
Résumés
Résumé
Cet article présente une application d’une méthode d’estimation de la répartition spatiale et temporelle de l’emploi régional au Canada. La méthode de minimisation de l’entropie croisée permet de réconcilier des données régionales qui sont, a priori, divergentes des totaux agrégés. À partir des données d’emploi provenant de l’Enquête sur la population active en fonction des régions économiques et des secteurs productifs, des matrices (rectangulaires) de répartitions spatiales de l’emploi sont obtenues pour l’ensemble des années disponibles (1987-2008). L’article montre comment il est possible de réconcilier les données d’enquêtes faisant état de règles d’arrondis et de règles de divulgation dans le but d’obtenir une source de données spatio-temporelle permettant d’utiliser, au meilleur des connaissances, des données incomplètes.
Abstract
This paper presents an application of an estimation method for calculating coherent spatial employment distributions for Canada over time. The cross-entropy minimization method allows for data reconciliation when disaggregation causes divergence in total distributions. Using Statistics Canada Labour Force Survey data by economic region and industry class, spatial employment distribution (rectangular) matrices were obtained over the entire time period (1987-2008). The paper proposes a procedure for reconciling survey data in cases where confidentiality and rounding rules are applied in order to obtain a coherent spatial-temporal data set even where the original data are incomplete.
Corps de l’article
Introduction
La science régionale et l’économie géographique s’intéressent à la compréhension des conséquences économiques de l’espace en étudiant la répartition spatiale et la localisation des activités économiques. Cette branche s’attarde, en outre, à l’étude des comportements à un niveau de désagrégation géographique important. Une source de données intéressante pour étudier la situation régionale de l’emploi à l’échelle des régions économiques canadiennes entre les recensements repose sur l’Enquête sur la population active (EPA) de Statistique Canada. Or, l’EPA comprend certaines règles de divulgation/confidentialité et/ou d’arrondissements qui peuvent rendre les données disponibles incomplètes pour un certain niveau de désagrégation. Les règles de divulgation ont notamment pour effet d’introduire une distorsion entre les totaux selon que les entités géographiques sont agrégées ou désagrégées. Bien que de peu d’importance au niveau géographique agrégé, ces restrictions compliquent l’étude des phénomènes de croissance de l’emploi sectoriel à l’échelle des petites régions par le fait que peu de données et d’informations existent pour ce niveau de désagrégation.
En plus de ce problème s’ajoute celui de la variation constante de l’échantillonnage dans les régions économiques de faible taille qui a pour effet d’introduire une source de variation supplémentaire dans les données. La caractérisation de l’échantillonnage a pour conséquence de créer des séries temporelles plus volatiles lorsque le niveau de désagrégation est important. Une façon simple de retirer certains mouvements irréguliers des séries de données chronologiques consiste à utiliser une méthode de lissage telle que, par exemple, un modèle à moyenne mobile intégrée autorégressif (ARIMA[1]). Par contre, l’application de cette technique sur des séries de données indépendantes a pour effet de ne pas respecter les contraintes naturelles posées par les données d’enquête, à savoir le respect des totaux, provinciaux et nationaux.
Certaines méthodes ont été développées afin de pallier le manque de données ou encore l’incompatibilité de celles-ci à l’échelle désagrégée lorsque comparées aux totaux agrégés. Une de ces approches, la méthode de minimisation de l’entropie croisée (MinXEnt), permet de régler simultanément les deux lacunes à partir d’un problème d’optimisation reposant sur la construction d’une matrice de répartition des données. La méthode MinXEnt permet d’obtenir une nouvelle distribution spatiale d’une variable d’intérêt de sorte qu’elle assure un minimum de divergence avec la distribution d’origine tout en respectant un certain nombre de contraintes. Celles-ci représentent, notamment, les règles de divulgation et d’arrondissements dans la publication des données, ainsi que la somme des variables, à l’échelle désagrégée, qui doit être égale à la somme à l’échelle agrégée.
L’approche MinXEnt est retenue et appliquée pour la répartition de l’emploi au Canada par région économique et par secteur productif entre 1987 et 2008. Dans ce contexte, la méthode permet d’obtenir une nouvelle base de données, à la fois spatiale et temporelle, qui respecte les contraintes d’agrégation ainsi que les contraintes de publication des données. Cette nouvelle base de données permet, sans être jugée optimale, d’étudier certains phénomènes économiques spatialisés à un niveau de désagrégation important, autant au niveau géographique qu’au niveau sectoriel. La méthode peut être appliquée à d’autres sources de données en appliquant des contraintes similaires, de nouvelles contraintes jugées pertinentes ou encore d’autres contraintes plus générales afin de dériver une nouvelle source de données comportant moins de limites.
L’article est divisé en quatre parties. La première présente l’Enquête sur la population active : les caractéristiques d’échantillonnage, les règles de divulgation et de suppression des données ainsi que les données utilisées pour obtenir une nouvelle répartition désagrégée cohérente de l’emploi au Canada. La deuxième partie présente formellement la méthode de la minimisation de l’entropie croisée dans le but d’obtenir une nouvelle estimation de la répartition sectorielle de l’emploi régional au Canada. La troisième partie présente les résultats d’estimation et met en relief les différences entre les données obtenues et celles de l’Enquête sur la population active. Finalement, une brève conclusion clôture l’article.
1. Enquête sur la population active (EPA)
1.1 Caractérisation de l’EPA
L’Enquête sur la population active (EPA) est menée chaque mois auprès d’environ 54 000 ménages canadiens dans le but de dresser le portrait détaillé du marché du travail (Statistique Canada, 2009). Cette enquête permet de calculer certains indicateurs fondamentaux tels que le taux de participation au marché du travail, le taux d’emploi et le taux de chômage, par province, mais également par région économique et par région métropolitaine de recensement. Elle permet également de connaître la distribution spatiale de l’emploi en fonction des classes industrielles et constitue la principale source de données permettant de suivre l’évolution de l’emploi au Canada entre les recensements.
L’EPA consiste en une entrevue pour un échantillon de la population en âge de travailler (15 ans et plus). Un ménage ciblé est suivi pendant 6 mois et chaque mois, un sixième de l’échantillon est renouvelé (chevauchement) afin d’assurer un taux de réponse intéressant tout en contrôlant pour les coûts de l’enquête. Un échantillon de ménages est sélectionné à partir d’une méthode d’échantillonnage à deux degrés (Statistique Canada, 2008). En première étape, un échantillon de régions géographiques, désignées par le terme unité primaire d’échantillonnage (UPE), est sélectionné. Par la suite, pour chacune des UPE, un échantillon de ménages est sélectionné. Comme toute enquête, l’EPA demeure sensible aux erreurs d’échantillonnages[2] et aux erreurs non reliées à l’échantillonnage[3].
Étant donné le renouvellement du sixième de l’échantillon à chaque mois et la méthode d’échantillonnage en deux étapes, les données peuvent montrer une volatilité temporelle considérable pour de petites régions économiques et fragiliser l’analyse chronologique des données à courte fréquence, à plus forte raison si l’analyse régionale est effectuée au niveau des secteurs productifs. Pour cette raison, les analyses à l’échelle des régions économiques sont souvent effectuées avec des moyennes annuelles ou encore en utilisant des séries désaisonnalisées. Malgré qu’elles permettent de diminuer l’impact de la volatilité des séries, ces approches n’éliminent pas la totalité des problèmes liés à la volatilité et encore moins ceux liés à l’incompatibilité des données agrégées et désagrégées.
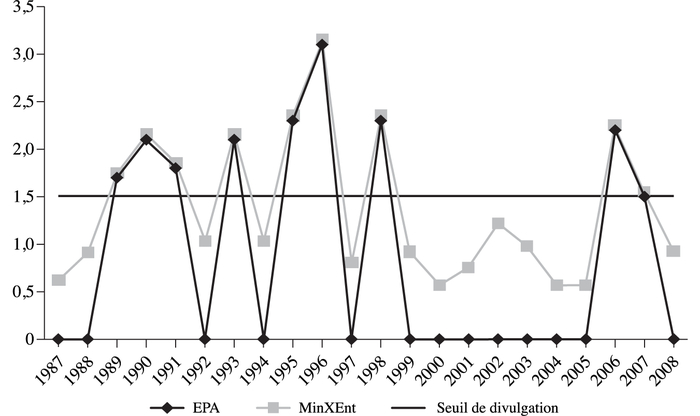
L’EPA est astreinte à certaines règles de publication des données selon la province. Premièrement, les données publiées sont arrondies à la centaine la plus près. Deuxièmement, certaines valeurs sont supprimées de la base de données lorsque jugées trop peu nombreuses ou susceptibles de révéler certaines informations et contrevenir à la règle de divulgation. La publication des valeurs dépend ainsi d’un certain seuil de divulgation qui varie en fonction des provinces (tableau 1). Ainsi, les données publiées sont susceptibles de montrer certains comportements hasardeux tels que la présence de « faux zéros ». Pour certains secteurs productifs, le nombre d’emplois est nul pour une année donnée pour ensuite se situer à un nombre supérieur du seuil de divulgation l’année suivante et redevenir nul par la suite.
Tableau 1
Seuil minimal de divulgation des données d’emploi de l’EPA par province (En deçà de ces seuils, les données ne sont pas publiées)

Ces quelques effets non désirables ne sont pas sans importance lorsque le sujet d’intérêt est la croissance de l’emploi par secteur productif au niveau des régions économiques. La troncature des données, de par un nombre considérable de valeurs zéro, implique une mauvaise évaluation des taux de croissance et, par conséquent, risque d’introduire des éléments perturbateurs supplémentaires dans un modèle statistique. De plus, ces règles introduisent des divergences entre le nombre total d’emplois selon le niveau de désagrégation, géographique et industriel, retenu. Dans ces cas, il devient souhaitable d’obtenir une meilleure estimation du nombre d’emplois qui respecte les contraintes de répartitions agrégées de l’emploi, à la fois par secteur productif et par province.
1.2 Données de l’EPA, 1987-2008
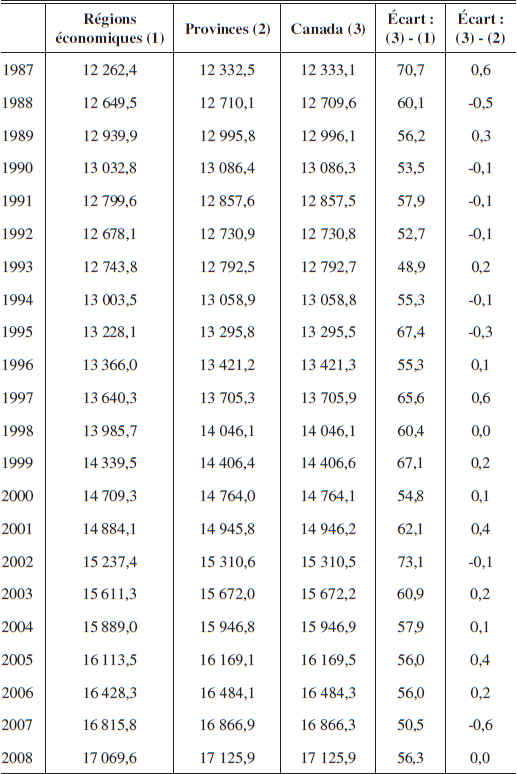
Les données d’emploi de l’EPA peuvent être obtenues par région économique, par secteur productif ou par région économique en fonction des secteurs productifs à partir de 1987[4]. L‘EPA permet de diviser le Canada (à l’exception des territoires) en 69 régions (économiques) et en 16 secteurs productifs, inspirés du système de classification des industries d’Amérique du Nord (SCIAN[5] – tableau 2). Le total de l’emploi est comparable au total provincial selon que celui-ci est ventilé par secteur productif ou par région économique (tableau 3). Quelques écarts subsistent, mais ceux-ci sont très faibles et sont majoritairement la résultante d’arrondissements (centaine près), bien qu’il existe quelques exceptions où les écarts sont de 200 à 300 emplois.
Tableau 2
Liste des secteurs industriels selon l’EPA et correspondance possible avec le SCIAN
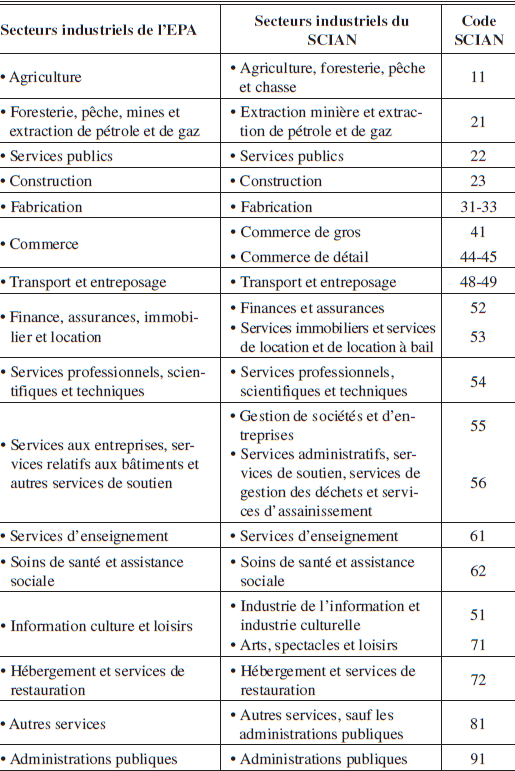
Tableau 3
Nombre total d’emploi (en milliers) par province selon la méthode d’agrégation

Tableau 3 (suite)

Tableau 3 (suite)

Note : SP = secteur productif; RE = région économique
Par contre, de par les contraintes de publication des données, la somme totale des emplois par secteur productif et par région économique donne un portrait différent du nombre d’emplois total agrégé par province et pour le pays (tableau 4). Les écarts entre le nombre total d’emplois par province par rapport au nombre total d’emplois pour le Canada peuvent être causés par les règles d’arrondissements. Par contre, les écarts plus grands notés au niveau des secteurs productifs par région économique ne peuvent provenir uniquement des règles d’arrondissements. Ceux-ci sont particulièrement marqués pour les provinces du Québec, de l’Alberta et de la Colombie-Britannique, où la règle de divulgation minimale est fixée à 1 500 emplois par région économique et secteur productif.
Tableau 4
Nombre total d’emplois (en milliers) par secteur productif selon la désagrégation géographique retenue
Il devient donc nécessaire de reconstituer les données d’emploi au niveau des secteurs productifs par région économique si on s’intéresse à la situation régionale de l’emploi par branches productives. La méthode de minimisation de l’entropie croisée (MinXEnt) permet d’estimer une distribution spatiale de l’emploi qui soit cohérente avec les informations émanant de l’EPA. Elle s’appuie sur des fondements théoriques rigoureux tout en faisant preuve de transparence et en recourant au principe d’objectivité scientifique (Kapur et Kesavan, 1992).
2. Méthode
2.1 Minimisation de l’entropie croisée[6]
Le problème de minimisation de l’entropie croisée (MinXEnt) permet de généraliser la méthode d’ajustement de matrice (Macgill, 1977), bien connue pour équilibrer les matrices d’entrées-sorties. Plus concrètement, la méthode MinXEnt consiste à ajuster une matrice a priori – en l’occurrence la matrice de répartition sectorielle de l’emploi régional – de façon à respecter une information qui est imposée comme contrainte et qui, dans le cas présent, est donnée par la répartition agrégée de l’emploi sectoriel dans les provinces canadiennes.
L’application de la méthode, visant à minimiser la divergence entre la matrice de répartition a priori et celle obtenue a posteriori, exige la définition d’une mesure de différence. Celle-ci est donnée par la mesure de l’entropie croisée de Kullback et Leibler (1951) qui consiste à minimiser la divergence entre les éléments d’origine (ou a priori[7] – qij) et la nouvelle distribution (ou a posteriori[8] –pij) (équation 1).
Dans le cas actuel, les éléments généraux de la distribution a priori représentent le nombre d’emplois publié (EPA) pour le secteur productif j de la région économique i alors que les éléments généraux de la distribution a posteriori représentent le nombre d’emplois estimé pour le secteur productif j de la région économique i. La forme de la fonction objectif assure que la nouvelle distribution obtenue (le résultat) est unique puisqu’elle est convexe (Kullback, 1959; Kapur et Kesavan, 1992).
La fonction objectif est minimisée en tenant compte d’un certain nombre de contraintes. Premièrement, puisque la fonction n’est pas définie pour des valeurs nulles a priori, il est nécessaire d’effectuer une transformation additive[9] pour chacun des éléments si certains sont nuls. Deuxièmement, une contrainte naturelle est posée afin d’assurer la non-négativité des éléments (équation 2). Le système tient également compte des contraintes provenant des règles de publication des données de l’EPA dont : i) le respect des seuils de divulgation pour chacune des régions économiques, si, lorsque la valeur initiale est nulle (qij = 0) (équation 3); ii) le respect de la règle d’arrondissement des données initiales – soit à la centaine près (0,1) (équation 4); iii) le total marginal du nombre d’emplois par secteur productif, q̄•j (équation 5); et iv) le total marginal par région économique, q̄•i (équation 6).
Les contraintes fixent l’ordre de grandeur de la répartition totale alors que l’ajustement porte sur la structure de la matrice. L’optimum répond au principe scientifique de Laplace qui stipule que lorsqu’aucune information supplémentaire ne permet de croire que des contraintes additionnelles peuvent être posées au problème d’optimisation, alors la nouvelle distribution obtenue est celle qui a le plus de chance de se réaliser.
L’application de la méthode MinXEnt repose sur la construction de matrices rectangulaires de données, une par année, qui exposent la répartition spatiale de l’emploi dans les régions économiques en fonction des secteurs productifs. Cette matrice de répartition, de dimension I × J, provient des données désagrégées de l’EPA.
3. Examen des résultats
Puisque les totaux marginaux peuvent varier entre le total des lignes (régions économiques) et des colonnes (secteurs productifs) étant donné les règles d’arrondissements, il est nécessaire d’effectuer certains compromis sur l’imposition des contraintes des totaux marginaux. Les règles de publications font en sorte qu’aucune des deux contraintes n’est totalement compatible avec le total provincial de l’emploi et qu’aucun des totaux provinciaux n’est compatible avec le total national. Ainsi, à moins d’ajuster proportionnellement les totaux marginaux en se basant sur le total national[10], il est nécessaire d’effectuer un choix quant à la contrainte serrante à imposer au système sur les totaux marginaux. Puisque les données de répartition de l’emploi par secteur productif par province sont disponibles pour l’ensemble des années[11], elles sont identifiées comme contraintes serrantes des totaux marginaux. Les totaux marginaux des régions économiques peuvent varier à la centaine près[12]. De plus, puisque la fonction objectif n’est pas déterminée pour des valeurs nulles a priori, une valeur de départ unitaire[13] est ajoutée à tous les éléments généraux qij.
Les nouvelles matrices de répartition de l’emploi, en fonction des secteurs productifs par région économique, permettent de prendre compte des règles d’arrondissements et de divulgation tout en respectant les contraintes imposées. Elles permettent d’assurer une cohérence des résultats tout en minimisant la « distance » ou « l’écart » entre la distribution de l’emploi publiée par l’EPA et la nouvelle distribution estimée. En tout, 22 matrices de distribution spatiale de l’emploi, une par année, sont obtenues[14]. Les résultats sont ensuite compilés dans une nouvelle base de données permettant de dresser le portrait de la répartition spatio-temporelle de l’emploi au Canada entre 1987 et 2008 selon la définition de l’EPA.
Les résultats sont imposants en termes de volume (chaque matrice est composée de 69 lignes et 16 colonnes), ce qui rend difficile la présentation détaillée des résultats[15]. Sans présenter formellement l’ensemble des tableaux de données, certains constats généraux émanent. Premièrement, étant donné les contraintes imposées au système, il s’avère que les nouvelles distributions permettent d’obtenir des résultats, par année et par province, qui sont cohérents avec les données provinciales de la répartition de l’emploi par secteur productif selon l’EPA. Deuxièmement, il est maintenant possible d’obtenir une estimation du nombre d’emplois pour chacun des secteurs productifs dans chacune des régions économiques, ce qui n’est pas le cas avec les données originales étant donné les règles de divulgation. Troisièmement, la méthode permet d’obtenir une estimation plus détaillée (et plus probable) du nombre d’emplois. Puisque les totaux marginaux sont supérieurs aux totaux de la répartition désagrégée de l’emploi compte tenu des restrictions imposées à leur divulgation, les estimations sont, règle générale, plus élevées que les données publiées. À titre d’exemple, le nombre d’emplois relié au secteur de l’agriculture (secteur 11) en 1987 pour la région économique de Toronto est de 7 500 selon l’EPA, alors que l’application de la méthode MinXEnt suggère que ce nombre est de 7 525.
De plus, la méthode fait en sorte qu’il est maintenant possible, à partir des données de répartition de 1995[16], d’obtenir une répartition du nombre d’emplois pour les régions économiques de la Colombie-Britannique entre 1987 et 1994 malgré que ces données ne soient pas disponibles a priori (graphique 1). Bien qu’il soit plutôt difficile d’établir la précision et la fiabilité de ces estimations, elles demeurent néanmoins intéressantes dans l’optique où certaines informations partielles sont disponibles pour établir les contraintes agrégées.
Graphique 1
Évolution du nombre total d’emplois (en milliers) pour deux régions économiques de la Colombie-Britannique (tous les secteurs productifs), 1987-2008

L’ensemble des corrections apportées aux estimations publiées du nombre d’emplois procure des séries chronologiques continues. Par exemple, le secteur économique des « services d’utilité publique (22) » pour les régions économiques de la Côte-Nord de la Nouvelle-Écosse (graphique 2) et de Parklands Nord (graphique 3) font maintenant état d’un nombre d’emploi non nul à chaque année. Le même constat s’applique au secteur économique « extraction minière et extraction de pétrole et de gaz (21) » pour la région économique de Montréal (graphique 4). D’une part, ces estimations permettent de calculer des taux de croissance pour chacune des années, calculs qui étaient jusque-là impossibles pour plusieurs secteurs productifs de plusieurs régions économiques. D’autre part, les estimations introduisent néanmoins des marges d’erreurs possiblement importantes dans les calculs des taux de croissance, bien que moins grandes que dans les séries originales.
Graphique 2
Évolution du nombre d’emplois (en milliers) du secteur productif « Services d’utilité publique – 22 » pour la région économique de la Côte-Nord (Nouvelle-Écosse), 1987-2008

Graphique 3
Évolution du nombre d’emploi (en milliers) du secteur productif « Services d’utilité publique – 22 » pour la région économique de Parklands Nord (Manitoba), 1987-2008

Graphique 4
Évolution du nombre d’emplois (en milliers) du secteur productif « Extraction minière et extraction de pétrole et de gaz – 21 » pour la région économique de Montréal, 1987-2008
Au final, l’application de la méthode MinXEnt permet d’obtenir une nouvelle base de données de type panel (ou pseudo-panel) qui respecte certaines contraintes provinciales et qui élimine les problèmes de ruptures et de discontinuités des séries chronologiques liées aux règles d’arrondissements ainsi que ceux de divulgation. À défaut de pouvoir utiliser les données « réelles »[17] de l’emploi régional sectoriel, il s’agit d’une estimation intéressante, complète et moins mauvaise. Cette approche peut facilement être extrapolée à plusieurs autres applications, ce qui en fait un outil intéressant pour les économistes régionaux. Par contre, le problème de la volatilité des taux de croissance calculés demeure entier étant donné deux réalités : i) la structure de l’échantillon de l’EPA et ii) la résolution strictement spatiale du problème d’optimisation, par opposition à une approche spatio-temporelle.
Une grande partie de la volatilité des séries provient de la méthode d’échantillonnage à deux degrés. Celle-ci a une incidence marquée lorsque les régions économiques s’étendent sur de grandes surfaces dont la densité de la population est faible et dont la répartition de l’emploi par secteur productif n’est pas uniformément distribuée sur le territoire. Une autre partie de la volatilité peut provenir d’un manque de spécification des contraintes par rapport à de réelles valeurs nulles dans certains secteurs productifs de quelques régions économiques. Cette possibilité aurait ainsi pour effet de faussement répartir une partie de la distribution vers d’autres cellules, accentuant ainsi la volatilité temporelle des séries.
Finalement, l’application de la méthode spatiale dans un contexte spatio-temporel s’avère incomplète et peut ainsi générer une autre source de volatilité des séries temporelles. Une application plus globale, permettant de considérer à la fois les dimensions temps et espace, serait une approche intéressante dans l’optique où elle permettrait de traiter directement cette partie du problème de volatilité et possiblement une autre partie liée à la structure de l’échantillon de l’EPA. Par contre, cette éventualité s’avère nettement plus complexe puisque la forme de la matrice à estimer est à trois dimensions (régions économiques, secteurs productifs et temps). La solution optimale passe par le développement d’une approche spatio-temporelle intégrée et une possible redéfinition des totaux marginaux afin de régler à la fois les problèmes de divulgation spatiale de certaines données et le problème de variabilité temporelle causé par une composition fortement changeante de l’échantillon à petite échelle.
Conclusion
Les données d’emploi provenant de l’Enquête sur la population active (EPA) permettent d’étudier l’évolution de l’emploi sectoriel au Canada pour un ensemble prédéterminé de régions géographiques, en l’occurrence les 69 régions économiques définies par Statistique Canada. Cependant, certaines faiblesses sont inhérentes à cette source de données. La première vient de toutes les données d’enquête dont l’échantillonnage change chaque mois : les séries chronologiques à faible fréquence (mensuelle, trimestrielle) issues de telles enquêtes sont nécessairement plus volatiles. La seconde vient du fait que le nombre d’emplois par secteur productif par région économique est différent du nombre total d’emplois par secteur productif par province. Des règles de divulgation et d’arrondissements font en sorte d’introduire des problèmes de ruptures et de discontinuités des séries chronologiques produisant des incohérences à des géographies plus fines. La troisième, issue de la seconde, vient d’une présence importante de valeurs zéro, fragilisant ainsi le calcul des taux de croissance de l’emploi pour certains secteurs productifs régionaux.
Une façon de contourner certaines faiblesses consiste à appliquer la méthode de minimisation de l’entropie croisée (MinXEnt) qui permet, à la lumière des données existantes, d’obtenir une nouvelle distribution spatiale de l’emploi par secteur productif et par région économique qui satisfait aux différentes contraintes fixées. Cette méthode permet d’obtenir, pour chacune des années, une distribution de l’emploi qui satisfait les contraintes de répartitions marginales de l’emploi par secteur productif par province en plus d’éliminer le problème des données manquantes. L’application de la méthode MinXEnt a également l’avantage de fournir une estimation du nombre d’emplois pour certaines régions économiques où ces données ne sont pas disponibles pour certaines années (Colombie-Britannique). Au final, l’article démontre qu’il est possible, à partir des données de sondage irréconciliables au départ, d’obtenir une nouvelle distribution de l’emploi qui soit cohérente avec les estimations globales. En d’autres termes, la méthode a l’avantage de permettre un raccord des séries chronologiques des données régionales de la moins mauvaise manière possible.
Cependant, certaines questions demeurent en suspens. La méthode MinXEnt ne peut régler la totalité des problèmes liés à la volatilité des données de l’emploi par secteur productif et région économique provenant de l’EPA. Une application plus globale permettant de considérer à la fois les dimensions temps et espace serait une approche intéressante, mais qui reste à développer, puisqu’elle permettrait d’attaquer à la fois les problèmes de divulgation et d’arrondissements des données ainsi que la structure et la rotation du plan d’échantillonnage.
Parties annexes
Remerciements
Cette recherche a été subventionnée par le Fonds québécois de recherche sur la société et la culture (FQRSC).
L’auteur tient à remercier monsieur Pierre Desgagnés du ministère des Transports du Québec (MTQ) avec lequel il a développé une collaboration sur un sujet semblable et qui lui a donné l’idée de développer cet article à saveur appliquée. L’auteur tient également à remercier Mario Polèse, André Lemelin et un évaluateur anonyme pour leurs commentaires qui ont permis d’améliorer la qualité de l’article. Cette recherche a été subventionnée par le Fonds québécois de recherche sur la société et la culture (FQRSC).
Notes
-
[1]
La méthode X-12-ARIMA est d’ailleurs retenue par Statistique Canada et le U.S. Census Bureau afin de produire des données désaisonnalisées (Hood et Feldpausch, 2003).
-
[2]
L’estimation est différente de ce que l’on peut obtenir lorsque l’ensemble de la population est interviewé.
-
[3]
Les personnes interviewées peuvent ne pas donner la réponse exacte ou peuvent encore approximer la réponse. Il s’agit de toutes les erreurs humaines reliées au sondage.
-
[4]
Par contre, les données régionales ne sont pas disponibles pour les régions économiques de la Colombie-Britannique avant 1995.
-
[5]
http://www.statcan.gc.ca/subjects-sujets/standard-norme/naics-scian/2002/naics-scian02l-fra.htm.
-
[6]
La méthode est présentée de façon rapide dans le présent article. Cependant, le lecteur intéressé par plus de détails peut consulter Theil (1967, 1971), Dubé (2003), Dubé et Dupéré (2004) et Dubé et Lemelin (2005).
-
[7]
Ces éléments ne respectent pas nécessairement les contraintes naturelles et celles posées par les règles imposées à divulgation des données.
-
[8]
La distribution a posteriori respecte les contraintes imposées.
-
[9]
Il s’agit d’ajouter un terme constant (valeur positive), mais très petit, à chacune des cellules.
-
[10]
Cet ajustement est plutôt arbitraire et c’est en partie pourquoi les contraintes sont fixées à partir d’une distribution marginale dont les chiffres sont supposés « plus fiables ».
-
[11]
Contrairement aux données par région économique qui ne sont pas disponibles pour la Colombie-Britannique entre 1987 et 1994.
-
[12]
Par contre, certains écarts sont plus élevés pour quelques années (1997, 2000 et 2007). Dans ces cas, la règle d’arrondissement est augmentée à deux centaines (0,2) (1997 et 2007) et à trois centaines (0,3) (2000). Cette règle est également relâchée pour les années antérieures à 1995 puisque les données ne sont pas disponibles pour les régions économiques de la Colombie-Britannique et que les valeurs initiales d’emploi utilisées sont celles de 1995, soit la première observation disponible.
-
[13]
La valeur unitaire indique que les valeurs de départ, pour les cellules où aucune information n’est disponible, sont fixées à un millier d’emplois.
-
[14]
Le problème d’optimisation est effectué à partir du logiciel GAMS. Les personnes intéressées à consulter le programme peuvent communiquer directement avec l’auteur.
-
[15]
Les résultats détaillés sont disponibles auprès de l’auteur sur demande.
-
[16]
L’approche suppose que la distribution de l’emploi en 1995 reflète bien la distribution de l’emploi pour les années manquantes antérieures.
-
[17]
La donnée réelle d’emploi n’est pas disponible à moins d’effectuer un recensement de l’emploi. Malgré tout, les données de l’EPA ont l’avantage d’être rajustées tous les cinq ans afin que les estimations reflètent la réalité des recensements.
Une répartition de l’emploi par secteur productif serait fort probablement plus juste avec les données de l’Enquête sur la rémunération et les heures de travail (EERH) qui est basée sur des fichiers administratifs. Cependant, l’EERH a le désavantage d’exclure, a priori, les travailleurs autonomes, diminuant ainsi le nombre d’emplois.
Bibliographie
- Dubé, J. (2003), « Estimation des flux d’échanges interrégionaux par la méthode de minimisation de l’entropie croisée », Mémoire de maîtrise codirigé par A. Lemelin et B. Decaluwé, Québec : Université Laval, 106 p.
- Dubé, J. et M. Dupéré (2006), « Une méthode de répartition pour déduire les flux d’échanges économiques », Bulletin économique du transport au Québec, ministère des Transports du Québec, 37 : 24-28.
- Dubé, J. et M. Dupéré (2004), Expérimentation de la méthode d’entropie croisée pour l’estimation d’échanges économiques à partir de flux de transport, Collection Études et recherches en transport, ministère des Transports du Québec, 38 p.
- Dubé, J. et A. Lemelin (2005), « Estimation expérimentale des flux d’échanges interrégionaux par la méthode de minimisation de l’entropie croisée », Revue canadienne de sciences régionales, 28(3) : 513-534.
- Hood, C.C. et R.M. Feldpausch (2003), Quelques propriétés des diagnostics de désaisonnalisation du modèle X-12-ARIMA, no. 11-522-XIF au catalogue, Statistique Canada, 12 p.
- Kapur, J.N. et H.K. Kesavan (1992), Entropy Optimization Principles with Applications, Academic Press, Inc., San Diego, CA, 405 p.
- Kullback, S. (1959), Information Theory and Statistics, John Wiley & Sons Inc., Canada, 395 p.
- Kullback, S. et R. Leibler (1951), « On Information and Sufficiency », Annals of Mathematical Statistics, 22 : 79-86.
- Macgill, S.M. (1977), « Theoritical Properties of Biproportionnal Matrix Adjustment », Environment and Planning A, 9 : 687-701.
- StatistiqueCanada (2009), Produits et services de l’Enquête sur la population active, no. 71-544-X au catalogue, Statistique Canada, 19 p.
- StatistiqueCanada (2008), Méthodologie de l’Enquête sur la population active au Canada, no. 71-526-X au catalogue, Statistique Canada, 122 p.
- Theil, H. (1967), Economics and Information Theory, vol. 7 dans la série « Studies in Mathematical and Managerial Economics », Rand McNally and Company, Chicago, 488 p.
- Theil, H. (1971), Principles of Econometrics, A Wiley/Hamilton Publications, John Wiley & Sons, Inc., 736 p.
Liste des figures
Graphique 1
Évolution du nombre total d’emplois (en milliers) pour deux régions économiques de la Colombie-Britannique (tous les secteurs productifs), 1987-2008
Graphique 2
Évolution du nombre d’emplois (en milliers) du secteur productif « Services d’utilité publique – 22 » pour la région économique de la Côte-Nord (Nouvelle-Écosse), 1987-2008
Graphique 3
Évolution du nombre d’emploi (en milliers) du secteur productif « Services d’utilité publique – 22 » pour la région économique de Parklands Nord (Manitoba), 1987-2008
Graphique 4
Évolution du nombre d’emplois (en milliers) du secteur productif « Extraction minière et extraction de pétrole et de gaz – 21 » pour la région économique de Montréal, 1987-2008
Liste des tableaux
Tableau 1
Seuil minimal de divulgation des données d’emploi de l’EPA par province (En deçà de ces seuils, les données ne sont pas publiées)
Tableau 2
Liste des secteurs industriels selon l’EPA et correspondance possible avec le SCIAN
Tableau 3
Nombre total d’emploi (en milliers) par province selon la méthode d’agrégation
Tableau 3 (suite)
Tableau 3 (suite)
Note : SP = secteur productif; RE = région économique
Tableau 4
Nombre total d’emplois (en milliers) par secteur productif selon la désagrégation géographique retenue