
Abstracts
Résumé
L’Algérie, caractérisée par un climat semi-aride, est menacée par l’érosion des terres agricoles qui provoque l’augmentation du transport solide et l’envasement croissant des barrages. Cet article décrit une nouvelle méthode d’estimation des flux de matières en suspension (MES) au niveau d’un barrage algérien (barrage de Beni Amrane) basée sur la logique floue. Cette dernière utilise des termes flous tels que « faible », « moyen » et « élevé », pour décomposer le processus débit-MES en plusieurs sous-ensembles flous et d’en déduire les quantités de matières solides en fonction du débit observé de la rivière. Les performances de cette méthode ont été évaluées en période de calage, mais aussi en période de validation, pour mieux juger de la capacité prédictive du modèle à ces deux échelles. En comparant la logique floue avec un modèle empirique régressif utilisant une relation de puissance, nous avons démontré la robustesse du modèle flou en tant qu’outil de quantification du transport solide.
Mots clés:
- érosion,
- transport solide,
- modèle empirique,
- logique floue,
- barrage de Beni Amrane,
- Algérie
Summary
Sediment transport and erosion is a complex natural process that is strongly influenced by human activities such as deforestation, agriculture and urbanization. In particular, suspended sediments play a key role in controlling water quality and they can cause a major reduction in the capacity of a stream for handling floods. In Algeria, increasing erosion and suspended loads are responsible for serious problems in agricultural land and hydraulic reservoirs, since the suspended load and its sedimentation lead to flooding and dam silting. Water and soil conservation practices, such as contour ridges and areas of reforestation, were introduced in many regions of Algeria in order to decrease erosion and to collect runoff in hill-slope catchments.
Relationships for water discharge and suspended sediment load can be divided into three types: empirical models that allow quantification of erosion on annual time scales, such as the Wischmeier and Smith soil loss equation; conceptual models, which include several reservoirs estimating sediment load on different time scales; and finally, physically-based models, which introduce physical laws such as the Saint-Venant equation. These models represent another category, and allow the estimation of sediment load in different areas of the watershed and supply spatial results. These models also take into account numerous variables that are difficult to obtain on a regional scale.
The objective of this research was to develop runoff-suspended sediment models for the Beni Amrane reservoir. This reservoir is located in the Isser watershed, situated in northern Algeria. This basin covers an area of 4,000 km2 and is characterized by a semi-arid climate and a very high soil erosion rate, exceeding 2,000 tons/km2/year. The Beni Amrane reservoir represents an important dam as it supplies the Keddara dam, which in turn supplies the town of Algiers with drinking water.
In the present study, two approaches to suspended sediment simulation were applied on hourly time scales for suspended sediment concentrations, and on daily time scales for water discharge and solid discharge analysis. The first approach is an empirical regression model based on a rating curve and uses a relationship between the observed runoff and the sediment concentration values. The model uses only two parameters, with the second being based on fuzzy logic. Fuzzy logic is already used in many scientific domains, and represents a new simulation technique based on artificial intelligence. Fuzzy variables were used to organize knowledge that is expressed ‘linguistically’ into a formal analysis (for example ‘high suspended sediment’, ‘average suspended sediment’ and ‘low suspended sediment’). The simulation results confirm the performances and robustness of the fuzzy logic model for the two time scales. In fact, the Nash criterion, which is the principal validation criterion for the models, displayed high performances in calibration and validation periods. The neurofuzzy model (fuzzy logic with neural supervised learning) offers a simulation advantage. On an hourly time scale, while increasing the number of fuzzy rules, the model results in good precision with the observed suspended sediments.
The fuzzy logic model results showed that the Nash criterion for two periods (calibration and validation) was greater than 88%, and the peaks of suspended sediments were generally correctly reproduced for the four episodes studied. This is in contrast to the empirical model, where the Nash efficiency was generally weak and decreased during the validation period. In this latter period, the Nash criterion was often negative, the global error was high and the maximum concentration peak was underestimated.
On a daily time scale, knowing the complexity of the runoff-suspended sediment process, we have analyzed these two models for solid discharge simulation. The study was carried out on daily solid discharge data collected from the gauging station on the Isser River (1986 to 1989). While based on the same validation criteria, i.e. the Nash efficiency and the global error, the fuzzy logic model appeared more robust than the empirical model. The fuzzy logic model produced better estimates of the daily sediment yield than the empirical model during calibration and validation periods, and it represents a high prediction power. Thus, we have validated the fuzzy logic model as a tool for simulation of runoff of suspended sediments, and it can be explored to predict sediment loading and silting in Algerian reservoirs.
Key-words:
- erosion,
- suspended sediment,
- empirical model,
- fuzzy logic,
- Beni Amrane dam,
- Algeria
Article body
1. Introduction
En Algérie, l’érosion des sols au niveau des bassins versants constitue un problème majeur. En effet, la dégradation du milieu a des conséquences très néfastes sur la productivité des terres et sur la qualité des eaux. Malgré les efforts de luttes anti-érosives telles que le reboisement et la reforestation de 800 000 ha (ceinture verte) et l’aménagement de banquettes (d’absorption ou de diversion) sur 350 000 ha cultivés, la dégradation de la végétation et des sols continue. En effet, le taux d’érosion spécifique atteint les valeurs les plus élevées d’Afrique du Nord. Selon DEMMAK (1982), ces taux varient entre 100 et 2 000 tonnes/km2/an, avec une concentration en MES comprise entre 16 et 40 g/L. Les causes de cette érosion sont diverses : (i) agricoles, les façons culturales et les systèmes d’irrigation ayant contribué à développer une sévère dégradation de la couverture végétale et du réseau hydraulique (ARABI, 1991, ROOSE, 1994); (ii) écologiques, le surpâturage et les feux de forets ayant provoqué le défrichement des fortes pentes; et enfin (iii) hydroclimatiques, les pluies en Algérie étant souvent intenses (l’indice d’érosivité R varie entre 200 et 350 unités dans certaines régions). On estime que 40 000 ha de terres cultivables sont perdus chaque année.
La dégradation du couvert végétal et des sols entraîne l’augmentation de la sensibilité des sols à l’érosion, la dégradation des berges et du lit des rivières, l’augmentation des débits de pointe et des inondations, et, par conséquent, l’augmentation du transport solide. Ce dernier provoque l’envasement des barrages algériens, à raison de 3 % chaque année, et a sensiblement réduit leur capacité de stockage (ANRH, 2000). Face à cette situation, des procédés d’urgence ont été utilisés, d’abord préventifs tels que l’aménagement de plusieurs ravines et microbassins versants, l’installation d’un réseau de dispositifs de mesure du ruissellement et de l’érosion (ROOSE, 2004), puis curatifs tels que la surélévation des digues (barrages de Hamiz), la construction de barrages de décantation (barrage de Boughezoul à l’amont du barrage de Ghrib), ou encore la technique du soutirage qui a enregistré de bons résultats au barrage d’Ighil Emda. L’ampleur de cette érosion hydrique ainsi que les processus mis en jeu sont encore très mal connus.
Pour quantifier les transports solides, des modèles mathématiques ont été développés selon trois approches : (i) les modèles empiriques qui mettent en relation le flux de sédiments à l’exutoire et les différentes variables explicatives climatiques et biophysiques (débit ou intensité de pluie, érodabilité du sol). Nous pouvons citer deux exemples de modèles empiriques : l’équation universelle de perte en sol de WISCHMEIER et SMITH (1960), ou encore les modèles régressifs débit-MES (WALLING et WEBB, 1981); (ii) les modèles conceptuels qui prennent en considération les différents mécanismes tels que le détachement de sédiments par un assemblage de réservoirs (ex. : Modèle de VAN SICKLE et BESCHTA, 1983); et enfin (iii) les modèles physiques distribués (mécanistes) qui explorent des lois physiques telles que l’équation de Saint-Venant pour la phase liquide, et des équations de transport pour la phase solide.
Les méthodes empiriques (formules empiriques) ne permettent qu’une estimation globale des pertes de terre, (GAFREJ, 1993). Les modèles conceptuels, qui prennent en considération la dynamique de l’érosion, ont l’avantage d’estimer des flux à différents pas de temps, mais nécessitent une période de calage relativement longue, et les pics de concentrations des MES sont généralement sous-estimés (PICOUET et al., 2001).
Pour les modèles physiques distribués, leur principal avantage est qu’ils permettent d’étudier la variabilité spatiale de l’érosion, et d’explorer différents endroits du bassin. Cependant, ils nécessitent l’introduction d’un nombre élevé de paramètres.
Dans notre étude, nous avons exploité une nouvelle méthode d’extrapolation des concentrations des matières en suspension, basée sur la logique floue. Cette dernière permet, à partir des valeurs des MES obtenues en fonction des débits pendant la période d’apprentissage, d’extrapoler de manière satisfaisante les concentrations des MES, en particulier dans le cas des débits de crue.
2. Modèles de simulation
La modélisation de la relation débit-MES présente certaines difficultés dues principalement à la forte non-linéarité du processus débit-MES, notamment à l’échelle horaire, à l’effet d’hystérésis, et aux erreurs des données utilisées (débit et concentrations en MES).
Dans notre étude, deux modèles ont été exploités : un modèle empirique basé sur la corrélation, et un autre basé sur la logique floue.
Notre travail de modélisation s’effectuera à deux échelles temporelles : Au pas de temps horaire, pour une modélisation débit liquide-concentrations MES; au pas de temps journalier, pour une analyse débit liquide-débit solide en suspension.
2.1 Le modèle empirique
Ce modèle utilise une corrélation sous forme de relation de puissance entre les débits observés et les concentrations solides correspondantes. Ce modèle est du type :
où F représente la concentration calculée(g/L), Q est le débit liquide (en m3/s), a et b sont des paramètres du calage du modèle. Ce modèle empirique a déjà été appliqué en Algérie pour une analyse débit solide-débit liquide au bassin de l’oued Wahrane (BENKHALED et REMINI, 2003).
2.2 Le modèle flou
L’approche floue a été introduite pour la première fois par ZADEH (1965) comme un outil permettant de prendre en considération les incertitudes sur les grandeurs mesurées. De nos jours, la logique floue trouve des applications dans de nombreuses disciplines technologiques (BERENJI et al., 1985), industrielles (BENOIT, 1993) et hydrologiques (DECHEMI et al., 2003).
2.2.1 Généralités sur les ensembles flous
Un sous-ensemble flou T est défini sur un univers de discours U, et par une fonction d’appartenance qui associe, à chaque élément x de U, le degré d’appartenance à T noté µ(T), compris entre 0 et 1, soit :
La variable à modéliser est considérée comme une variable linguistique (ZADEH, 1971), et est caractérisée par un quadruplet (X,T(x),U, F(x)), où X est le nom de la variable (ex. : Débit, Concentration), T(x) l’ensemble des valeurs linguistiques (étiquettes) correspondant (faible, moyenne, élevée), U est le domaine physique associé à la variable considérée, appelé univers de discours (ex. : X varie entre 0 et 100 m3/s).
F(x) est une fonction sémantique (fonction d’appartenance) qui associe à tout ensemble T(x) une signification floue (DRIANKOV et al., 1993, NAKOULA, 1997).
De façon générale, la construction d’un modèle flou suit la syntaxe :
On aura donc une règle floue qui est de la forme :
Considérons deux variables : débits et concentrations des MES. Les caractérisations floues sont représentées par les valeurs des débits et les concentrations en matières en suspension. On aura :
2.2.2 Modélisation par la logique floue
La modélisation d’un système entrée/sortie par la logique floue s’effectue en trois phases essentielles :
La fuzzification transforme la valeur modélisée X en une partie floue. La fuzzification permet de modéliser les entrées d’un système principalement sous forme de courbes appelées fonctions d’appartenance. Ces dernières permettent de délimiter les sous-ensembles flous. Elles représentent le degré d’appartenance d’une valeur à un état donné, et peuvent avoir différentes formes (en triangle, en trapèze, etc.) (BOUCHON-MEUNIER, 1995). Les séries de débits et de concentrations (MES) sont divisées en un nombre équivalent de sous-ensembles flous (partitionnement flou). Dans notre exemple, nous avons trois sous-ensembles flous pour les données d’entrée et de sortie. Dans le cas du sous-ensemble flou « moyen », cela veut dire que c’est une zone de débit, qui commence à 20 m3/s, qu’elle est pleinement réalisée entre 40 m3/s et 50 m3/s, et qu’elle cesse à partir de 60 m3/s (Figure 1).
-
L’inférence floue produit l’image de la partie floue issue de la fuzzification par une relation floue construite à partir des règles floues. À la présentation de chaque entrée (valeur de débit), en fonction des règles d’inférence floue, on détermine le degré d’appartenance à un sous-ensemble donné. Dans notre exemple, nous prenons en considération la valeur du débit 30 m3/s. Ainsi, en fonction de l’appartenance de la valeur x = 30 m3/s aux différents sous-ensembles flous, nous aurons les degrés de vérité suivants :
Il est vrai à 60 % (degrés = 0,6) que la valeur 30 m3/s appartient au sous-ensemble flou faible.
Il est vrai à 40 % (degrés = 0,4) que la valeur 30 m3/s appartient au sous-ensemble flou moyen.
Il est vrai à 0 % (degrés = 0) que la valeur 30 m3/s appartient au sous-ensemble flou élevé.
À partir des règles floues, et pour chaque degré d’appartenance calculé, on engendre des surfaces d’inférence (Figure 2).
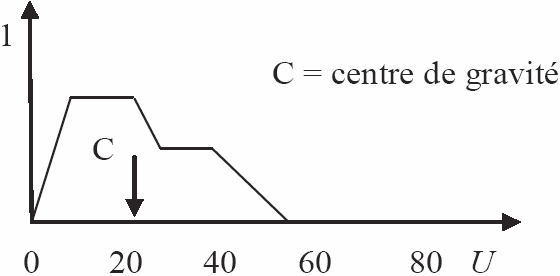
La défuzzification transforme la partie floue issue de l’inférence en une valeur numérique de sortie, et peut être effectuée par plusieurs méthodes; dans notre cas, nous avons utilisé la technique du centre de gravité : La valeur simulée (concentration en MES) correspond à la projection du centre de gravité (défuzzification centroïde) de la surface d’inférence sur l’abscisse de la série des concentrations observées (Figure 3).
Figure 1
Exemple d’une fuzzification à trois règles.
Example of a fuzzification using three rules.

Figure 2
Calcul d’une surface d’inférence.
Shaded area estimation.
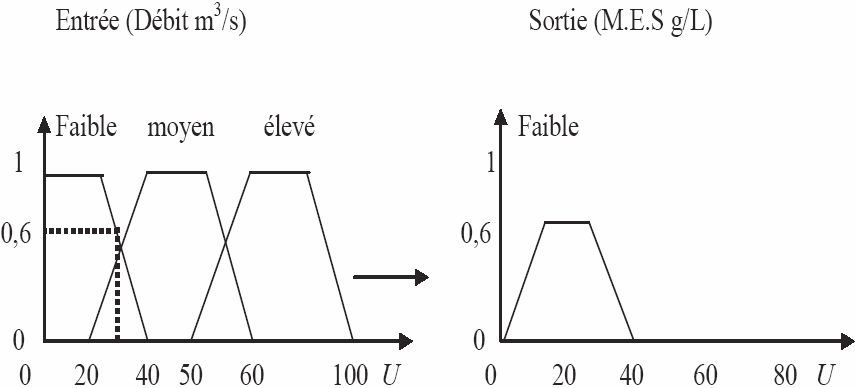
Figure 3
Calcul d’une valeur de MES par la méthode du centre de gravité.
Calculation of a sediment concentration value using centroid defuzzification.
2.3 Modèle utilisé
La description précédente caractérise le modèle flou de type MAMDANI (1974) très utilisé dans les disciplines de régulation ou de commande floue. Dans notre étude, nous avons exploité la méthode de SUGENO (1985). Dans ce modèle, la prémisse est symbolique, mais la conclusion est une procédure donnant directement une valeur de la variable modélisée, soit par une fonction linéaire (modèle d’ordre 1), soit par des constantes (modèle d’ordre 0).
Pour un espace d’entrée de dimension n, on note X = (x1, . . . xn)t, la règle floue i est de la forme :
où Ai1 … Ain sont des sous-ensembles flous, Y est la valeur simulée, a1… an et b sont les paramètres (coefficients) linéaires à estimer.
2.4 Apprentissage des modèles flous : l’optimisation neurofloue
Les réseaux de neurones artificiels présentent l’avantage d’être des approximateurs universels parcimonieux, qui procèdent par apprentissage pour modéliser un système entrée/sortie. Leur capacité de généralisation permet d’optimiser le processus simulé par un faible nombre de données.
C’est dans cette optique que plusieurs chercheurs (GLORENNEC et al., 1992, BERSINI et GORRINI, 1993) ont exploité les réseaux de neurones artificiels et combiné les deux approches floue et neuronale d’où le modèle neuro-flou.
Le modèle utilisé est un modèle neuroflou, qui utilise la logique floue et une structure neuronale à apprentissage supervisé (JANG, 1993) qui permet l’estimation des paramètres non linéaires (de prémisse). Les paramètres linéaires (de conclusion) sont ajustés par la méthode des moindres carrés.
2.5 Critères de validation des modèles
Ces critères permettent d’évaluer la qualité de modélisation en calculant l’erreur entre les données observées et simulées.
2.5.1 Critère de Nash
Ce critère adimensionnel (NASH et SUTCLIFFE, 1970) exprime le pourcentage de la variance naturelle que l’on gagne par rapport à un modèle qui donnerait comme flux calculés la moyenne des flux observés et il est défini par :
Fio et Fis représentent respectivement les flux observés et simulés à l’instant i, Fmoy est la moyenne des flux observés. Si la valeur du critère de Nash converge vers cent, le modèle est optimisé.
2.5.2 Erreur sur le bilan
Exprimée en pourcentage, l’erreur sur le bilan est calculée comme suit :
3. Contexte géographique
La zone d’étude concerne le bassin versant de l’Isser situé au nord de l’Algérie. Sa superficie totale est de 4 170 km2. Le climat du bassin est méditerranéen, froid et humide en hiver, chaud et sec en été, la pluviométrie moyenne est de 800 mm par an. Les modèles seront testés sur les données de la station hydrométrique de Lakhdaria, située en amont du barrage de Beni Amrane, dont la capacité initiale est de 15 Hm3. Il est à noter que la retenue de Beni Amrane représente un barrage de transfert vers le barrage de Keddara qui alimente la ville d’Alger en eau potable. De ce fait, la qualité de l’eau dans le barrage de Beni Amrane doit être adéquate pour effectuer des transferts vers le barrage de Keddara. Selon l’Agence Nationale des Ressources Hydrauliques (ANRH, 1990), la concentration des matières en suspension doit être inférieure à 2 g/L, pour effectuer des lâchés d’eau du barrage de Beni Amrane vers celui de Keddara. Les caractéristiques hydrologiques de la région considérée sont présentées dans le tableau 1.
Tableau 1
Caractéristiques hydrologiques du bassin versant.
Hydrological characteristics of the catchment.

Concernant les données, nous avons choisi quatre épisodes débit-MES au pas de temps horaire pour leur taille et leur variance. En effet, la capacité de simulation d’un modèle doit être testée sur des échantillons présentant une variance élevée. Cette modélisation débit-MES à l’échelle horaire sera complétée par une modélisation débits liquides-débits solides au pas de temps journalier. Les épisodes horaires et leurs dates correspondantes sont résumés dans le tableau 2.
Tableau 2
Épisodes débits-concentrations en MES étudiés.
Suspended sediment events.

4. Résultats et interprétations
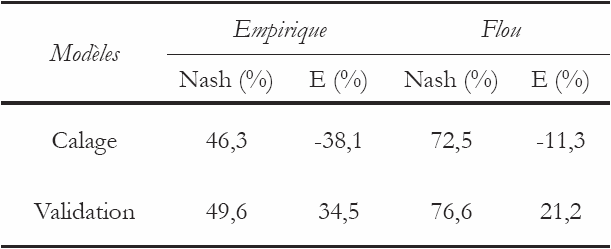
Les modèles utilisés pour simuler les concentrations en MES sont calibrés durant une période dite de calage pour estimer les paramètres des modèles, et leurs performances seront testées en période de validation pour juger de la capacité prédictive de ces modèles. Les séries sont donc divisées en deux sous-échantillons, deux tiers (2/3) des données seront utilisés pour le calage (apprentissage) et l’autre tiers (1/3) pour la validation du modèle. Les résultats des deux modèles sont présentés dans les tableaux 3 et 4.
Tableau 3
Résultats des modèles en période de calage.
Model results during the calibration period.

Tableau 4
Résultats des modèles en période de validation.
Model results during the validation period.

D’après les tableaux 3 et 4, il est à remarquer que le modèle flou a donné des résultats très performants. En effet, le critère de Nash est souvent supérieur à 88 %, en période de calage, les valeurs des concentrations MES sont correctement calculées. En période de validation, on enregistre une amélioration de la simulation pour l’épisode 1, le critère de Nash atteint 96 % (Figure 4 (a)). L’erreur sur le bilan est très faible et ne dépasse pas –0,2 %. La concentration en MES la plus élevée est observée durant cet épisode et elle atteint 76 g/L. On déduit donc que la région est sujette à des flux importants de matières solides.
Figure 4
Simulation des MES par le modèle flou, (a) Épisode 1, (b) Épisode 3.
Simulation of sediment concentrations using a fuzzy logic model, (a) Episode 1, (b) Episode 3.
Figure 4a

Figure 4b

Pour l’ensemble des épisodes, on note une reproduction assez correcte des valeurs des concentrations MES durant les crues, les pics des valeurs sont généralement bien reproduits, ainsi que les différentes tendances lors des décrues. L’épisode 3 enregistre ainsi la meilleure performance de simulation pour le modèle flou et le critère de Nash est supérieur à 91 % pour les deux périodes (Figure 4 (b)).
Pour le modèle empirique, les résultats obtenus sont moins performants, les valeurs du critère de Nash sont inférieures à 61 % dans la période de calage et les concentrations simulées sont largement sous-estimées lors des crues, en particulier pour l’épisode 1 (Figure 5 (a)).
Figure 5
Simulation des MES par le modèle empirique, (a) Épisode 1, (b) Épisode 2.
Simulation of sediment concentrations using an empirical model, (a) Episode 1, (b) Episode 2.
Figure 5a
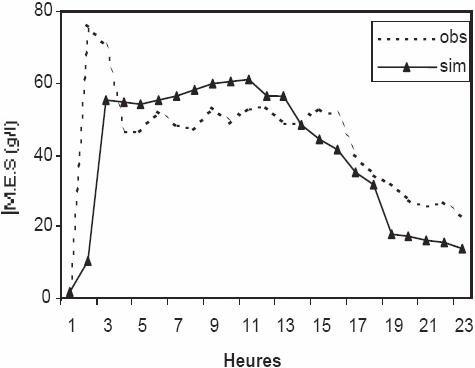
Figure 5b
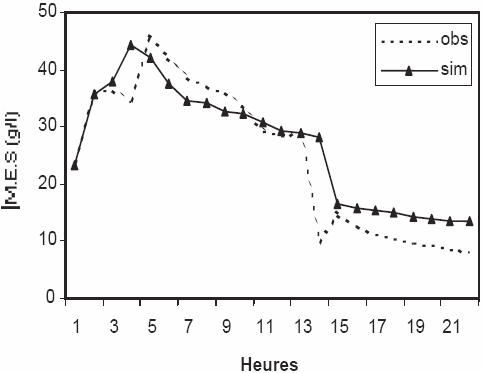
En phase de validation, il est à signaler une dégradation de la simulation, le critère de Nash est souvent négatif, et atteint –1 300 pour l’épisode 2 (Figure 5 (b)), le modèle donne des concentrations supérieures à celles observées.
Pour l’ensemble des épisodes, les pics de concentrations ne sont pas reproduits, par exemple lors de l’épisode 1 en période de validation, le modèle empirique donne une valeur de 10 g/L pour une concentration observée de 76 g/L.
En étudiant la paramétrisation des deux modèles, on remarque que le modèle flou est optimisé avec un nombre de règles variant de 5 à 13 règles, et paraît plus robuste que le modèle empirique utilisant deux paramètres. Les valeurs des MES de l’épisode 3 ont été ainsi correctement simulées en utilisant cinq règles seulement.
Il est à noter que le modèle flou (à apprentissage neuronal) utilise une architecture complexe, et cela contrairement à la simplicité du modèle empirique, dont les paramètres sont :
où Fs sont les flux simulés (g/L), Q est le débit correspondant au pas de temps horaire (m3/s).
En comparant les deux critères de validation, nous avons constaté que si le critère de Nash donne une appréciation de la simulation des valeurs des MES pour chaque donnée, l’erreur sur le bilan ne permet qu’une estimation globale des flux, et donc incompatible avec la prévision des concentrations des MES en temps réel.
De ce fait, les modèles de simulation des MES doivent être validés en tenant compte du critère de Nash pour suivre l’évolution des sédiments à l’échelle horaire, et donc la décision de faire des lâchés du barrage de Beni Amrane vers le barrage de Keddara.
4.1 Simulation des débits solides en suspension au pas de temps journalier
La simulation des débits solides en suspension à l’échelle journalière présente un grand intérêt du fait qu’elle permet d’anticiper l’évolution de l’envasement des barrages à partir des données hydrométriques journalières. Cette simulation est tributaire de la taille des séries de données utilisées et de leur qualité.
Dans notre cas, vu que nous ne disposons pas d’échantillons de grande taille, notre essai de modélisation se fera sur un échantillon disponible de la station de Lakhdaria, dont les débits solides journaliers dépassent parfois 9 000 kg/s.
Les débits solides en suspension sont calculés à partir des données des concentrations en MES mesurées selon l’équation suivante :
où
Qso est le débit solide (kg/s),
Q est le débit liquide observé (m3/s),
CMES est la concentration des matières en suspension (g/L).
La simulation a été faite à partir des données de la période comprise entre janvier 1986 et juillet 1989. L’objectif principal est de tester les modèles sur un éventail de données relativement court, pour étudier le pouvoir prédictif de ces modèles. Les résultats des deux périodes (calage et validation) sont présentés dans le tableau 5.
Tableau 5
Résultats de la simulation des débits solides au pas de temps journalier.
Simulation results on a daily time scale.
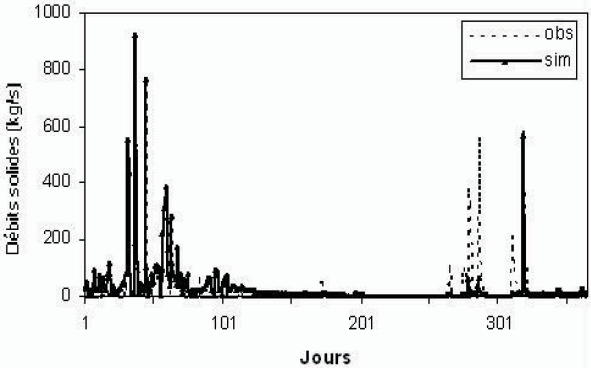
D’après le tableau 5, nous remarquons que le modèle flou a effectivement donné de bons résultats par rapport au modèle empirique, le critère de Nash est de 72 % en phase de calage, et atteint 80 % pour l’année 87 (Figure 6). En période de validation, le coefficient de Nash dépasse 76 %, les pics des MES sont parfois bien simulés, et l’erreur sur le bilan est moyenne. Pour le modèle empirique, le coefficient de Nash n’a pas dépassé la barre des 50 %, et l’erreur sur le bilan est relativement élevée. Après optimisation, l’équation du modèle a pour expression :
où Qs représente le débit solide calculé et Q le débit liquide à l’échelle journalière.
Figure 6
Simulation journalière par le modèle flou pour l’année 1987.
Daily simulation using a fuzzy logic model, year 1987.
Cependant, une amélioration de la simulation est observée durant la phase de validation, et cela contrairement au pas de temps horaire, où on observe généralement une dégradation de la modélisation entre la phase de calage et celle de validation.
En comparant les résultats des modèles en fonction des échelles temporelles, nous pouvons noter la complexité de la relation débit-MES au pas de temps journalier. En effet, si à l’échelle horaire la non-linéarité constitue la grande difficulté de simulation, au pas de temps journalier, le modèle se trouve confronté à des cas difficilement modélisables (ex. : débit élevé, concentration MES faible, débit faible, concentration MES élevée). Néanmoins, les résultats obtenus par l’approche floue sont satisfaisants.
5. Conclusion
La modélisation de la relation débit-MES présente un grand intérêt du fait qu’elle permet d’anticiper l’évolution des flux de transports solides à l’exutoire d’un bassin, ou en amont des barrages.
Nous avons testé deux modèles, l’un empirique et l’autre basé sur la logique floue utilisant un apprentissage neuronal dans la simulation des flux de MES et des débits solides, à partir des débits observés du barrage de Beni Amrane très vulnérable aux transports solides.
Le modèle flou a donné des résultats performants au pas de temps horaire, les épisodes débit-MES sont correctement simulés, le critère de Nash est généralement élevé que ce soit en calage ou en validation, ce qui justifie le pouvoir prédictif du modèle, et cela contrairement au modèle empirique qui utilise une relation de puissance, où les résultats sont médiocres, en particulier en phase de validation.
Au pas de temps journalier, la simulation débit liquide-débit solide par le modèle flou est correcte et présente un net avantage par rapport au modèle empirique.
Néanmoins, nous pouvons noter que le modèle flou utilise une architecture d’apprentissage complexe (apprentissage neuronal), contrairement au modèle empirique relativement simple utilisant deux paramètres seulement.
Cependant, vu la forte non-linéarité et la difficulté de simulation de la relation débit-MES, nous ne pouvons que valider le modèle flou dans l’estimation des transports solides. Ce modèle a, en effet, donné des résultats très appréciables aux pas de temps horaire et journalier pour le cas de la retenue de Beni Amrane, et peut être exploité dans la quantification et le suivi de l’envasement des barrages algériens.
Appendices
Remerciements
Les auteurs remercient le personnel du département d’hydrologie de l’Agence Nationale des Ressources Hydrauliques (ANRH, Algérie) pour leur fourniture des données débit-MES. Les auteurs tiennent à remercier vivement les réviseurs anonymes de la Revue pour leur aide et leurs conseils utiles.
Références bibliographiques
- ANRH, 2000. Actualisation des volumes régularisables. Bulletin Agence Nationale des Ressources Hydrauliques (Algérie), N° 12/2000.
- ANRH, 1990. Étude hydrologique du barrage de Beni Amrane. Étude COBA, 40 p.
- ARABI M., 1991. Influence de quatre systèmes de production sur le ruissellement et l’érosion en milieu montagnard méditerranéen algérien. Thèse de doctorat, Université de Grenoble, 276 p.
- BENKHALED A. et B. REMINI, 2003. Analyse de la relation de puissance : débit solide - débit liquide à l’échelle du bassin versant de l’Oued Wahrane (Algérie). Rev. Sci. Eau, 16, 333-356.
- BENOIT E., 1993. Capteurs symboliques et capteurs flous : un nouveau pas vers l’intelligence artificielle. Thèse de Doctorat, Université Joseph Fourier, Grenoble, 164 p.
- BERENJI R., MALKANI A. et C. COPELAND, 1985. Tether control using fuzzy reinforcement learning, IEEE/IFES, Yokohama, Japan, 1315-1319.
- BERSINI H. et V. GORRINI, 1993. FUNNY, fuzzy or neural net methods for adaptive process control. Proceedings of EUFIT, Allemagne, 55-61, 1993.
- BOUCHON-MEUNIER B., 1995. La logique floue et ses applications, Addison-Wesley France, Paris, 257 p.
- DECHEMI N., BENKACI T. et A. ISSOLAH, 2003. Modélisation des débits mensuels par les modèles conceptuels et les systèmes neuro-flous. Rev. Sci. Eau, 16, 407-424.
- DEMMAK A., 1982. Contribution à l’étude de l’érosion et des transports solides en Algérie septentrionale. Thèse de Doctorat, Université Pierre et Marie Curie – Paris, 323 p.
- DRIANKOV D., HELLENDOOM H. et M. REINFRANK, 1993. An introduction to fuzzy control, Springer-Verlag, New York, États-Unis, 1993, 323 p.
- GAFREJ R., 1993. Modélisation conceptuelle du transfert des matières en suspension, effet d’échelles spatio-temporelles. These de Doctorat, Université Paris 6, CEMAGREF, 180 p.
- GLORENNEC P.Y, BARRET C. et M. BRUNNET, 1992. Application of neuro-fuzzy network to identification and control of nonlinear dynamical systems, Proceedings of IPMU, 1992, Mallorca, Spain, 507-510.
- JANG J., 1993. ANFIS: Adaptive-network-based fuzzy Inference Systems. IEEE SMC, 23, 665-685.
- MAMDANI E.H., 1974. Application of fuzzy algorithms for control of a simple dynamic Plant. Proceedings of the IEE Control and Science, 121, 12, 1585-1588, 1974.
- NAKOULA Y., 1997. Apprentissage des modèles linguistiques flous par jeu de règles pondérées. Thèse de Doctorat, Université de Savoie, 158 p.
- NASH J.E. et J.V. SUTCLIFFE, 1970. River flow forecasting through conceptual model. Part 1 - a discussion of principles. J. Hydrol., 10, 282-290.
- PICOUET C., HINGRAY B. et J.C., OLIVRY, 2001. Empirical and conceptual modelling of the suspended sediment dynamics in a large tropical African river: the Upper Niger river basin. J. Hydrol., 250, 19-39.
- ROOSE E., 1994. Introduction à la GCES. Bull. Pédol. FAO, Rome, 70, 420 p.
- ROOSE E., 2004. Évolution historique des stratégies de lutte antiérosive. Vers la gestion conservatoire de l’eau, de la biomasse et de la fertilité des sols, Sécheresse, 1, 9-18.
- SUGENO M., 1985. Industrial applications of fuzzy control, Elsevier sciences publications, New York, États-Unis, 269 p.
- VAN SICKLE J. et R. BESCHTA, 1983. Supply based models of suspended sediment transport in Streams. Water Resour. Res., 19, 768-778.
- WALLING D.E. et B.W. WEBB, 1981. The reliability of suspended sediment load data. Erosion and sediment transport measurement, Proceedings of the Florence Syrnposium, IAHS Publ., 133, 177-194, 1981.
- WISCHMEIER W.H. et D.D. SMITH, 1960. A universal soil loss estimating equation to guide conservation farm planning. Proceedings 7th Int. Congress Soil Sci. Soc., 1, 418-425, 1960.
- ZADEH L., 1965. Fuzzy sets. Inf. Contr., 8, 338-353.
- ZADEH L., 1971. Quantitative fuzzy semantics, Inf. Sci., 3, 159-176.
List of figures
Figure 1
Exemple d’une fuzzification à trois règles.
Example of a fuzzification using three rules.
Figure 2
Calcul d’une surface d’inférence.
Shaded area estimation.
Figure 3
Calcul d’une valeur de MES par la méthode du centre de gravité.
Calculation of a sediment concentration value using centroid defuzzification.
Figure 4
Simulation des MES par le modèle flou, (a) Épisode 1, (b) Épisode 3.
Simulation of sediment concentrations using a fuzzy logic model, (a) Episode 1, (b) Episode 3.
Figure 4a
Figure 4b
Figure 5
Simulation des MES par le modèle empirique, (a) Épisode 1, (b) Épisode 2.
Simulation of sediment concentrations using an empirical model, (a) Episode 1, (b) Episode 2.
Figure 5a
Figure 5b
Figure 6
Simulation journalière par le modèle flou pour l’année 1987.
Daily simulation using a fuzzy logic model, year 1987.
List of tables
Tableau 1
Caractéristiques hydrologiques du bassin versant.
Hydrological characteristics of the catchment.
Tableau 2
Épisodes débits-concentrations en MES étudiés.
Suspended sediment events.
Tableau 3
Résultats des modèles en période de calage.
Model results during the calibration period.
Tableau 4
Résultats des modèles en période de validation.
Model results during the validation period.
Tableau 5
Résultats de la simulation des débits solides au pas de temps journalier.
Simulation results on a daily time scale.