contrairement à ce que suppose le modèle québécois, l’écriture n’est pas transparente et elle n’est pas qu’une simple transposition de l’oral (Pierre, 2003). L’écriture est un code et comme tout code, elle est fondée sur des conventions qu’il faut connaître pour pouvoir la déchiffrer.
Est-ce à dire pour autant qu’il faille avoir, d’un côté, des méthodes qui enseignent le décodage et, de l’autre, des méthodes qui enseignent la compréhension, comme on commence à le voir apparaître avec le développement de matériels d’appoint centrés sur le décodage ? Nous ne le pensons pas, mais cela reste à démontrer. Est-ce à dire qu’il faille d’abord enseigner le décodage et attendre que les enfants sachent lire pour commencer à enseigner la compréhension, comme on le faisait avant la réforme de 1979 ? Nous ne le pensons pas, mais cela reste à prouver. Ce dont nous sommes certaine toutefois, c’est que le contexte et les conditions d’apprentissage de la lecture sont différents de ce qu’ils étaient il y a trente ans et que nous en savons bien plus aujourd’hui qu’au moment où Smith et Goodman ont conçu leur modèle. Beaucoup de questions qui relevaient, il y a trente ans, de la pure spéculation ont été tranchées empiriquement et font désormais l’objet d’un large consensus parmi les scientifiques. Perpétuer ce modèle, c’est perpétuer la croyance, qui domine encore au Québec, selon laquelle on peut réformer le curriculum scolaire sans tenir compte des spécificités des contenus d’enseignement, des contraintes didactiques qui pèsent sur leur apprentissage et des connaissances scientifiques qui fondent les didactiques des disciplines.
Appendices
Notes
-
[1]
Le mot préalable est, comme les mots enseignement, méthode, systématique, un de ces mots tabous chargés de mythes qu’on exclut, depuis la réforme de 1979, de tout discours pédagogiquement accepté.
-
[2]
On parle encore de correspondances lettres-sons et non graphèmes-phonèmes avec toutes les confusions que cela entraîne.
-
[3]
Ces deux types de stratégies qui reflètent des niveaux différents sont confondus dans les programmes et les méthodes québécoises.
-
[4]
On pourrait faire la même analyse au sujet de la compréhension. Ainsi, l’une des croyances qui entourent la compréhension est que les enfants du premier cycle ne peuvent construire des connaissances implicites, ce que nous avons démenti dans une recherche antérieure (Pierre et Lavoie, 1992). Pourtant, au niveau 4, on précise bien que les enfants ne peuvent extraire que les informations explicites, comme s’il était possible de comprendre quelque texte que ce soit sans en extraire aussi les connaissances implicites.
-
[5]
Voir, à titre d’exemple, le curriculum français qui distingue clairement les deux pôles de l’apprentissage de la lecture et qui fait de l’apprentissage du premier l’objectif prioritaire des deux premiers cycles scolaires (l’équivalent au Québec de la maternelle et des deux premières années du primaire) : «Apprendre à lire, c’est apprendre à mettre en jeu en même temps deux activités très différentes : 1) celle qui conduit à identifier des mots écrits, 2) celle qui conduit à en comprendre la signification dans le contexte verbal (textes) et non verbal (supports des textes, situation de communication) qui est le leur. La première activité, seule, est spécifique de la lecture. La seconde n’est pas très dissemblable de celle qui porte sur le langage oral, même si les conditions de communication à l’écrit diffèrent (absence d’interlocuteur, permanence du message) et si la langue écrite comporte des spécificités de syntaxe, de lexique ou textuelles, assez rarement présentes à l’oral. » < http://www.education.gouv.fr/bo/2002/hs1/default.htm >.
-
[6]
Graphème : lettre ou groupe de lettres correspondant à un phonème à l’oral : < ch > < a > < p > < eau >.
-
[7]
Phonème : la plus petite unité sonore distinctive dans une langue donnée (pain, main, saint, rein, lin, et autres).
-
[8]
On parle ici de contexte linguistique comme la place du graphème dans le mot et les graphèmes avoisinants qui déterminent le statut d’un graphème comme dans le cas du « g » dur et du « g » doux.
-
[9]
Cela s’explique sans doute par le fait qu’en France, contrairement au Québec, le ministère de l’Éducation nationale n’impose pas les méthodes d’enseignement. Il considère que le choix des méthodes relève de l’expertise des enseignants.
-
[10]
Pour être retenus, les enfants devaient avoir lu au moins cinq mots.
-
[11]
Les analyses ont été effectuées par Mané Yaya, Ph. D. en didactique et assistant de recherche du Groupe de recherche sur l’alphabétisation et l’acquisition de la littératie (GRAAL).
-
[12]
Les analyses statistiques ont été réalisées par Nathalie Loye, étudiante à la maîtrise en mesure et évaluation sous la supervision de Jean-Guy Blais, professeur titulaire à la Faculté des sciences de l’éducation de l’Université de Montréal.
-
[13]
Synonyme de décodage.
Références
- Adams, M.J. (1990). Beginning reading : Learning and thinking about print. Cambridge, MA : MIT Press.
- Alegria, J., Leybaert, L. et Mousty, P. (1994). Acquisition de la lecture et troubles associés. In J. Grégoire et B. Piérard (dir.), Évaluer les troubles de la lecture (p. 105-127). Bruxelles : De Boeck.
- Barron, R.W. (1986). Word recognition in early reading : A review of the direct and the indirect access hypothesis. Cognition,24, 93-113.
- Bastien, C. et Bastien-Tognazzo, M. (1993). L’importance de la zone dite logographique dans l’acquisition de la lecture. In J.-P. Jaffré, L. Sprenger-Charolles et M. Fayol (dir.), Lecture-écriture : acquisition. Les actes de La Villette (p. 163-176). Paris : Nathan.
- Blachman, B.A. (1991). Phonological awareness. Implications for prereading and early reading instruction. In S.A. Brady et D.P. Shankwiller (dir.), Phonological processes in literacy. A tribute to Isabelle Y. Liberman (p. 29-36). Hillsdale, NJ : Lawrence Erlbaum.
- Bruck, M., Genesee, F. et Caravolas, M. (1997). A cross-linguistic study of early literacy acquisition. In B.A. Blachman (dir.), Foundations of reading acquisition and dyslexia. Implications for early intervention (p. 145-162). Hillsdale, NJ : Lawrence Erlbaum.
- Cadosso-Martin, C. (1995). Sensitivity to rhymes, syllables and phonemes in literacy acquisition in Portuguese. Reading Research Quarterly, 30, 808-828.
- Cambourne, B. (1982). Getting to Goodman. In K.S. Goodman (dir.), Language and literacy. The selected writings of Kenneth S.Goodman (Tome 1 – Process, theory and research, p.185-215). Boston, MA : Routledge et Kegan.
- Catach, N. (1980). L’orthographe française. Traité théorique et pratique. Paris : Nathan.
- Chall, J.S. (1967). Learning to read : The great debate. New York, NY : McGraw-Hill.
- Chall, J.S. (1999). Commentary : Some thoughts on reading research. Revisiting the first-grades studies. Reading Research Quarterly, 1(34), 8-12.
- Chomsky, N. (1979). Aspects de la théorie syntaxique. Paris : Éditions du Seuil.
- Conover, W.J. (1971). Practical nonparametric statistics. New York, NY : John Wiley and Sons.
- Content, A. et Leybert, J. (1992). L’acquisition de la lecture : influence des méthodes d’apprentissage. In P. Lecoq (dir.), La lecture. Processus, apprentissage, troubles (p. 181-213). Lille : Presses universitaires de Lille.
- Cossu, G., Schankwiller, D., Liberman, I.Y., Tola, G. et Katz, L. (1988). Awareness of phonological segments and reading ability in Italian children. Applied Psycholinguistics, 9,1-16.
- Cossu, G., Gugliotta, M. et Marshall, J.C. (1995). Acquisition of reading and written spelling in a transparent orthography : Two non-parallell processes ? Reading and Writing : An Interdisciplinary Journal, 7, 9-22.
- Dahl, K.L., Scharer. P.L., Lawson, L.L. et Grogan, P.R. (1999). Phonics instruction and student-achievement in whole-language first-grade classrooms. Reading Research Quarterly, 34(3), 312-341.
- De Jong, P.F. et Van Der Leij, A. (1999). Specific contributions of phonological abilities to early reading acquisition : Results from a Dutch latent variable longitudinal study. Journal of Educational Psychology, 91, 450-476.
- DeFrancis, J. (1989). Visible speech : The diverse oneness of writing systems. Honolulu, HA : University of Hawaï Press.
- Dejean De La Batie, B. et Bradley, D.C. (1995). Resolving word boundaries in spoken French : Native and non-native strategies. Applied Psycholinguistics, 16, 59-81.
- Delattre, P. (1940). Le mot est-il une entité phonique en français ? Le français moderne, 8, 47-56.
- Delattre, P. (1947). La liaison en français : tendances et classification. The French Review, 21, 148-157.
- Delattre, P. (1965). Comparing the phonic features of English, French, German, and Spanish. Heidelberg : Junius Gross Verlag.
- Delattre, P. (1966). Studies in French and comparative phonetics. La Haye : Mouton.
- Doctor, E. et Coltheart, M. (1980). Phonological recoding in children’s reading for meaning. Memory and Cognition, 80, 195-209.
- Ducart, D., Honvault, R. et Jaffré, J.P. (1995). L’orthographe en trois dimensions. Paris : Nathan.
- Ehri, L.C. (1991). Learning to read and spell words. In L. Rieben et C.A. Perfetti (dir.), Learning to read : Basic research and its implications (p. 57-73). Hillsdale, NJ : Lawrence Erlbaum.
- Ehri, L.C. (1992). Reconceptualizing the development of sight word reading and its relationship to recoding. In P. Gough, L. Ehri et R. Treiman (dir.), Reading acquisition (p. 107-145). Hillsdale, NJ : Lawrence Erlbaum.
- Ehri, L.C. (1997). Sight word learning in normal readers and dyslexics. In B.A. Blachman (dir.), Foundations of reading acquisition and dyslexia. Implications for early intervention (p. 163-190). Mahwah, NJ : Lawrence Erlbaum.
- Ehri, L.C. (1999). Phases of development in learning to read words. In J. Oakhill et R. Beard (dir.), Reading development and the teaching of reading : A psychological perspective (p. 79-108). Oxford, UK : Blackwell Science.
- Ehri, L.C. (2000). Learning to read and learning to spell : Two sides of a coin. Topics in Language Disorders, 20(3), 10-36.
- Foucambert, J. (1976). La manière d’être lecteur. Apprentissage et enseignement de la lecture de la maternelle au CM 2. Paris : SERMAP.
- Freppon, P.A. et Dahl, K.L. (1991). Learning about phonics in a whole-language classroom. Language Arts, 68(3), 190-197.
- Freppon, P.A. et McIntyre, E. (1999). A comparison of young children learning to read in different instructional settings. Journal of Educational Research, 92(4), 206-218.
- Frith, U. (1985). Beneath the surface of developmental dyslexia. In K.E. Patterson, J.C. Marshall et M. Coltheart (dir.), Surface dyslexia : Neuropsychological and cognitive studies of phonological reading (p. 301-330). London : Lawrence Erlbaum.
- Frith, U. (1986). A developmental framework for developmental dyslexia. Annals of Dyslexia, 36, 69-81.
- Gaouette, D. (1999). En-Tête. Première année. Guide d’enseignement (2e édition). Montréal : Éditions du renouveau pédagogique.
- Giasson, J. et Thériault, J. (1983). Apprentissage et enseignement de la lecture. Montréal : Éditions Ville-Marie.
- Goodman, K.S. (1967). Reading : A psycholinguistic guessing game. Journal of the Reading Specialist, 6(4), 126-135.
- Goodman, K.S. (1969). Analysis of oral reading miscues : Applied psycholinguistics. Reading Research Quarterly, 5, 9-30.
- Goswami, U. (1999). The relationship between phonological awareness and orthographic representation in different orthographies. In M. Harris et G. Hatano (dir.), Learning to read and write : A cross-linguistic perspective (p. 134-156). Boston, MA : Cambridge University Press.
- Goswami, U., Gombert, J.E. et De Barrera, L.F. (1998). Children’s orthographic representations and linguistic transparency : Nonsense word reading in English, French, and Spanish. Applied Psycholinguistics, 19(1), 19-52.
- Gough, P.B. (1993). The beginning of decoding. Reading and Writing : An Interdisciplinary Journal, 5(2), 181-192.
- Gough, P., Juel, C. et Griffith, P.L. (1992). Reading, spelling and the orthography cipher. In P. Gough, L. Ehri et R. Treiman (dir.), Reading acquisition (p. 35-48). Hillsdale, NJ : Lawrence Erlbaum.
- Gouvernement du Québec (1979). Programme d’études. Primaire. Français. Québec : Ministère de l’Éducation.
- Gouvernement du Québec (2001). Programme de formation de l’école québécoise. Éducation préscolaire. Québec : Ministère de l’Éducation.
- Gouvernement du Québec (2002a). Échelle des niveaux de compétences. Enseignement primaire. Québec : Ministère de l’Éducation.
- Gouvernement du Québec (2002b). L’évaluation des apprentissage au préscolaire et au primaire. Québec : Ministère de l’Éducation.
- Guillemette,S., Létourneau, G. et Raymond, N. (1989). Mémo. Boucherville : Graficor.
- Harris, M. et Coltheart, M (1986). Language processing in children and adults : An introduction. Londres : Routledge et Kegan.
- Kintsch, W. et van Dijk, T. (1983). Towards a model of text comprehension and production. Psychological Review, 85, 363-394.
- McBride-Chang, C. (1999). The ABCs of the ABCs : The development of letter-name and letter-sound knowledge. Merrill-Palmer Quarterly, 45(2), 285-308.
- McIntyre, E. et Freppon, P.A. (1998). A comparison of children development of alphabetic knowledge in a skills-based and a whole-language classroom. In C. Weaver (dir.), Reconsidering a balanced reading approach (p. 181-209). Urbana, IL : National Council of Teachers of English.
- McQuillan, J. (1998). The literacy crisis. False claims, real solutions. Portsmouth, NH : Heinemann.
- Mettoudi, C. et Yaïche, A. (1993). Travailler par cycle en français à l’école de la petite section au CM 2. Paris : Hachette.
- Morais, J. (1993). Compréhension/décodage et acquisition de la lecture. In J.P. Jaffré, L. Sprenger-Charolles et M. Fayol (dir.), Lecture-écriture : acquisition. Les actes de La Villette (p. 10-21). Paris : Nathan.
- Morais, J., Cary, L., Alegria, J. et Bertelson, P. (1979). Does awareness of speech as a sequence of phones arise spontaneously ? Cognition, 7, 323-331.
- Morais, J., Mousty, P. et Kolinsky, R. (1998). Why and how phoneme awareness helps learning to read. In C. Hulme et R.M. Joshi (dir.), Reading and spelling : Development and disorders (p. 127-152). Mahwah, NJ : Lawrence Erlbaum.
- Morton, J. (1989). An information-processing account of reading acquisition. In A.M. Galaburda (dir.), From reading to neurones : Issues in the biology of language and cognition (p. 43-66). Cambridge, MA : Bradford Book/MIT Press.
- Perfetti, C.A., Beck, I., Bell, L.C. et Hughes, C. (1988). Phonemic knowledge and learning to read are reciprocal : A longitudinal study of first grade children. In K.E. Stanovich (dir.), Children’s reading and the development of phonological awareness (p. 39-75). Détroit, MI : Wayne State University Press.
- Pierre, R. (2003). Entre alphabétisation et littératie : les enjeux didactiques. Revue française de linguistique appliquée, VIII(1), 121-136.
- Pierre, R. (à paraître). L’enseignement de la lecture d’hier à demain. Fondements des méthodes d’enseignement de la lecture. Québec : Presses de l’Université Laval.
- Pierre, R. et Lavoie, M. (1992). Apprendre à comprendre en première année. Scientia paedagogica experimentalis, XXIX(I), 99-119.
- Rack, J., Hulme, C., Snowling, M. et Wightman, J. (1994). The role of phonology in young children learning to read words : The direct mapping hypothesis. Journal of Experimental Child Psychology, 57, 42-71.
- Readance, J.E. et Baron, D.M. (dir.) (1997). Revisiting the first grade studies. Reading Research Quarterly, 32(4).
- Scallon, D.M. et Vellutino, F. R. (1996). Prerequisite skills, early instruction, and success in first grade-reading : Selected results from a longitudinal study. Mental Retardation and Developmental Research Review, 2, 54-63.
- Sebastian, N. et Vacciano, A. (1995). The development of analogical reading in Spanish. Reading and Writing, 7, 23-38.
- Seidenberg, M.S., Waters, G.S., Barnes, M.A. et Tannenbaum, M.K. (1984). When does irregular spelling or prononciation influence word recognition ? Journal of Verbal Learning and Verbal Behavior, 23, 383-404.
- Seymour, P.H.K. (1994). Level of phonological awareness and learning to read. Reading and Writing, 6, 221-250.
- Seymour, P.H.K. (1997). Les fondations du développement orthographique et morphographique de l’anglais. In L. Rieben, M. Fayol et C.A. Perfetti (dir.), Des orthographes et leur acquisition (p. 319-337). Lausanne : Delachaux et Niestlé.
- Share, D.L. (1995). Phonological recoding and self-teaching : Sine qua non of reading acquisition. Cognition, 55, 151-218.
- Siegel, L.S. (1998). Phonological processing deficits and reading disabilities. In J.L. Metsala et L.C. Ehri (dir.), Word recognition in beginning literacy (p. 141-160). Mahwah, NJ : Lawrence Erlbaum.
- Smith, F. (1971). Understanding reading. A psycholinguistic analysis of reading and learning to read. New York, NY : Holt, Rinehart and Winston.
- Smith, F. (1975a). The role of prediction in reading. Elementary English, 52(3), 305-311.
- Smith, F. (1975b). Comprehension and learning. New York, NY : Holt, Rinehart and Winston.
- Snow, C., Burns, S. et Griffin, P. (1998). Preventing reading difficulties in young children. Commission of behavioral and social sciences and education. Washington, DC : National Research Council/National Academy Press.
- Sprenger-Charolles, L. (1992). L’évolution des mécanismes d’identification des mots. In M. Fayol, J.E. Gombert, P. Lecoq, L. Sprenger-Charolles et D. Zagar (dir.), Psychologie cognitive de la lecture (p. 107-140). Paris : Presses universitaires de France.
- Sprenger-Charolles, L., Béchennec, D. et Lacert, P. (1998). Place et rôle de la médiation phonologique dans l’acquisition de la lecture/écriture en français. Revue française de pédagogie, 122, 51-67.
- Sprenger-Charolles, L., Siegel, L.S. et Béchennec, D. (1997). Beginning reading and spelling acquisition in french :A longitudinal study. In C.A. Perfetti, M. Fayol et L. Rieben (dir.), Learning to read and spell. Research, theory and practice (p. 339-359). Hillsdale. NJ : Lawrence Erlbaum.
- Stanovich, K.E. (1986). Matthew effects in reading : Some consequences of individual differences in the acquisition of literacy. Reading Research Quarterly, 21(4), 360-406.
- Stanovich, K.E. (1991). Word recognition : Changing perspective. In R. Barr, M. Kamil, P. Mosenthal et D. Pearson (dir.), Handbook of reading research (Tome 2, p. 418-453). New York, NY : Longman.
- Stanovich, K.E. (1998). Twenty-five years of research on the reading process : The grand synthesis and what it means for our field. National Reading Conference Yearbook, 47, 44-58.
- Stanovich, K.E., Siegel, L.S., Gottardo, A., Chiappe, P. et Sidhu, R. (1997). Subtypes of developmental dyslexia : Differences in phonological and orthographic coding. In B.A. Blachman (dir.), Foundations of reading acquisition and dyslexia (p. 115-141). Mahwah, NJ : Lawrence Erlbaum.
- Stanovich, P.J. et Stanovich, K.E. (1997). Research into practice in special education. Journal of Learning Disabilities, 30(5), 477-481.
- Vellutino, F.R. (1991). Introduction to three studies on reading acquisition : Convergent findings on theoretical foundations of code-oriented vs whole-language approaches to reading instruction. Journal of Educational Psychology, 83, 437-443.
- Vellutino, F.R. et Scallon, D. (1991). The preeminence of phonologically-based skills in learning to read. In S.A. Brady et D.P. Shankwiller (dir.), Phonological processes in literacy. A tribute to Isabelle Y. Liberman (p. 237-252). Hillsdale, NJ : Lawrence Erlbaum.
- Vellutino, F.R., Scallon, D. et Sipay, E.R. (1997). Toward distinguishing between cognitive and experiential deficits as primary sources of difficulty in learning to read : The importance of early intervention in diagnosing specific reading disability. In B.A. Blachman (dir.), Foundations of reading acquisition and dyslexia : Implications for early intervention (p. 145-162). Hillsdale, NJ : Lawrence Erlbaum.
- Vygotsky, L.S. (1978). Mind in society. The development of psychological processes. Cambridge : Harvard University Press.
- Weaver, C. (1998). Experimental research : On phonemic awareness and whole-language. In C. Weaver (dir.), Reconsidering a balanced-reading approach to reading (p. 321-373). Urbana, IL : National Council of Teachers of English.
- Wimmer, H. (1997). How learning to spell German differs from learning to spell English. In C.A. Perfetti et L. Rieben (dir.), Learning to spell : Research, theory, and practice across languages (p. 81-96). Hillsdale, NJ : Lauwrence Erlbaum.
- Wimmer, H. et Hummer, P. (1990). How German speaking first graders read and spell : Doubts on the importance of the logographic stage. Applied Psycholinguistics, 11, 349-368.
- Wimmer, H. et Goswami, U. (1994). The influence of orthographic consistency on reading development. Word recognition in English and in German children. Cognition, 51, 91-103.
List of figures
Encart 1
Critères d’évaluation de la compétence 1 : «Lire des textes variés »
Encart 2
Texte expérimental
Figure 1
Fréquences d’utilisation des stratégies par les trois types de lecteurs
Figure 2
Influence de la familiarité des mots
Figure 3
Influence de la longueur des mots
Figure 4
Influence du nombre de syllabes complexes
Figure 5
Influence du nombre de graphèmes complexes
Figure 6
Influence du nombre de correspondances complexes
Figure 7
Influence du nombre de graphèmes muets
Encart 3
Simulation de la lecture du texte expérimental par un lecteur de première année
Figure 8
Fréquences d’utilisation des stratégies par les trois types de lecteurs
List of tables
Tableau 1
Distribution des mots selon les variables retenues pour l’analyse des résultats
Tableau 2
Caractéristiques des sujets
Tableau 3
Répartition des trois types de lecteurs selon le matériel didactique utilisé
Légende : TL (types de lecteurs) ; Fa (élèves faibles), Mo (élèves moyens), Fo (élèves forts) ; M.A. (matériels d’appoint), C.M. (combinaison de méthodes) ; T (Total), Auc. info (aucune information).
Tableau 4
Critères d’évaluation des stratégies de reconnaissance des mots
Tableau 5
Mots qui ont obtenu les scores les plus et les moins élevés parmi les mots familiers et non familiers (83 mots)