Résumés
Résumé
Notre société fait face à de nombreux risques qui affectent des vies humaines. Les autorités publiques doivent donc déterminer le budget optimal à consacrer à chaque projet visant à diminuer ces risques sociaux. L’analyse avantages-coûts est un outil très utilisé pour l’évaluation de ces projets. La tâche du gouvernement est de mettre en place des projets ou des réglementations qui génèreront des bénéfices supérieurs aux coûts de leur implantation. Les coûts sont habituellement assez faciles à déterminer, mais comment évaluer les bénéfices reliés à la sauvegarde de vies humaines? Depuis les années soixante-dix, le nombre d’études réalisées sur la mesure de la valeur statistique d’une vie humaine (VSV) est impressionnant. Plusieurs valeurs ont été estimées, et ce, à l’aide de différentes méthodes. La difficulté des gouvernements à choisir une valeur provient de la grande variabilité dans les résultats obtenus. En effet, les VSV observées varient de 0,5 million de dollars jusqu’à 50 millions de dollars ($ US 2000). L’objectif principal de cet article est d’aider à comprendre d’où vient cette grande variabilité dans les résultats. Nous voulons aussi déterminer quelle valeur nous semble la plus raisonnable.
Abstract
Our society faces many risks that affect human life. Cost-benefit analysis is a very popular project-evaluation tool for reducing these social risks. The government has to set projects or regulations whose benefits will outweigh costs. It is quite easy to evaluate costs but how to evaluate the benefits linked to protecting human life? Since the 1970s, many values of life have been estimated with different methods. The wide variability of the results range from 0,5 million up to 50 million ($US, 2000). The main goal of this study is to analyze the source of this variability in results. We also want to determine a reasonable value for public decision making.
Corps de l’article
Introduction
Notre société fait face à de nombreux risques qui affectent des vies humaines, notamment dans certains domaines tels que la santé (SRAS, VIH, H1N1, H5N1, etc.), l’environnement, les catastrophes naturelles, les transports (accidents de la route, maritimes et aériens) ainsi que la sécurité au travail. Il ne faut pas être utopique et penser que les risques doivent être éliminés complètement mais ils doivent être compensés et gérés efficacement. Les autorités publiques doivent donc déterminer le budget optimal à consacrer à chaque projet visant à diminuer les risques.
L’analyse avantages-coûts est un outil très utilisé pour l’évaluation de projets qui réduisent ces risques sociaux. La tâche du gouvernement est de mettre en place des projets ou des réglementations qui génèreront des bénéfices supérieurs aux coûts de leur implantation. Les coûts sont habituellement assez faciles à déterminer, mais comment évaluer les bénéfices reliés à la sauvegarde de vies humaines? Il est important de mentionner que nous ne parlons pas de la valeur d’une vie en particulier, mais bien d’un individu complètement anonyme parmi la société. Pour éviter les confusions, nous utiliserons l’appellation « valeur statistique d’une vie » (VSV). Nous ne voulons en aucun temps aborder les aspects sentimentaux et éthiques que pourrait engendrer une telle problématique. Si une petite fille court le risque de tomber dans un puits, le gouvernement (ou la communauté) serait probablement incité à dépenser une somme très importante pour la protéger. Une même somme qui, investie ailleurs (infrastructures routières par exemple), aurait pu sauver plusieurs vies (Thaler, 1974). Il est aussi essentiel de comprendre que le concept de la VSV ne repose pas sur la valeur certaine d’un décès, mais bien sur la valeur d’une petite variation du risque de décès (Viscusi, 2005)[1].
Tous les jours, les individus prennent des décisions qui reflètent la valeur qu’ils associent à leur santé et leur risque de décès, que ce soit en conduisant leur automobile, en fumant, ou en ayant un emploi dangereux (Viscusi et Aldy, 2003). Le risque observé fait en quelque sorte partie des préférences révélées des individus. Chaque individu choisit, en partie, le niveau d’exposition au risque qui lui est optimal. Tout comme les gouvernements, la minimisation inconditionnelle du niveau de risque est non désirable pour l’individu en particulier. C’est par ces décisions de marché, impliquant habituellement un arbitrage entre le risque et une certaine somme d’argent, que les économistes tentent de mesurer le montant que la société est prête à payer pour sauver une vie humaine.
Depuis les années soixante-dix, le nombre d’études réalisées sur la mesure de la valeur statistique d’une vie humaine est impressionnant. Plusieurs valeurs ont été estimées, et ce, à l’aide de différentes méthodes. La difficulté des gouvernements à choisir une valeur provient de la grande variabilité dans les résultats obtenus. En effet, les VSV observées varient de 0,5 million de dollars jusqu’à 50 millions de dollars ($ US 2000).
L’objectif principal de cet article est d’aider à comprendre d’où vient cette grande variabilité dans les résultats. Viscusi et Adly (2003), Treich (2005) et Andersson et Treich (2008) ont présenté des revues très complètes de la littérature empirique mais n’ont pas isolé les facteurs expliquant la grande variabilité des résultats obtenus dans la littérature. Notre contribution consiste donc à analyser la sensibilité des valeurs obtenues empiriquement par rapport aux caractéristiques de la population à l’étude (revenu moyen, niveau de risque initial, race, sexe, etc.). Nous voulons aussi vérifier si les différences de méthodologies entre les études influencent les résultats obtenus. À notre connaissance, c’est la première revue de la littérature mettant l’accent sur les différences dans les diverses méthodologies économétriques pour expliquer la grande variabilité des valeurs publiées dans la littérature (voir Bellavance et al., 2009, pour une méta-analyse sur ce sujet). Nous voulons aussi déterminer quelle valeur nous semble la plus raisonnable lorsque les biais méthodologiques sont corrigés. Nous croyons que nos résultats permettront de mieux comprendre toute la problématique entourant l’évaluation d’une vie humaine et aideront à mieux mettre en garde les décideurs publics face au choix d’une valeur dans leurs analyses avantages-coûts.
Les deux prochaines sections de cet article consistent en une revue de la littérature qui présente les principales méthodes utilisées pour inférer la VSV. Nous faisons en même temps un survol des travaux ayant le plus contribué à l’avancement des connaissances sur le sujet. La première section étudie l’approche du capital humain, qui associe la valeur de la vie d’un individu à sa contribution économique au bien-être de la société. Nous analysons ensuite l’approche de la disposition à payer (DAP). Cette dernière se base sur la volonté à payer d’un individu pour réduire son risque de décès ou sa disposition à accepter un certain montant (prime salariale) pour voir son espérance de vie diminuer (exposition au risque d’accident du travail). Étant l’approche la plus acceptée et la plus documentée, nous y consacrons la plus grande partie de cet exposé. Nous effectuons une dérivation théorique du modèle et nous tentons de déduire le comportement de la volonté à payer suite à une variation dans la richesse initiale ainsi qu’une variation de la probabilité de décès initiale de l’individu. Nous regardons également la relation qu’il y a entre l’aversion au risque d’un individu et sa volonté à payer. Cette section nous permet de mieux comprendre les concepts qui sont utiles lors des études empiriques[2].
La troisième section analyse les concepts de base dans l’utilisation de la disposition à payer agrégée des politiques publiques impliquant la sauvegarde de vies humaines. Nous y présentons, entre autres, un article de Drèze (1992) où celui-ci propose une approche intéressante permettant d’utiliser la disposition à payer dans la détermination du niveau de sécurité optimal par les sociétés.
Nous montrons, étape par étape dans la section quatre, la façon dont les chercheurs parviennent empiriquement à mesurer la valeur statistique d’une vie humaine. Nous effectuons également un survol des différents choix méthodologiques effectués par les chercheurs et pouvant avoir un impact sur l’estimation de la VSV.
La cinquième section se consacre entièrement à l’application de la méta-analyse dans l’évaluation de la VSV. Le début de cette section présente en détail la méthodologie retenue pour effectuer les méta-analyses et nous discutons plus en détail de l’approche de Bellavance et al. (2009). Celle-ci repose sur le modèle à effets mixtes (Raudenbush, 1994). Nous croyons qu’elle est la plus appropriée pour ce genre de recherche statistique, puisqu’elle tient compte de l’hétérogénéité dans les estimations de la valeur de la vie. C’est par cette approche innovatrice que cette étude se distingue des autres méta-analyses effectuées sur le sujet. Nous faisons ensuite un survol de quelques méta-analyses présentes dans la littérature et portant sur la valeur statistique d’une vie humaine. Finalement, en conclusion, nous discutons des implications de ces résultats pour les décideurs publics et proposons une valeur raisonnable à utiliser qui nous paraît être la plus à l’abri des erreurs méthodologiques.
1. Le capital humain
Cette approche mesure la valeur d’une vie humaine à partir de sa contribution au bien-être de la société. Elle se calcule en termes de revenu et de production. Dublin et Lotka (1947) définissent la valeur d’une vie humaine comme étant la valeur actualisée des revenus nets futurs d’un individu. Cela correspond à ses revenus bruts moins ce qu’il dépense pour lui-même (soit sa consommation). Selon cette approche, la valeur d’une vie est obtenue de la façon suivante :
Cette approche a la qualité d’être actuarielle et simple d’application. Mais elle s’est attiré un grand éventail de critiques. D’abord, en se concentrant seulement sur les revenus, cette approche oublie complètement le désir individuel de vivre (Arthur, 1981) et donc les préférences des individus. Par exemple, une découverte médicale qui prolongerait l’espérance de vie de 75 à 85 ans n’aurait aucune justification sociale, puisqu’à cet âge les revenus de travail sont habituellement nuls. Ensuite, l’hypothèse que la maximisation du bien-être nécessite la maximisation du PIB n’est pas tout à fait juste. En effet, supposons un projet d’investissement impliquant la construction d’une usine très polluante. La résultante serait une augmentation du PIB, mais il n’est pas certain que le bien-être général de la population en serait augmenté. L’approche du capital humain ne tient donc pas compte des coûts sociaux. De plus, nous pouvons mettre en doute la pertinence de la variable Yn (revenus bruts) pour mesurer la contribution d’un individu au bien-être d’une société. Une telle méthode soutiendrait qu’un joueur de hockey apporte plus à une société qu’un médecin ou un professeur. Finalement, l’utilisation stricte d’une telle approche peut attribuer une valeur nulle ou négative à la vie de retraités, de femmes au foyer et de chômeurs, puisqu’ils n’ont aucun revenu de travail. Cela soulève une sérieuse question d’équité.
Nous pouvons utiliser l’approche brute pour éviter d’obtenir des valeurs négatives. Celle-ci est présentée à l’équation (2). L’interprétation économique de cette modification stipule que la consommation (Cn), soustraite des revenus bruts de l’individu dans l’approche nette, doit plutôt être ajoutée pour tenir compte de la perte pour cet individu (de ne plus consommer). L’approche nette est toutefois plus cohérente avec les théories du capital. En effet, les flux de revenus du capital (humain) y sont ainsi calculés en déduisant les coûts de maintenance (subsistance), comme tout capital non humain.
À ses débuts, l’approche du capital humain apporta beaucoup aux théories d’assurance-vie. Celle-ci fut également introduite en économie de la santé par des travaux de Fein (1958) sur les maladies mentales, de Mushkin (1962) et de Rice (1967). Au cours des années, la méthode a été généralisée pour tenir compte de la croissance des salaires due à la croissance de la productivité (Department of Health and Human Services, 2009). Dans ce document, on montre également comment ternir compte des avantages sociaux et du travail ménager dans le revenu brut (voir également Rice et al., 1989).
À partir des années soixante, une nouvelle approche est apparue dans la littérature, celle de la disposition à payer (DAP). Plusieurs chercheurs, dont Dionne et al. (2002), recommandent de ne plus utiliser l’approche du capital humain et soutiennent que la DAP repose sur des fondements théoriques beaucoup plus solides. Toutefois, dans la pratique, les analystes et les décideurs font encore souvent référence à l’approche du capital humain.
2. La disposition à payer
Ces dernières années, l’approche la plus populaire dans la littérature économique pour déterminer la valeur statistique d’une vie humaine est sans contredit celle de la disposition à payer (willingness-to-pay). La valeur de la vie est mesurée par le montant qu’une personne est prête à payer pour diminuer son exposition au risque. À l’opposé, la disposition à accepter (willingness-to-accept) est le montant qu’une personne serait prête à accepter pour voir son exposition au risque augmenter. La valeur statistique d’une vie humaine se calcule donc par la somme d’argent qu’une société est prête à payer pour réduire l’exposition au risque de chacun de ses membres. On valorise ainsi l’effort monétaire fourni pour réduire la probabilité de décès.
Cette approche a plusieurs avantages comparativement à celle du capital humain. D’abord, elle tient compte du désir individuel de vivre plus longtemps (Arthur, 1981). Une découverte médicale qui prolongerait l’espérance de vie de 75 à 85 ans aurait une justification sociale avec cette approche. En effet, la plupart des personnes seraient disposées à payer un certain montant pour bénéficier de ces années supplémentaires. Ce concept valorise donc la vie en soi et non pas seulement les conséquences de la mort, ce qui évite les valeurs nulles ou négatives (Le Pen, 1993).
Prenons, par exemple, une société composée de 1 million de personnes qui envisagent de financer un projet public de sécurité. Supposons que ces personnes sont prêtes à payer 100 $ en moyenne pour réduire la probabilité de décès de 3/100 000 à 1/100 000, ce qui correspond à 20 vies pour cette société. La disposition à payer pour sauver ces 20 vies est de 100 millions de dollars. Cela équivaut à 5 millions de dollars par vie sauvée. Il y a deux grandes méthodes pour mesurer la disposition à payer. Il y a l’approche par les préférences révélées (ou déclarées), ainsi que la méthode d’évaluation contingente.
2.1 L’approche des préférences révélées
L’hypothèse de cette méthode soutient que les individus révèlent leurs préférences par leur comportement sur le marché. Leurs préférences pour le risque se reflètent dans des décisions impliquant un arbitrage entre une certaine somme d’argent et un risque. Cette approche a l’avantage de se baser sur des faits réels et observables[3].
La majorité des travaux utilisant cette méthode sont du type risque-salaire. Son but est de mesurer la valeur d’une augmentation du risque dans un environnement de travail. Pour ce faire, on construit une base de données incluant plusieurs types d’emplois. On trouve les salaires moyens de ces emplois, les niveaux de risque de décès associés et quelques caractéristiques reliées à l’emploi. On effectue ensuite une régression des salaires moyens sur les différentes caractéristiques. Le coefficient obtenu associé à la variable risque correspond à une prime de risque salariale en pourcentage que l’individu accepte en échange d’une variation de risque marginale. Il s’agit ici d’une disposition à accepter (ou à recevoir).
Certains auteurs sont plutôt sceptiques quant à l’utilisation des divergences de salaires pour inférer la disposition à accepter des individus à la suite d’une variation du risque de mortalité. Le Pen (1993) énumère quatre grandes raisons qui poussent à croire que les différences entre salaires ne sont pas de bonnes mesures des différences de risque de mortalité entre emplois :
L’information que détiennent les travailleurs sur les risques qu’ils encourent est imparfaite.
Les emplois risqués attirent en général des individus ayant une aversion au risque plus faible, exigeant des primes de risques moins élevées.
Il y a des imperfections sur le marché du travail.
La prime de risque effective ne couvre pas seulement le risque de décès, mais l’ensemble des risques encourus (blessures, invalidités, etc.).
Dans un même ordre d’idées, Dionne et Lanoie (2004) soulignent que l’approche des préférences révélées utilisant la méthode risque-salaire ne peut fonctionner que si les deux hypothèses suivantes sont respectées. D’abord, on suppose que les travailleurs sont en situation d’information complète sur les risques encourus des différents emplois. Si cette information n’est pas juste, alors les demandes salariales pour ces emplois ne reflèteront plus les vrais risques et les résultats de l’étude seront biaisés[4]. La deuxième hypothèse stipule que chaque travailleur choisit librement son emploi et peut le changer quand bon lui semble. Cette hypothèse permet également d’avoir des primes de risque non biaisées. Par exemple, si un travailleur ne peut changer d’emploi facilement à la suite d’une hausse de son risque et que son salaire n’augmente pas convenablement, la prime de risque ne reflètera plus le vrai risque encouru.
La principale difficulté dans l’application de la méthode risque-salaire repose sur la construction de la base de données. En effet, pour être le plus juste possible, il faut construire une base très désagrégée sur chaque type d’emplois dans une même industrie, ce qui peut entraîner un très grand nombre de catégories.
D’autres travaux utilisant la même méthode des préférences révélées tentent de déduire les préférences des individus dans leurs choix de consommation quotidienne. Plus spécifiquement il s’agit d’analyser les choix impliquant des arbitrages entre des montants et des risques, comme lors de l’achat d’un détecteur de fumée. Encore une fois, les consommateurs doivent avoir accès à l’information exacte concernant les niveaux de réduction de risque reliés à l’achat de ces biens. Dans le cas contraire, l’analyse sera encore une fois biaisée[5].
2.2 L’approche de l’évaluation contingente
Développée dans les années cinquante, cette approche s’est beaucoup perfectionnée depuis. La quantité de travaux utilisant cette méthode ne cesse de se multiplier, surtout aux États-Unis et en Grande-Bretagne. La raison de cette popularité vient du fait qu’elle est applicable pour toute la population et non pas seulement les salariés, en toute circonstance et pour toute valeur économique.
Son principe est simple. Il s’agit de construire un questionnaire qui permet de révéler la disposition à payer des répondants face à des situations de marché hypothétiques. Cette méthode tente ainsi d’imiter les comportements sur le marché normal (réel), mais sans les imperfections pouvant biaiser les montants révélés. Le grand avantage de cette méthode consiste en la possibilité pour le chercheur de construire son questionnaire et de choisir son échantillon pour en retirer exactement l’information désirée (Lanoie et al., 1995). Par contre, les personnes ayant complété le questionnaire auraient peut-être répondu différemment si elles avaient été réellement confrontées à la situation. Il s’agit du principal inconvénient de cette méthode.
2.3 Le modèle théorique de la DAP
Le modèle standard pour évaluer la valeur d’une vie humaine, basé sur le concept de la disposition à payer, fut initialement formulé par Drèze (1962). Par la suite, il fut principalement popularisé par Schelling (1968), Mishan (1971), Jones-Lee (1976) et Weinstein et al. (1980). Analysons maintenant, en détail, la conception et les hypothèses de ce modèle.
Le modèle stipule que chaque individu est doté d’une richesse initiale w et est sujet à seulement deux états de la nature possibles durant la période, soit être vivant (v) ou mort (m). Les probabilités associées à ces états sont respectivement (1 – p) et p. Le bien-être de l’individu est représenté par son utilité espérée,
De façon intuitive, on peut supposer que l’individu préfère la vie à la mort et donc que l’utilité retirée de la richesse est supérieure dans l’état v que dans l’état m. Nous avons l’inégalité suivante :
Cette richesse est la même dans les deux états de la nature, puisqu’on suppose que l’individu a accès à un marché d’assurances pour se couvrir de toutes pertes financières ou matérielles (Dionne et Lanoie, 2004)[6].
La littérature propose souvent que l’utilité marginale retirée de la richesse est supérieure dans l’état de survie que dans l’état de décès,
Cette hypothèse provient, entre autres, de Pratt et Zeckhauser (1996), qui fondent leur argumentation sur un dead-anyway effect. Selon eux, l’individu doit nécessairement profiter davantage d’une augmentation de sa richesse alors qu’il est en vie plutôt que lorsqu’il est décédé.
L’individu a également une aversion au risque dans les deux états de la nature. Cela signifie que son utilité marginale est décroissante dans les deux états de la nature,
Comme mentionné plus haut, la disposition à payer correspond au montant qu’une personne est prête à payer pour diminuer son exposition au risque. Dans ce modèle, il s’agit de se demander quel montant x de sa richesse initiale w l’individu serait prêt à payer pour voir sa probabilité de décès p se réduire à p*, tout en gardant son utilité espérée constante. Il suffit donc de trouver le x qui satisfait cette égalité :
Pour trouver la DAP, ou le terme x qui résout l’équation (7), il suffit d’effectuer la différentielle totale de l’équation (7) par rapport à w et p, sous l’hypothèse qu’elle demeure constante,
Par substitutions, nous trouvons :
soit la disposition à payer marginale, correspondant au taux marginal de substitution entre la richesse et la probabilité de décès. Le terme au numérateur représente la différence, en termes d’utilité, entre la vie et la mort. Le dénominateur représente l’espérance de l’utilité marginale de la richesse. C’est cette expression qui est utilisée dans les études empiriques pour calculer la valeur statistique d’une vie. Avec ce montant que l’individu est prêt à payer pour éviter une petite variation de risque (dp), nous pouvons déterminer la valeur de la vie correspondante : (dw/dp)/Δp. Si l’on reprend l’exemple vu précédemment, où l’individu moyen d’une société est prêt à payer 100 $ pour réduire sa probabilité de décès de 3/100 000 à 1/100 000, on trouve que le Δp correspondant est de 2/100 000 et que dw/dp est de 100 $. La valeur de la vie correspondante est donc de 100/(2/100 000), soit de 5 millions de dollars.
À l’aide de l’hypothèse (4), nous pouvons affirmer que l’individu demandera toujours une compensation positive pour subir une augmentation de son risque. À l’inverse, il acceptera toujours une compensation négative pour profiter d’une diminution de son risque.
Afin de déterminer la forme des courbes d’indifférence dans le plan (w, p), nous devons d’abord effectuer une dérivée de la disposition à payer par rapport à p, pour déterminer comment elle réagit face à une variation de son exposition au risque initiale :
Le résultat est ambigu et dépend de l’hypothèse de l’équation (5). Si nous l’acceptons et affirmons que l’utilité marginale de la richesse est supérieure dans l’état de survie, alors nous pouvons avancer, tout en tenant compte des équations (4) et (5), que l’équation (10) est positive. Ainsi, la disposition à payer de l’individu croît avec son niveau de risque initial. L’interprétation économique de ce résultat démontre que les individus préalablement exposés à un plus grand risque (pompiers, mineurs, etc.) devraient, en général, être plus réticents à une augmentation de leur risque que d’autres individus, et ce, pour un même niveau de variation. Ce résultat n’obtient toutefois pas l’unanimité parmi les auteurs sur le sujet. Smith et Desvousges (1987), à l’aide d’un questionnaire, obtiennent des résultats contraires. En effet, la DAP est davantage élevée pour des risques plus faibles. Breyer et Felder (2005), analysent précisément la relation entre le risque de décès initial et la disposition à payer des individus dans diverses circonstances. Ils arrivent à deux grandes conclusions. Tout d’abord, en présence d’un marché d’assurance parfait, un individu égoïste[7] et possédant une aversion pour le risque verra toujours sa DAP augmenter avec le risque de décès. Cependant, ceci est principalement dû à un effet revenu plutôt qu’au dead-anyway effect de Pratt et Zeckhauser (1996). Ensuite, pour un individu altruiste, les auteurs affirment que le résultat peut être inversé. Il arrive que la DAP diminue avec le risque initial. Une condition suffisante consisterait à ce qu’une partie significative de la richesse soit perdue lors du décès de l’individu (comme du capital humain). Parallèlement, Dionne et Eeckhoudt (1985) et Dachraoui et al. (2004) soutiennent qu’il est très difficile de prédire la décision d’autoprotection[8] et de volonté à payer lorsque la probabilité d’accident est inférieure à ½. Les auteurs démontrent que, dans un tel cas, l’effet d’une variation du p peut se traduire autant par une baisse que d’une hausse de la prime de risque. Ceci s’applique à notre analyse, puisque la probabilité de décès initiale est souvent inférieure à ½. Nous allons donc conclure que la relation entre la DAP et le risque de décès initial reste ambiguë. Il est à noter que les littératures sur la DAP et l’autoprotection se recoupent, car elles utilisent des modèles semblables (Dachraoui et al., 2004).
Il est également intéressant d’effectuer une dérivée de la DAP par rapport à w, afin de trouver l’effet de la richesse initiale sur la DAP. Intuitivement on peut s’attendre à ce qu’une personne plus riche soit disposée à payer davantage qu’une personne plus pauvre. Après quelques calculs nous trouvons :
Encore une fois, si nous acceptons les hypothèses (5) et (6), nous pouvons affirmer que l’équation (11) est positive. La disposition à payer augmente avec le niveau de richesse initiale de l’individu. Ce résultat ne constitue pas vraiment un problème puisqu’il fait l’unanimité dans la littérature. Il soulève cependant une question d’équité. Comme le souligne Michaud (2001), les projets qui concernent des gens aisés risquent d’être préférés aux projets qui touchent des gens plus pauvres.
Si nous acceptons l’hypothèse que l’utilité marginale de la richesse est plus élevée dans la vie que dans la mort, les signes des équations (10) et (11) sont positifs et nous pouvons tracer les courbes d’indifférence de l’individu entre sa richesse et sa probabilité de décès. Comme l’illustre le graphique 1, les courbes d’indifférence sont convexes et leurs pentes sont positives. La pente des courbes d’indifférence correspond au taux marginal de substitution entre la richesse et la probabilité de décès, soit la disposition à payer de l’individu. Pour un même niveau d’utilité espérée, une augmentation de la richesse et de la probabilité de décès augmente la pente de la tangente, donc augmente la DAP. Similairement, pour une même probabilité de décès, l’individu passe nécessairement à un niveau d’utilité espérée supérieur, lorsque sa richesse augmente. À l’inverse, pour un niveau de richesse fixe, une augmentation de sa probabilité de décès entraîne une baisse de son utilité espérée.
Graphique 1
Forme des courbes d’indifférence entre la richesse et la probabilité de décès

2.4 L’aversion au risque et la DAP
La littérature suggère fréquemment que l’aversion au risque peut modifier la disposition à payer des individus. On prétend souvent que les individus ayant une plus grande aversion au risque sont disposés à payer davantage pour réduire leur probabilité de décès (Eeckhoudt et Hammitt, 2001). Ceci peut créer des problèmes dans la détermination de la valeur statistique d’une vie humaine à l’aide d’une méthode risque-salaire. En effet, dans le marché compétitif du travail, il y a une répartition naturelle des individus plus riscophobes vers les emplois moins risqués et vice versa. Les études qui utilisent une méthode risque-salaire pourraient donc sous-estimer la valeur statistique de la vie des individus qui décident de ne pas travailler dans des emplois risqués et surestimer la valeur de la vie des individus qui détiennent des emplois plus risqués (Eeckhoudt et Hammit, 2004).
Dachraoui et al. (2004), tentent d’expliquer comment les comportements des gens face aux risques influencent leur disposition à payer pour réduire ces risques. Pour y arriver, ils utilisent le concept d’aversion au risque mélangée (mixed risk aversion), qui est souvent attribuée aux fonctions d’utilité croissantes ayant des dérivées de signes alternés[9]. Ils démontrent que, si un individu A est plus riscophobe qu’un autre individu B, il aura une disposition à payer pour réduire son risque plus élevée que B, seulement si la probabilité de décès est inférieure à ½. Li et Dionne (2010) montrent qu’une condition suffisante pour qu’un individu riscophobe ait une disposition à payer (réalise plus de prévention) qu’un individu risconeutre est que son niveau de prudence (–U'"/U") soit inférieur à une certaine borne pouvant être mesurée à l’aide de la skewness de la distribution de la perte (voir aussi Eeckhoudt et Gollier, 2005). Nous pouvons ainsi affirmer qu’en général, la disposition à payer des individus peut augmenter avec l’aversion au risque, puisque dans plusieurs cas cette condition sera respectée. (Pour une étude récente sur la relation aversion au risque et valeur de la vie, voir Bommier et Villeneuve, 2011.)
3. La DAP et la politique publique optimale
Cette section analyse les concepts de base dans l’utilisation de l’approche de la disposition à payer pour les politiques publiques impliquant la sauvegarde de vies humaines. Nous introduisons du même coup les plus importantes critiques à son sujet. Nous examinons en particulier les travaux de Drèze (1992), de Pratt et Zeckhauser (1996), ainsi que ceux de Viscusi (2000).
Le concept de la disposition à payer pour réduire le risque de mortalité est certainement l’approche la plus commune et la plus acceptée auprès des économistes (Viscusi, 1993). La majorité s’entend pour dire que la DAP est présentement la meilleure méthode pour mesurer les préférences individuelles. Toutefois, dans la plupart des analyses avantages-coûts impliquant des projets gouvernementaux, il ne s’agit pas de mesurer l’impact sur les préférences individuelles mais bien collectives.
Plusieurs auteurs se sont donc penchés sur la façon optimale d’agréger les DAP individuelles pour arriver à une mesure sociale. Les pratiques courantes en matière d’analyse avantages-coûts évaluent les projets gouvernementaux en comparant la moyenne des DAP individuelles avec les coûts per capita des différents projets. Cette façon de faire est cependant critiquée par plusieurs chercheurs en économie publique et environnementale.
3.1 La quantité efficiente de sécurité
Drèze (1992) utilise une approche qui permet d’utiliser la DAP pour déterminer le niveau de sécurité optimal qu’un gouvernement devrait établir. Les conditions d’optimalité de ce modèle nous apportent quelques intuitions pertinentes au problème d’agrégation des préférences. Supposons une société composée de n individus (i = 1… n). Chaque individu choisit simultanément un niveau de dépense zi en sécurité publique, où
est la dépense totale de l’intervention publique. La probabilité de décès est pi(z) avec
puisque l’augmentation de la dépense en sécurité diminue la probabilité de décès. L’espérance d’utilité individuelle est donc illustrée comme suit :
et
Nous pouvons éliminer le multiplicateur λi de chacune des deux CPO pour obtenir,
Il s’agit donc du montant maximum que l’individu i serait prêt à payer pour voir sa probabilité de décès diminuer de pi.
Le terme ![]() dans l’équation (18) est celui en (13) et de signe négatif. Drèze continue son raisonnement en définissant
dans l’équation (18) est celui en (13) et de signe négatif. Drèze continue son raisonnement en définissant
comme étant le coût marginal pour sauver une vie par l’intervention publique. Nous pouvons donc réécrire (18) avec l’aide de (20) :
et
Ensuite, en ajoutant et en soustrayant la moyenne des DAP calculées ![]() au membre de droite :
au membre de droite :
et
Si nous prenons comme hypothèse qu’il n’y a pas de covariance entre ![]() et la mesure de disposition à payer φi, alors le terme de cov(·,·) de l’équation (25) est nul et nous obtenons :
et la mesure de disposition à payer φi, alors le terme de cov(·,·) de l’équation (25) est nul et nous obtenons :
La quantité de sécurité publique efficiente est donc obtenue lorsque le coût marginal pour sauver une vie est égal à la moyenne des dispositions à payer marginales dans la population.
Sans cette hypothèse, l’utilisation de la moyenne des dispositions à payer va créer un biais, puisqu’on oublie la covariance de l’équation (25). Dans la réalité, cette hypothèse n’est pas tout à fait plausible. Il y a certainement un lien entre la disposition à payer des individus et leur ![]() . Plus la probabilité de décès (pi) d’un individu diminue avec l’intervention publique (z), plus il devrait être disposé à payer pour en profiter.
. Plus la probabilité de décès (pi) d’un individu diminue avec l’intervention publique (z), plus il devrait être disposé à payer pour en profiter.
3.2 Hétérogénéité dans les risques
Chaque individu est confronté à des niveaux de risque différents, ce qui influence du même coup les bénéfices retirés de chaque intervention. Viscusi (2000) va même jusqu’à décrire trois sources d’hétérogénéité dans les risques dont nous devrions tenir compte, afin de prendre des décisions plus efficientes en sécurité publique. D’abord, il y a l’hétérogénéité dans les expositions aux risques : chaque individu fait face à des niveaux de risques différents selon son travail, son âge, son sexe, etc. Par exemple, un employé de la construction a plus de chance de mourir d’un accident de travail qu’un employé de bureau. Une personne de 70 ans est plus susceptible de décéder d’un infarctus qu’une jeune personne.
Deuxièmement, nous retrouvons de l’hétérogénéité dans les dispositions à accepter le risque. Par exemple, certaines personnes vont éviter de marcher dans les parcs la nuit par crainte d’être la cible d’une agression, tandis que d’autres ne le percevront pas comme un si grand risque. De plus, les gens moins riscophobes auront tendance à accepter une plus faible compensation monétaire pour travailler dans des emplois dangereux.
Finalement, il y a l’hétérogénéité dans les préférences pour des activités qui impliquent des risques. La plongée sous-marine, le ski alpin, la motocyclette ou même la cigarette introduisent un plus grand risque, mais ces activités procurent également une satisfaction pour ceux qui les pratiquent, autres que le risque en soi. Cette satisfaction varie d’une personne à l’autre.
Ces trois différentes sources d’hétérogénéité dans les risques sont évidemment très reliées. Les gens qui se passionnent pour les activités qui introduisent des risques élevés devraient être moins riscophobes. La cigarette est probablement le meilleur exemple pour illustrer ceci. Une étude de Viscusi et Hersch (1998) montre effectivement que les hommes fumeurs ont 16 % plus de chance de ne pas mettre leur ceinture de sécurité en voiture que les hommes non fumeurs.
3.3 Concentration des risques
Pratt et Zeckhauser (1996) montrent également que la concentration ou la dispersion des risques dans une population visée peut affecter la mesure de la disposition à payer agrégée. Supposons n individus, avec un risque agrégé égal à P. Chaque individu fait face à un risque moyen de p = P/n et une diminution de risque associée à un projet de r = R/n. Les auteurs cherchent à savoir comment la disposition à payer agrégée pour réduire P d’une quantité R est affectée par le nombre d’individus exposés (n). Deux effets peuvent influencer le résultat :
Le dead-anyway effect entraîne que plus le risque est concentré, plus les personnes cibles deviennent identifiables et plus la disposition à payer est élevée. Par exemple, un individu atteint d’une grave maladie serait probablement prêt à sacrifier toute sa richesse pour une mince chance de survie.
Le high-payment effect, à l’opposé, fait en sorte que plus le risque est concentré, plus les gens concernés vont payer, ce qui augmente leur utilité marginale de la richesse en présence d’aversion au risque. Il se produit en quelque sorte un effet revenu qui, pour un gain d’utilité donné, diminue la DAP des gens concernés lorsque le risque est plus concentré. Par exemple, la disposition à payer d’une petite communauté pour réduire une certaine probabilité de décès provenant de déchets toxiques pourrait atteindre 1 million de dollars. Par contre, il est peu probable qu’un individu supportant le risque à lui seul payerait 1 million de dollars pour la même réduction de probabilité de décès.
À l’aide de fonctions d’utilité identiques à celles que nous avons utilisées à la section 2, Pratt et Zeckhauser illustrent la relation d’arbitrage entre ces deux effets. Trois courbes sont représentées dans le graphique 2 : une première pour une réduction de 1/4 du niveau de risque initial, une deuxième pour une réduction de 1/6 et une dernière pour une réduction de 1/10.
Lorsque la pente d’une courbe est toujours positive, cela indique que l’effet de paiement élevé (high-payment effect) domine, ce qui implique que la DAP est plus faible lorsque le risque est plus concentré. Lorsque la pente d’une courbe est toujours négative, nous avons l’effet contraire et c’est l’effet de mort imminente (dead-anyway) qui domine : la DAP devient plus élevée lorsque le risque est plus concentré.
Graphique 2
Disposition à payer agrégée selon la concentration du risque
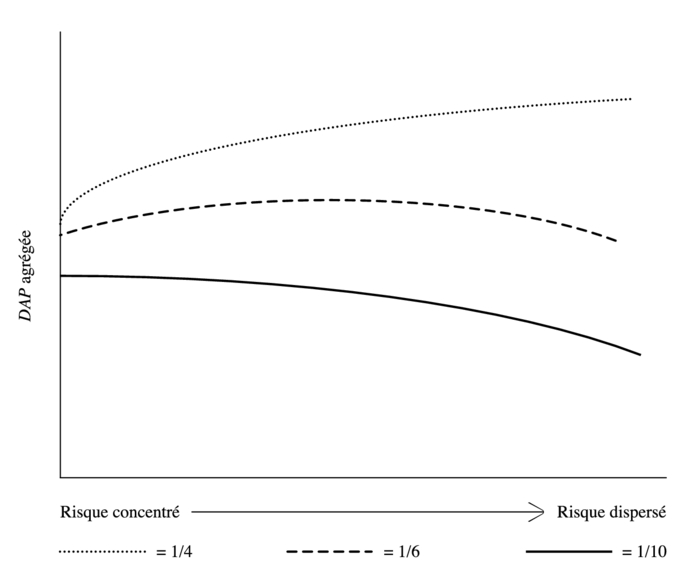
Comme prévu, la disposition à payer est plus élevée pour une grande réduction de risque (1/4) et plus faible pour une petite réduction (1/10). Les courbes ont trois formes différentes. D’abord pour une grande réduction de risque (1/4), la pente de la courbe est positive en tout point, puisque l’effet de paiement élevé prédomine. Plus le risque est dispersé, plus la disposition à payer agrégée sera élevée. Ensuite, pour une réduction moyenne (1/6), l’effet de paiement élevé prédomine quand seulement une petite partie de la population est à risque. L’effet de mort imminente prend par contre le dessus lorsque le risque est plus dispersé et ainsi la pente devient négative. Finalement, pour les petites réductions de risque (1/10), le dead-anyway effect prédomine pour tous les niveaux de concentration de risque ce qui confère à la courbe une pente négative. La DAP agrégée est donc plus élevée lorsque le risque est concentré. Puisque la majorité des interventions gouvernementales impliquent de très petites réductions de probabilités de décès, nous pouvons supposer que l’effet de mort imminente devrait être l’effet ayant la plus grande influence.
3.4 Répartition de la richesse
Comme le stipule Drèze (1992), un projet gouvernemental devrait être approuvé seulement si celui-ci apporte une amélioration au sens de Pareto. Celle-ci est réalisée lorsque le projet augmente la qualité de vie d’au moins une personne sans détériorer celle d’une autre. Le graphique 3 illustre la situation pour deux individus (A et B).
Graphique 3
Amélioration au sens de Pareto

Considérons l’allocation x comme étant le point de départ. Il est évident qu’il y a moyen d’améliorer la situation de A et de B en changeant pour une allocation qui permet d’être sur le segment ab de la frontière.
Toutefois, la majorité des politiques gouvernementales ne permettent pas une amélioration directe au sens de Pareto. Il est peu probable qu’un gros projet puisse améliorer la situation de certains individus sans détériorer celle d’autres; il y a des gagnants et des perdants. Par exemple, la construction d’une autoroute permet de sauver du temps à de nombreux automobilistes, mais le bruit et la pollution diminuent la qualité de vie des résidents qui demeurent près de celle-ci. Cependant, la règle de Pareto permet un transfert des gagnants aux perdants. Si les gagnants pouvaient au moins compenser les perdants, alors il s’agirait d’une amélioration potentielle au sens de Pareto, également appelée amélioration au sens de Hicks et Kaldor.
L’utilisation de cette approche soulève toutefois des objections. D’abord, elle ne nécessite pas la compensation. Cela signifie qu’une amélioration au sens de Hicks et Kaldor peut détériorer la situation réelle d’individus, contrairement à une amélioration au sens de Pareto. De plus, cette approche peut créer des injustices selon la répartition de la richesse (Pratt et Zeckhauser, 1996). En général, la disposition à payer d’une population pauvre sera plus faible que la disposition à payer d’une population riche, et ce, pour une même amélioration. Ceci peut générer de l’injustice de deux façons. Premièrement, si le gouvernement doit choisir entre deux projets qui apportent le même niveau de bénéfices à deux populations différentes en termes d’utilité, la population la plus riche sera avantagée car elle aura une DAP plus élevée. Le gouvernement considérera le projet avec la DAP la plus élevée comme étant celui qui crée le plus de valeur à la société. Par contre, ce n’est pas tout à fait vrai en termes de bien-être. Deuxièmement, si un projet génère des bénéfices à une population riche et des coûts à une population pauvre, l’utilisation de la disposition à payer sous-évaluera les coûts par rapport aux bénéfices et le projet sera accepté. Dans la réalité, les décideurs publics accordent peu d’importance à ce problème de répartition de la richesse.
Cette revue nous a permis de bien comprendre toute la complexité et l’importance de bien mesurer la DAP d’une population avant de prendre une décision au sujet de projets gouvernementaux. Dans la prochaine section, nous allons examiner l’approche empirique utilisée par les chercheurs pour mesurer la DAP d’un échantillon de la population.
4. Approche empirique
À ce jour, plusieurs études empiriques ont été publiées concernant l’évaluation statistique d’une vie humaine. Cependant, nous ne voulons pas faire une revue de littérature complète sur le sujet. Cette section sera donc entièrement consacrée à l’analyse de la méthode hédonique d’estimation des salaires[10].
4.1 Méthodologie
Dans son oeuvre intitulé The Wealth of Nations (1776), Adam Smith stipule que le salaire des travailleurs varie en fonction des conditions de travail dans lesquelles ils évoluent. Cette affirmation révèle en fait un marché pour le risque. Dans ce marché, interviennent les travailleurs et les employeurs. Les travailleurs offrent leur main-d’oeuvre en échange d’un salaire et en même temps, les employeurs offrent un salaire pour l’exécution d’un travail. Le salaire d’équilibre, qui résulte de l’interaction entre les deux parties, indique le montant exigé pour accomplir le travail. En acceptant l’emploi, le travailleur accepte également ses caractéristiques, dont le risque qui lui est associé. La méthode hédonique d’estimation des salaires tente d’utiliser ce point d’équilibre pour évaluer la prime de risque versée aux travailleurs.
Graphique 4
Équilibre sur le marché du travail
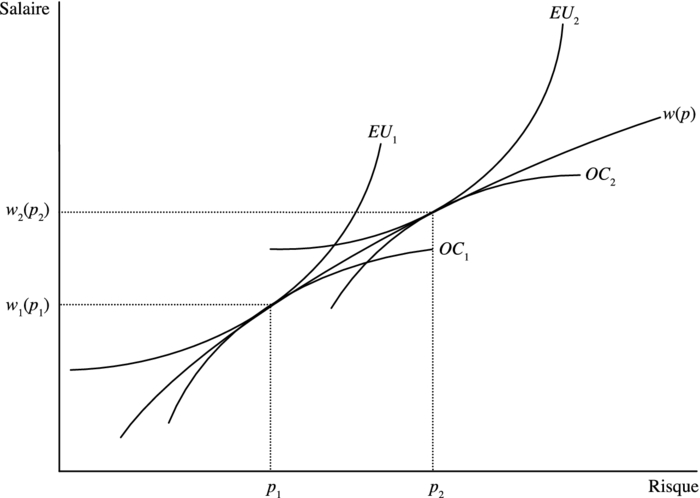
Le graphique 4 illustre la situation pour deux travailleurs et deux employeurs (Viscusi et Aldy, 2003). Les courbes d’indifférence des deux travailleurs sont représentées par EU1 et EU2. Elles correspondent à l’équation (7) de la section 2. Les frontières d’offre des entreprises sont, quant à elles, représentées par OC1 et OC2. Les deux points de tangence que nous retrouvons au graphique 4 correspondent à la DAP des deux travailleurs, soit à l’équation (9).
Thaler et Rosen (1975) furent les premiers à tester empiriquement cette méthodologie. Leur idée était d’estimer une courbe passant au travers des points d’équilibre, comme les w(p) du graphique 4.
4.2 Modèle économétrique et estimation de la DAP
Le modèle général pour estimer la disposition à payer prend la forme suivante :
Toutefois, selon Mincer (1974), le salaire d’un individu est donné par :
C’est pour cette raison que la plupart des chercheurs utilisent plutôt la forme semi-logarithmique de (27),
En dérivant (29) par rapport à pi, nous obtenons :
et
La disposition à payer de l’individu i est donc obtenue en multipliant le paramètre φ par le revenu de i. Selon l’unité de la variable dépendante wi, la DAP sera exprimée en terme horaire, hebdomadaire, mensuel ou annuel. Il sera important d’en tenir compte lors du calcul de la valeur de la vie.
La spécification économétrique s’obtient simplement en ajoutant un terme d’erreur aléatoire à l’équation (29), ce qui reflète les facteurs non observables influençant le salaire de i,
avec ui ~ N(0, σ2).
En estimant les paramètres de l’équation (33) à l’aide d’une régression linéaire, nous obtenons φ, soit la prime salariale moyenne pour une augmentation marginale de la probabilité de décès. À partir de l’équation (32), nous pouvons affirmer que la disposition à payer moyenne de l’échantillon est obtenue en multipliant φ par le revenu moyen. L’utilisation du revenu moyen dans le calcul de la DAP nécessite cependant l’utilisation d’un échantillon assez homogène et de grande taille, afin de ne pas créer de biais. Comme nous l’avons vu plus haut, un ajustement doit être fait à la DAP pour qu’elle soit exprimée en dollars annuels. Finalement, comme nous l’avons souligné à la section 2, pour calculer la valeur statistique d’une vie humaine, la DAP doit être divisée par la variation de la probabilité de décès. Cette variation dans la probabilité de décès est approximée, dans l’analyse de régression, à une unité de la variable pi[12]. Nous pouvons alors exprimer la valeur statistique d’une vie comme suit :
Maintenant que nous avons bien compris comment se mesure la valeur statistique d’une vie humaine, regardons comment celle-ci peut être influencée par les choix méthodologiques des chercheurs.
4.3 Choix méthodologiques
Dans chacune des études estimant la valeur statistique d’une vie humaine, les auteurs font face à des choix méthodologiques, que ce soit dans la construction de l’échantillon ou dans la technique d’analyse. Ces différents choix peuvent certainement influencer les résultats obtenus et probablement expliquer la grande variabilité des VSV publiées. Dans cette section, nous allons énumérer brièvement quelques-uns de ces choix et prédire leur impact direct ou indirect sur la valeur de la vie.
4.3.1 Choix des échantillons
Une des principales raisons qui explique les variations dans les valeurs de la vie provient des différences entre les caractéristiques des échantillons utilisés. Il est clair que toutes les décisions prises par le chercheur et influençant les caractéristiques de son échantillon auront des conséquences sur la valeur de la vie estimée. Voici quelques-unes des caractéristiques pouvant avoir un impact important.
Comme nous l’avons présenté aux équations (10) et (11), le salaire et le risque de décès initial peuvent avoir un impact sur la DAP des individus et ainsi sur la VSV. En se basant sur la théorie vue à la section 2, les études utilisant des échantillons d’individus plus fortunés devraient obtenir des estimations de la valeur de la vie plus élevées. Pour ce qui est des échantillons de personnes plus à risque, les résultats attendus sont ambigus.
En général, les femmes se retrouvent rarement dans des emplois risqués. Même à l’intérieur d’un même emploi, les tâches plus risquées sont habituellement confiées aux hommes (Leigh, 1987). Il n’est donc pas surprenant de constater que la majorité des décès, classifiés par industrie ou par occupation, concernent des hommes. Une probabilité de décès qui incorporerait les hommes et les femmes devrait donc bien refléter le risque des hommes, mais pas vraiment celui des femmes. C’est pour cette raison que certains auteurs excluent totalement les femmes de leur échantillon. D’autres les incluent mais incorporent une variable binaire (homme ou femme) dans leurs régressions. Il est donc possible que l’inclusion ou l’exclusion des femmes dans les échantillons puisse avoir un impact sur les coefficients estimés et donc des VSV[13].
Beaucoup d’auteurs ont étudié l’effet de la syndicalisation sur la disposition à payer des travailleurs. Plusieurs concluent que l’affiliation à un syndicat est associée à une DAP plus élevée. La raison principale qui explique cette prime salariale plus élevée chez les travailleurs syndiqués est l’accès à de l’information plus juste concernant leur sécurité. Sans cette information exacte, les travailleurs peuvent sous-estimer leur risque et ainsi demander une compensation salariale moins élevée. De plus, les syndicats peuvent être de bons mécanismes pour véhiculer aux dirigeants d’entreprises les préoccupations des travailleurs face à ces risques et pour négocier de meilleures compensations salariales. Cependant, certains auteurs (Marin et Psacharopoulos, 1982; Meng, 1989; Sandy et Elliott, 1996) obtiennent des DAP plus élevées chez les non-syndiqués et plus faibles chez les syndiqués[14]. Il n’y a donc pas de consensus sur la véritable influence de la syndicalisation sur la DAP. Pour mesurer cet impact, certains auteurs séparent simplement leur échantillon en deux (syndiqués et non-syndiqués). D’autres introduisent dans leurs régressions une variable binaire de syndicalisation en interaction avec la variable de risque. Toutefois, dans la majorité des études, les auteurs tiennent compte de cet effet en introduisant simplement une variable binaire sans interaction.
Les différences raciales peuvent également influencer les valeurs de la vie obtenues dans les études. Viscusi (2003) y consacre d’ailleurs tout un article. Il obtient des VSV considérablement moins élevées chez les travailleurs de race noire, comparativement à celles des blancs. Viscusi avance deux raisons pouvant expliquer ses résultats. D’abord, on observe que les travailleurs noirs se retrouvent, en général, dans des emplois plus risqués que les blancs. Il est donc possible que les préférences pour le risque diffèrent selon les races. Deuxièmement, les opportunités de travail peuvent être plus réduites chez les noirs. Plusieurs études illustrent encore la présence de discrimination raciale sur le marché du travail, ce qui se manifeste par des différences salariales entre blancs et noirs pour un même emploi. Il est à noter que cette discrimination raciale peut également réduire la mobilité des travailleurs noirs[15].
Certains auteurs portent une attention à l’occupation des travailleurs. On s’intéresse particulièrement à l’impact d’incorporer des cols bleus et des cols blancs dans un même échantillon. Puisque les cols bleus sont victimes de quatre à cinq fois plus d’accidents (Root et Sebastien, 1981), certains auteurs les excluent de leurs études. Pour cette même raison, d’autres vont plutôt exclure les cols blancs. Ces choix auront un impact sur la valeur de la vie, ainsi que sur la significativité des résultats.
4.3.2 Choix de la variable risque
Il est clair que la variable mesurant le risque de décès des travailleurs est l’une des plus importantes dans la méthode hédonique d’estimation des salaires. Le choix de cette variable devrait donc se faire avec minutie et devrait être bien justifié dans les études. La mesure de risque idéale serait celle perçue par les travailleurs. Cependant, la majorité des chercheurs utilisent des mesures de risques produites par des organismes, qui comptabilisent le nombre de décès par industrie ou par occupation[16].
Le Bureau of Labor Statistics (BLS), une section du U.S. Department of Labor, est la source la plus utilisée par les chercheurs américains. Des années soixante jusqu’au début des années quatre-vingt-dix, le BLS obtenait ses données à partir d’un sondage annuel distribué à des milliers d’entreprises de plusieurs industries. Ces données étaient ensuite compilées par code SIC (Standard Industrial Classification) à deux ou trois chiffres, donc de façon plutôt agrégée. Cette façon d’obtenir les données et de les compiler souleva un doute parmi les chercheurs quant à la possibilité d’erreurs de mesure (Moore et Viscusi, 1988a). Comme nous l’avons spécifié à la section 2, il est important d’avoir une mesure de risque désagrégée. Le fait d’attribuer la même probabilité de décès à chaque travailleur d’une même industrie peut créer des erreurs de mesure, car chacun de ces travailleurs n’a pas la même occupation et ne fait pas face au même risque.
Tableau 1
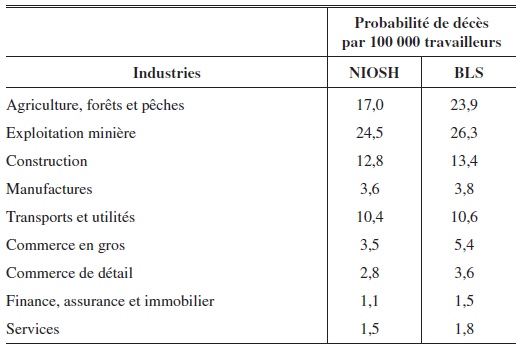
Probabilité de décès moyenne par industrie (BLS : 1972-1982, NIOSH : 1980-1985)

Le National Institute of Occupational Safety and Health (NIOSH), encore un organisme américain, permet aux chercheurs d’utiliser des données par occupation depuis 1980. Le NIOSH obtient ses informations des certificats de décès émis à la suite d’accidents sur les lieux de travail. Selon Moore et Viscusi (1988a), cette méthode est plus convenable car elle se base sur un recensement plutôt qu’un sondage. Les auteurs comparent également les statistiques des deux organismes (tableau 1). Ils constatent que les probabilités de décès élaborées à l’aide des données du NIOSH sont beaucoup plus élevées que celles construites à l’aide des données du BLS.
À partir de 1992, le BLS passe également par l’entremise d’un recensement pour recueillir ses données, soit le Census of Fatal Occupational Injuries (CFOI). En comparant maintenant les probabilités de décès sur la période allant de 1992 à 1995, nous voyons des changements non négligeables (tableau 2). D’abord, les différences entre les organismes sont moins importantes. Ensuite, on remarque que c’est au tour du BLS de rapporter des probabilités de décès supérieures.
Tableau 2
Probabilité de décès moyenne par industrie (1992-1995)
Quelques études utilisent également des données actuarielles[17]. Ces données proviennent d’une étude de la Society of Actuaries (SOA) qui fut publiée en 1967. Une première caractéristique très importante de cette étude est de mesurer le nombre de décès en excès à une espérance[18]. La mesure de risque n’est donc pas identique à celle du BLS et du NIOSH. Une deuxième caractéristique importante de cette étude concerne son intérêt particulier pour les emplois les plus risqués. Par conséquent, les probabilités de décès moyennes des échantillons des études qui utilisent cette source sont beaucoup plus élevées comparativement aux autres. Elles sont de l’ordre de 1 mort par 1 000 travailleurs, comparativement à 1 mort par 10 000 travailleurs dans les articles utilisant les données d’un autre organisme. Par conséquent, nous soulevons un doute quant à la pertinence d’utiliser cette source.
Pour ce qui est des études non américaines, les données sont habituellement de sources gouvernementales. Par exemple, au Canada, on utilise souvent les données recueillies par Statistique Canada et le ministère du Revenu. Au Québec, on a également accès aux données de la Commission de la santé et de la sécurité du travail (CSST).
Ces comparaisons entre les différents organismes nous permettent de saisir l’importance et l’impact face au choix de la source de la variable risque. Selon l’organisme choisi, les données retirées peuvent être très différentes et entraîneront vraisemblablement des valeurs de la vie également très différentes.
4.3.3 Choix des modèles
Dans les deux sous-sections précédentes, nous avons montré que les données et les variables utilisées par les chercheurs influencent certainement les VSV obtenues. Nous verrons maintenant que les décisions prises par les chercheurs, concernant la façon d’analyser les données, peuvent également être la source de grandes variations.
La majorité des études utilisent la méthode des moindres carrés ordinaires (MCO) pour estimer l’équation (33). Ces modèles traitent la variable de risque comme étant une variable exogène. Viscusi (1978a) insiste sur le fait qu’il faut tenir compte d’un effet revenu. Par conséquent, si nous supposons que la sécurité est un bien normal, les individus plus fortunés devraient en principe choisir des emplois moins risqués. Cette hypothèse signifie que l’utilisation des MCO entraînerait un biais du coefficient estimé associé au risque (φ). Pour traiter la variable risque comme endogène au modèle, il faut procéder par équations simultanées. Garen (1988) fut le premier chercheur à développer un tel modèle afin de l’appliquer à l’estimation de la valeur statistique d’une vie humaine. En général, on observe des valeurs de la vie supérieures dans les études qui utilisent cette méthode[19]. Il n’est pas évident qu’elles utilisent toutes des méthodes appropriées d’estimation (Knieser et al., 2007).
Les chercheurs doivent également choisir les variables indépendantes à insérer dans leurs modèles. Ces choix sont plutôt subjectifs, mais ils influenceront certainement les résultats. Certains auteurs n’utilisent pas seulement une forme linéaire de la variable risque, mais également la forme au carré. Ceci permet de tenir compte de la relation non linéaire entre le revenu et le risque. La variable risque peut également être utilisée en interaction avec certaines caractéristiques des travailleurs (race, âge, sexe, syndicalisation, région, etc.). Ces interactions permettent la segmentation du marché du travail (Day, 1999). Par exemple, il est possible que les individus d’une certaine région soient compensés différemment pour un même risque, en comparaison à ceux d’une autre région, ou que les individus d’un groupe d’âge soient plus aptes à prendre certains risques.
En principe, les travailleurs devraient non seulement exiger une compensation salariale pour le risque de décès, mais également pour le risque de blessure. Cependant, l’inclusion de la variable blessure dans les modèles soulève des interrogations. D’abord, l’omission de celle-ci peut biaiser positivement le coefficient relié au risque de décès. Toutefois, comme le soulignent Viscusi et Aldy (2003), le risque de décès est très corrélé avec le risque de blessure, alors l’utilisation des deux variables dans une même spécification peut affecter les résultats à cause de la colinéarité. Arabsheibani et Marin (2000) soutiennent plutôt que l’inclusion ou l’exclusion de la variable blessure n’a pas d’effet significatif sur le coefficient de la variable risque de décès.
Dans la littérature, beaucoup de chercheurs semblent oublier l’existence d’indemnisation pour les accidentés du travail. Arnould et Nichols (1983) soutiennent que les individus profitant d’une indemnisation exigent, en général, une compensation salariale moins élevée face à une hausse de leur risque de décès. Par ailleurs, les auteurs prétendent que les études qui omettent d’inclure cette variable dans leurs modèles doivent nécessairement obtenir des résultats biaisés. Nous constatons cependant que très peu d’études américaines incorporent cette variable. La principale raison découle probablement de la difficulté à obtenir les données[20]. Des évidences empiriques ont également démontré que la présence d’indemnisations implique d’importantes réductions dans les niveaux de salaires (Fortin et Lanoie, 2000).
5. Méta-analyse
Jusqu’à maintenant, nous avons présenté les concepts théoriques et les considérations pratiques reliés à l’estimation de la valeur statistique d’une vie humaine. Dans le reste de l’article, nous tenterons de discerner de quelle façon les différences entre les caractéristiques des études expliquent la grande variabilité dans les résultats obtenus. Nous utiliserons un outil statistique appelé méta-analyse.
Contrairement aux traditionnelles revues de littérature narrative, les méta-analyses permettent une analyse scientifique et exhaustive des résultats provenant de différentes études. Compte tenu de l’ampleur des données à analyser, Glass et al. (1981) soutiennent que l’utilisation d’une approche scientifique est essentielle pour effectuer une analyse complète et rigoureuse. De plus, les méta-analyses permettent de mieux orienter les recherches futures (Hunter et Schmidt, 2004). Depuis les vingt dernières années, il n’est pas très surprenant de constater une émergence d’études utilisant ce puissant outil statistique.
La méthodologie utilisée dans les méta-analyses repose principalement sur la construction et l’analyse d’un indicateur statistique commun à chaque étude, appelé l’effet taille (size effect). Pour obtenir des valeurs comparables, l’effet taille est habituellement exprimé en unités d’écart-type. Dans la plupart des méta-analyses, on compare soit des coefficients de corrélation des différences de moyennes ou des rapports de cotes (odds ratio). Dans celles qui nous intéressent, l’indicateur « standardisé » est plutôt la valeur statistique d’une vie humaine. La méta-régression est l’une des techniques les plus populaires dans le domaine des sciences économiques afin d’effectuer une méta-analyse. Elle permet d’analyser la relation entre les caractéristiques des différentes études. Dans ce type d’analyse, les VSV extraites de chaque article sont utilisées pour former la variable dépendante.
5.1 Approche méthodologique
Comme nous l’avons déjà mentionné, on constate de grandes variations dans les estimations de valeurs de la vie. Celles-ci compliquent le travail des décideurs publics. En effet, ces derniers doivent déterminer une valeur à insérer dans leurs calculs avantages–coûts. Il est donc primordial qu’ils comprennent la provenance de cette variabilité dans les résultats, afin de faire un choix plus éclairé.
Dans le but de bien saisir les sources de cette variabilité, Bellavance et al. (2009) ont effectué une méta-analyse d’études estimant la valeur statistique d’une vie humaine. Ils se sont cependant distingués des autres méta-analyses déjà réalisées en employant une méthodologie plus robuste et plus adéquate. L’approche utilisée repose principalement sur le modèle à effets mixtes (mixed effects model, Raudenbush, 1994).
Supposons d’abord que chaque étude utilise une méthodologie parfaitement identique et que les échantillons utilisés soient de même taille et construits aléatoirement à partir d’une même population. Les valeurs de la vie obtenues ne seront pas identiques, car les échantillons utilisés sont vraisemblablement différents. Cependant, nous pouvons affirmer que cette variation dans les résultats est entièrement due à la variance d’échantillonnage (Raudenbush, 1994). Elle peut également être appelée variance d’estimation, puisque les variations dans les échantillons auront un impact sur les estimations de la valeur de la vie. Si nous croyons que la variabilité dans les résultats obtenus est strictement due à cette variance d’estimation, alors nous devons utiliser un modèle à effets fixes. Toutefois, comme nous l’avons vu à la section 4.3, plusieurs différences méthodologiques sont observables dans les études. Celles-ci doivent probablement expliquer, en partie, les variations dans les estimations de la valeur de la vie. De plus, même si chaque auteur utilisait exactement la même méthodologie, plusieurs autres facteurs non observables et incontrôlables influenceraient les résultats. Le modèle à effets mixtes tient compte de cette hétérogénéité dans les études et prend comme hypothèse que la variance d’estimation n’est pas la seule source des variations observées. C’est pour cette raison que nous croyons que ce modèle est le plus approprié pour réaliser une méta- analyse.
Nous allons maintenant présenter le modèle à effets mixtes de façon plus détaillée, en décrivant chacune des procédures à suivre. En premier lieu, nous devons estimer la valeur statistique d’une vie VSVj dans chacune des J études recueillies[21]. Il s’agit d’une estimation de la « vraie » valeur de la vie θj. La relation entre les deux valeurs peut alors s’écrire comme suit :
Dans un modèle à effets fixes, l’effet aléatoire est simplement retranché de l’équation (36). Ce modèle suppose donc que les caractéristiques des études expliquent complètement les variations dans les vraies valeurs de la vie. De son côté, le modèle à effets mixtes tient compte de l’hétérogénéité non observable qui ne peut être considérée dans le modèle et qui peut expliquer les variations dans les vraies valeurs de la vie.
En substituant (36) dans (35), nous obtenons notre modèle de régression à estimer :
Ce modèle a comme particularité d’avoir deux éléments dans le terme d’erreur, l’effet aléatoire et l’erreur d’estimation. La variance de VSVj, conditionnelle aux caractéristiques Xjk, est trouvée par :
Comme le soutient Raudenbush (1994), il ne serait pas approprié d’effectuer une régression par moindres carrés ordinaires pour estimer l’équation (37), puisqu’une telle méthode prend comme hypothèse l’homoscédasticité. Cela signifie que les erreurs dans le modèle de régression ont la même variance. Or, le modèle qui nous intéresse repose plutôt sur une hypothèse d’hétéroscédasticité. La variance résiduelle du modèle (v*j) n’est pas constante, puisque vj diffère d’une étude à l’autre. Nous devons donc utiliser la méthode des moindres carrés pondérés, où les poids optimaux sont l’inverse des variances obtenues dans chacune des études :
Si ![]() est nulle, alors le modèle à effets fixes sera suffisant et les poids optimaux seront de 1/vj. Le calcul de vj se fait assez facilement et ne nécessite que certaines données présentes dans les études[22]. Comme nous le voyons à l’équation (39), le calcul des poids optimaux du modèle à effets mixtes nécessite un terme supplémentaire, la variance de l’effet aléatoire
est nulle, alors le modèle à effets fixes sera suffisant et les poids optimaux seront de 1/vj. Le calcul de vj se fait assez facilement et ne nécessite que certaines données présentes dans les études[22]. Comme nous le voyons à l’équation (39), le calcul des poids optimaux du modèle à effets mixtes nécessite un terme supplémentaire, la variance de l’effet aléatoire ![]() . Or, ce terme n’est pas donné dans les études et doit donc être estimé. Pour ce faire, nous devons effectuer l’estimation des paramètres de l’équation (37).
. Or, ce terme n’est pas donné dans les études et doit donc être estimé. Pour ce faire, nous devons effectuer l’estimation des paramètres de l’équation (37).
En résumé, l’estimation des paramètres de la régression (37) passe par l’estimation de ![]() et celle-ci dépend des paramètres inconnus de la régression. Il y a deux approches qui peuvent résoudre ce dilemme. D’abord, on peut procéder par la méthode des moments, qui se résume en trois étapes. La première consiste à utiliser la méthode des moindres carrés ordinaires ou la méthode des moindres carrés pondérés pour obtenir des estimations provisoires des paramètres de l’équation (37),
et celle-ci dépend des paramètres inconnus de la régression. Il y a deux approches qui peuvent résoudre ce dilemme. D’abord, on peut procéder par la méthode des moments, qui se résume en trois étapes. La première consiste à utiliser la méthode des moindres carrés ordinaires ou la méthode des moindres carrés pondérés pour obtenir des estimations provisoires des paramètres de l’équation (37), ![]() 0,…,
0,…,![]() K. Ensuite, il s’agit d’utiliser l’espérance de la somme des résidus afin d’effectuer une estimation de la variance de l’effet aléatoire,
K. Ensuite, il s’agit d’utiliser l’espérance de la somme des résidus afin d’effectuer une estimation de la variance de l’effet aléatoire, ![]() . Finalement, une nouvelle estimation des paramètres de la régression est effectuée à l’aide de la méthode des moindres carrés pondérés, où les poids sont donnés par,
. Finalement, une nouvelle estimation des paramètres de la régression est effectuée à l’aide de la méthode des moindres carrés pondérés, où les poids sont donnés par,
L’autre méthode consiste à utiliser le maximum de vraisemblance. En supposant la normalité de VSVi, cette méthode permet d’estimer les paramètres (β0,β1,…,βK) de l’équation (37), ainsi que la variance de l’effet aléatoire, ![]() . Cependant, cette méthode est surtout efficace en présence d’un échantillon de grande taille (Raudenbush, 1994). Puisque les méta-analyses se concentrent souvent sur l’analyse de la méthode hédonique d’estimation des salaires, les échantillons retenus ne seront probablement pas assez volumineux pour appliquer cette méthode. L’utilisation de la méthode des moments est donc plus adéquate dans plusieurs cas[23]. Bellavance et al. (2009) présentent des extensions de ce modèle de base afin d’estimer des modèles avec des spécifications économétriques plus complètes.
. Cependant, cette méthode est surtout efficace en présence d’un échantillon de grande taille (Raudenbush, 1994). Puisque les méta-analyses se concentrent souvent sur l’analyse de la méthode hédonique d’estimation des salaires, les échantillons retenus ne seront probablement pas assez volumineux pour appliquer cette méthode. L’utilisation de la méthode des moments est donc plus adéquate dans plusieurs cas[23]. Bellavance et al. (2009) présentent des extensions de ce modèle de base afin d’estimer des modèles avec des spécifications économétriques plus complètes.
5.2 Méta-analyses sur la valeur de la vie
Récemment, quelques méta-analyses ont été effectuées dans le but de synthétiser l’information des études estimant la valeur statistique d’une vie humaine. Ces méta-analyses diffèrent par la composition de leur échantillon, les modèles de régression utilisés, ainsi que par les variables explicatives des spécifications. Dans cette sous-section, nous ferons un bref survol de ces méta-analyses[24].
Liu et al. (1997) furent probablement parmi les premiers chercheurs à effectuer une méta-analyse d’études estimant la valeur statistique d’une vie humaine. Ils utilisent 17 VSV pour lesquelles les revenus moyens et les probabilités moyennes de décès étaient disponibles. Ces observations furent sélectionnées à partir du tableau 2 de Viscusi (1993), qui contient majoritairement des études d’origine américaine. Dans leur analyse, le même poids est attribué à chacune des études. Une simple régression par moindres carrés ordinaires, ne contenant que deux variables explicatives (revenu et risque), est utilisée par les auteurs. Le logarithme naturel des valeurs de la vie est utilisé comme variable dépendante. Ils obtiennent un coefficient positif mais non significatif pour la variable revenu et un coefficient négatif et significatif pour la variable de risque. L’élasticité-revenu obtenue de la régression a une valeur de 0,53, mais n’est pas significative.
Miller (2000) utilise un échantillon composé de 68 études provenant de 13 pays différents. À la différence de Liu et al. (1997), qui n’utilisent que des études préconisant la méthode risque-salaire, celui-ci inclut également les études mesurant la disposition à payer via le marché de la consommation et la méthode d’évaluation contingente. D’ailleurs, il incorpore dans ses régressions des variables binaires pour tenir compte de la méthode appliquée dans les études. Une autre particularité de l’étude de Miller concerne l’utilisation du produit intérieur brut (PIB) et du produit national brut (PNB) per capita comme variables explicatives, au lieu des revenus individuels. Encore une fois, le même poids est attribué à chacune des études. Les coefficients associés aux revenus (PIB ou PNB) sont positifs et significatifs dans toutes les spécifications. L’élasticité-revenu reste relativement stable d’un modèle à l’autre et oscille entre 0,85 et 1,00. Il est surprenant de constater qu’aucune variable de risque n’est présente dans les différentes spécifications.
Bowland et Beghin (2001) effectuent une méta-analyse à l’aide de 33 études utilisées dans les travaux de Viscusi (1993) et de Desvousges et al. (1995). Ces études proviennent toutes de pays industrialisés et utilisent soit la méthode risque-salaire, soit la méthode d’évaluation contingente. Le but des auteurs étant d’utiliser leurs résultats pour estimer une valeur de la vie pour le Chili, ils lient chaque étude aux caractéristiques démographiques des pays où celle-ci a été réalisée. Les auteurs, soucieux de la non-normalité des résidus, emploient une méthode de régressions robustes selon Huber (1964, 1981). Cette méthode accorde un poids moins élevé aux données moins crédibles. Bowland et Beghin obtiennent une élasticité-revenu significative pour plusieurs spécifications variant entre 1,7 à 2,3. En ce qui concerne la probabilité de décès, les paramètres estimés sont principalement positifs et significatifs. Par la méthode des moindres carrés ordinaires, les résultats obtenus sont très similaires. Il est à noter que les auteurs n’incorporent aucune caractéristique méthodologique des études parmi leurs variables explicatives. Comme nous l’avons vu précédemment, ces caractéristiques peuvent expliquer en partie les variabilités dans les valeurs de la vie estimées.
Mrozek et Taylor (2002) construisent un échantillon de 33 études (américaines et autres) utilisant la méthode hédonique d’estimation des salaires. Les auteurs ont décidé d’inclure toutes les spécifications disponibles dans chacune des études. Au total, 203 observations ont été recueillies. Comme nous venons de le voir à la section 5.1, cette façon de procéder entraîne possiblement un biais, puisque les observations perdent leur indépendance. Pour ne pas accorder plus de poids aux études qui utilisent un grand nombre de spécifications différentes, un poids de 1/N est attribué à chaque observation, où N correspond au nombre de valeurs de la vie provenant de l’étude en question. L’estimation est donc obtenue par moindres carrés pondérés plutôt que par MCO. Tous les modèles présentés par les auteurs indiquent une relation positive et significative entre le risque moyen et la valeur statistique d’une vie humaine. Mrozek et Taylor obtiennent, à l’aide de leur modèle complet, une élasticité-revenu significative de 0,49. Une forme réduite du modèle, qui exclut trois des variables explicatives, génère une élasticité-revenu significative de 0,46.
Viscusi et Aldy (2003) effectuent une méta-analyse à l’aide d’un échantillon composé d’environ 50 études provenant de 10 pays différents. Comme pour l’échantillon de Mrozek et Taylor (2002), seules les études qui emploient la méthode risque-salaire ont été retenues. L’estimation est effectuée par régressions robustes ainsi que par moindres carrés ordinaires. Les résultats obtenus restent assez stables d’une spécification à l’autre. Les paramètres associés à la variable de risque moyen sont tous négatifs et significatifs. L’élasticité-revenu est, quant à elle, positive et significative pour toutes les spécifications. Celle-ci varie entre 0,49 et 0,60 pour les spécifications utilisant les MCO et oscille entre 0,46 et 0,48 pour les résultats obtenus par régressions robustes.
de Blaeij et al. (2003) réalisent une méta-analyse à l’aide d’études mesurant la valeur de la vie dans un contexte de sécurité routière. Ils construisent un échantillon composé de 95 valeurs de la vie provenant de 30 études différentes. Comme pour Mrozek et Taylor (2002), nous retrouvons plusieurs VSV provenant d’une même étude. Le but de l’article est de tenter d’expliquer d’où proviennent les variations observées dans les VSV estimées par ce type d’étude. En particulier, les auteurs désirent comparer l’effet de l'utilisation de l’approche des préférences révélées, plutôt que celle de l’évaluation contingente. La méthodologie employée par ceux-ci comporte deux étapes. D’abord ils effectuent une analyse bivariée à l’aide de Q-Tests[25]. Les auteurs forment plusieurs groupes présentant des caractéristiques communes pour ensuite les comparer. Les résultats confirment la présence d’importantes variations entre les groupes ainsi qu’à l’intérieur même de ces groupes. Les auteurs procèdent, par la suite, à une analyse multivariée par méta-régression afin d’augmenter la robustesse à leurs résultats. Dans certaines spécifications, un poids est attribué à la variable dépendante (VSV), selon la fiabilité de l’estimation. À défaut d’obtenir les variances des valeurs de la vie pour chacune des études, ce qui serait plus approprié, ils utilisent plutôt la taille des échantillons comme poids[26]. Ils obtiennent une élasticité-revenu significative de 1,67, où les revenus sont exprimés en PIB per capita. Selon les auteurs, ce résultat élevé est dû à la présence de multicolinéarité avec la variable « time trend », qui est une mesure du temps. Sans cet effet, l’élasticité-revenu est plutôt de 0,50. En ce qui concerne la variable de risque, les seuls résultats significatifs se retrouvent dans les modèles n’incluant que les études utilisant l’approche de l’évaluation contingente. Les paramètres estimés dans ces modèles sont positifs. Finalement, les résultats de la méta-régression permettent aux auteurs de conclure que l’approche des préférences révélées entraîne des valeurs de la vie significativement moins élevées que l’approche de l’évaluation contingente.
Bellavance, Dionne et Lebeau (2009) ont analysé 37 études utilisant l’approche hédonique. Leur méta-analyse est unique, car elle est la première à utiliser le modèle de régression à effets mixtes (Raudenbush, 1994) pour analyser des études sur la valeur statistique d’une vie. Cette méthode permet de contrôler les variations des variances dans les échantillons des différentes études. Ces variations peuvent être influencées par des facteurs contrôlables et non contrôlables. Le modèle de Raudenbush (1994) permet de tenir compte de ces deux sources d’hétérogénéité. Bellavance et al. (2009) concluent que les principales variations entre les valeurs des différentes études sont dues à des méthodologies différentes utilisées par les chercheurs. Ils obtiennent une valeur moyenne de la VSV de 5,8 millions de dollars (US de 2000), ce qui correspond aux conclusions de Dionne et Lanoie (2004) et de Knieser et al. (2007). Ils obtiennent un effet risque négatif et une élasticité-revenu variant entre 0,84 et 1,08.
Les auteurs vérifient également que plusieurs effets méthodologiques influencent leur estimation de la valeur d’une vie. Les chercheurs qui utilisent la variable de risque comme étant endogène obtiennent des valeurs beaucoup plus élevées. Il n’est pas évident que l’analyse de l’endogénéité soit appropriée dans tous les cas. Les études contenant des variables pour tenir compte des compensations pour les accidents du travail ont des valeurs plus faibles. Les populations à l’étude sont également importantes. Les populations les plus riches ont des valeurs de la vie plus élevées et les populations contenant des gens altruistes génèrent une relation négative entre la valeur d’une vie humaine et la probabilité d’accident. Finalement, les résultats sont affectés par le pays de l’étude, l’année de publication, la race des travailleurs et la source de la variable risque.
Tableau 3
Résumé des résultats des méta-analyses
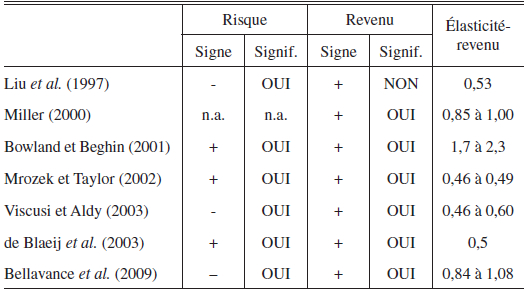
Au tableau 3, nous présentons un résumé des résultats de différentes méta-analyses effectuées[27]. Nous pouvons affirmer qu’il y a définitivement une relation positive entre les revenus et les estimations de la valeur de la vie. De plus, nous constatons que l’élasticité-revenu obtenue par ces différentes méta-analyses est toujours de valeur égale ou inférieure à 1, à l’exception de l’étude de Bowland et Beghin (2001). Cependant, nous ne pouvons rien conclure à propos de la relation entre le risque moyen et la valeur de la vie. Dans certains cas, les auteurs obtiennent des coefficients positifs et significatifs, dans d’autres plutôt négatifs et significatifs. Cette relation semble donc ambiguë, comme indiqué dans la section théorique.
Conclusion
Depuis plus de 40 ans, les économistes tentent de mesurer la valeur statistique d’une vie humaine, de plusieurs façons différentes. Dans cet article, nous avons présenté la disposition à payer comme étant la méthode la plus adéquate pour mesurer les préférences individuelles en matière de risque. Toutefois, nous avons pu constater qu’elle a également des faiblesses. D’abord, nous avons réalisé que les propriétés théoriques de la DAP sont plutôt fragiles et ne semblent pas concorder empiriquement avec celles de la VSV. Ensuite, lorsqu’on effectue un survol des nombreuses études qui ont tenté d’estimer la VSV à l’aide de la DAP, on constate des écarts considérables, ce qui s’avère problématique pour les gouvernements. L’utilisation d’une VSV qui ne reflète pas adéquatement la volonté à payer des citoyens entraînera de mauvaises décisions de la part des décideurs publiques.
Les résultats des méta-analyses nous permettent de conclure que la variabilité des résultats provient, en grande partie, de différences méthodologiques. Nous avons vu que les caractéristiques des échantillons utilisés par les chercheurs ont un impact considérable sur les VSV obtenues. En effet, les échantillons composés d’individus plus fortunés, de race blanche et moins (plus) exposés au risque de décès entraînent des VSV plus élevées. Ces résultats informent les décideurs publics quant à l’importance de la représentativité des échantillons utilisés. Il est toutefois essentiel que l’aspect d’équité des projets gouvernementaux soit considéré dans la prise de décisions (Drèze, 1992).
Plusieurs autres facteurs méthodologiques ont également un impact important sur les VSV estimées. Entre autres, les chercheurs qui tiennent compte de la nature endogène de la variable de risque obtiennent des VSV considérablement plus élevées. De plus, la forme des spécifications utilisées influence aussi les résultats. Lorsqu’une variable mesurant le niveau de compensation salariale allouée aux travailleurs est incluse dans les modèles, nous vérifions des VSV réduites. Finalement, nous constatons que le pays d’origine des études, l’année de leur publication, ainsi que la source de la variable de risque utilisée, influencent de façon significative la VSV.
Quelle valeur utiliser pour évaluer des projets? Trois études semblent indiquer que lorsque les problèmes méthodologiques sont bien pris en compte, la valeur devrait se situer entre cinq et six millions de dollars de 2000 (Bellavance et al., 2009; Dionne et Lanoie, 2004; Knieser et al., 2007). L'étude de Bellavance et al. (2009) donne une valeur moyenne de 5,86 millions de dollars US 2000, avec un intervalle de confiance de 4,7 millions à 7,1 millions.
Parties annexes
Remerciements
Nous remercions Pierre Lefebvre de nous avoir encouragés à maintes reprises à écrire cet article. Cette recherche a été financée, en partie, par le ministère des Transports du Québec, le Conseil de recherche en sciences humaines du Canada et la Chaire de recherche du Canada en gestion des risques. Nous remercions François Bellavance, Paul Lanoie et Pierre-Carl Michaud pour leur collaboration à différentes études reliées à la valeur de la vie humaine, ainsi que Claire Boisvert, Lucie-Nathalie Cournoyer et un arbitre anonyme pour leurs commentaires.
Notes
-
[1]
Les investissements du gouvernement dans les mesures de santé et de sécurité tendent à réduire un peu les risques auxquels font face d’importants segments de la population. C’est cette réduction des risques qu’on peut évaluer par l’analyse avantages-coûts
Secrétariat du Conseil du Trésor, 1998 -
[2]
Dans Dionne et Lebeau (2010), une attention est accordée aux modèles utilisant l’approche QALY (quality-adjusted life year). Ces modèles prennent en considération la qualité de vie des individus qui sont sauvés par l’intervention gouvernementale. L’utilisation de cette méthode se fait principalement dans les domaines de la médecine et de la santé publique.
-
[3]
Plusieurs études ont utilisé l’approche des préférences révélées dans le domaine des transports (Blomquist, 1979; Blomquist et Miller, 1992; Dreyfus et Viscusi, 1995; Jenkins et al., 2001). Pour des revues, voir de Blaeij et al. (2003) et Dionne et Lanoie (2003).
-
[4]
Un des objectifs conjoints des gouvernements et des syndicats est justement de fournir cette information aux travailleurs.
-
[5]
Nous ne ferons pas une analyse exhaustive des études utilisant le marché des biens de consommation. Nous suggérons au lecteur intéressé de consulter Blomquist (1979), Dardis (1980), ainsi que Dreyfus et Viscusi (1995).
-
[6]
Cette hypothèse n’est pas nécessaire à la dérivation du modèle, mais simplifie sa présentation.
-
[7]
Par égoïste, nous entendons une personne qui préférera toujours la consommation à l’héritage.
-
[8]
Pour une analyse des activités d’autoprotection avec des fonctions d’utilité dépendant des états de la nature, voir Dionne (1982). Pour une analyse de l’aversion au risque lorsque les fonctions d’utilité dépendent des états de la nature, voir Karni (1985).
-
[9]
Ceci correspond à la quasi-totalité des fonctions d’utilité utilisée dans la littérature. Pour une analyse plus détaillée de ce concept, voir Caballé et Pomansky (1996).
-
[10]
Pour une revue de littérature au sujet d’autres méthodes, le lecteur peut consulter Michaud (2001) et Dionne et Lanoie (2004).
-
[11]
Il ne s’agit pas de la variation en pourcentage de ln(wi). Pour une présentation des modèles log-level, voir Wooldridge (2000).
-
[12]
Dans la majorité des études, la variable mesurant la probabilité de décès est exprimée en morts par 10 000 travailleurs. Dans ces cas, l’unité de la variable pi est 1/10 000.
-
[13]
Leigh (1987) n’obtient qu’une petite différence dans la valeur de la vie lorsqu’il exclut les femmes de son échantillon.
-
[14]
Pour une revue plus complète des études analysant l’impact de la syndicalisation, voir Sandy et al. (2001), ainsi que Viscusi et Aldy (2003).
-
[15]
Selon Dionne et Lanoie (2004), cette mobilité est essentielle pour appliquer une analyse risque-salaire.
-
[16]
Habituellement les chercheurs vont utiliser une moyenne des probabilités de décès sur quelques années. Cela évite les distorsions provoquées par une catastrophe pouvant se produire une certaine année dans une certaine industrie.
-
[17]
Voir Thaler et Rosen (1975), Brown (1980), Arnould et Nichols (1983), ainsi que Gegax, Gerking et Schulze (1991).
-
[18]
Cette espérance de décès est calculée en fonction de la structure d’âge à l’intérieur de chaque occupation, ainsi qu’à l’aide de tables de survie.
-
[19]
Voir Garen (1988), Siebert et Wei (1994), Sandy et Elliott (1996), Shanmugam (2001), ainsi que Gunderson et Hyatt (2001).
-
[20]
Aux États-Unis, les programmes d’indemnisation sont régis par chacun des États. Par contre, au Canada, l’information est disponible directement du gouvernement fédéral (ministère du Revenu) et du gouvernement du Québec.
-
[21]
Voir équation (34).
-
[22]
Parmi celles-ci on retrouve l’erreur type associée au coefficient φ̂.
-
[23]
Pour obtenir la procédure exacte utilisée, sous forme matricielle, voir Cooper et Hedges, (1994) : 318.
-
[24]
Pour quelques revues de littérature différentes sur le sujet, le lecteur peut consulter les travaux de Fisher et al. (1989), Miller (1990) et Viscusi (1993).
-
[25]
Les Q-tests servent à détecter la présence d’hétérogénéité dans un sous-groupe.
-
[26]
Puisque la taille de l’échantillon est habituellement reliée de façon inverse à la variance, celle-ci est souvent utilisée par les chercheurs pour remplacer ou estimer la variance.
-
[27]
Les sept méta-analyses que nous venons d’analyser ont été choisies selon leur popularité dans la littérature. Ce sont également les seules, à notre connaissance, à avoir été publiées dans une revue scientifique. Pour d’autres méta-analyses, le lecteur peut consulter Desvousges et al. (1995), Day (1999), Takeuchi (2000), Michaud (2001), ainsi que Dionne et Michaud (2002).
Bibliographie
- Andersson, H. et N. Treich (2008), « The Value of a Statistical Life », dans The Handbook of Transport Economics, (à paraître).
- Arabsheibani, G. Reza et A. Marin (2000), « Stability of Estimates of the Compensation for Danger », Journal of Risk and Uncertainty, 10(3) : 247–269.
- Arnould, Richard J. et L.M. Nichols (1983), « Wage-Risk Premiums and Worker’s Compensation: A Refinement of Estimates of Compensating Wage Differentials », Journal of Political Economy, 91 : 332–340.
- Arthur, W.B. (1981), « The Economics of Risks to Life », American Economic Review, 71(1) : 54-64.
- Bellavance, F., G. Dionne et M. Lebeau (2009), « The Value of a Statistical Life: A Meta-Analysis with a Mixed Effects Regression Model », Journal of Health Economics, 28(2) : 444-464.
- Blomquist, G. (1979), « Value of Life Saving: Implications of Consumption Activity », Journal of Political Economy, 87(3) : 540–558.
- Blomquist, G. et T.R. Miller (1992), Valu es of Life and Time Implied by Motorist Use of Protection Equipment, Urban Institute, Washington, DC.
- Bommier, A. et B. Villeneuve (2011), « Risk Aversion and the Value of Risk to Life », Journal of Risk and Insurance, (à paraître).
- Bowland, B.J. et J.C. Beghin (2001), « Robust Estimates of Value of a Statistical Life for Developing Economies », Journal of Policy Modeling, 23 : 385–396.
- Breyer, F. et S. Felder (2005), « Mortality Risk and the Value of a Statistical Life: The Dead-Anyway Effect Revis(it)ed », The Geneva Risk and Insurance Review, 30(1) : 41-56.
- Caballé, J. et A. Pomansky (1996), « Mixed Risk Aversion », Journal of Economic Theory, 71 : 485-513.
- Cooper, H et L.V. Hedges (1994), The Handbook of Research Synthesis, Russel Sage Fundation, New York.
- Dachraoui, K., G. Dionne, L. Eeckhoudt et P. Godfroid (2004), « Comparative Mixed Risk Aversion: Definition and Application to Self-Protection and Willingness to Pay », Journal of Risk and Uncertainty, 29(3) : 261-276.
- Dardis, R. (1980), « The Value of Life: New Evidence from the Marketplace », American Economic Review, 70(5) : 1077–1082.
- Day, B. (1999), « A Meta-analysis of Wage-risk Estimates of the Value of Statistical Life », Centre for Social and Economic Research on the Global Environment, University College London, mimeo.
- de Blaeij, A., R.J.G.M. Florax, P. Rietveld et E. Verhoef (2003), « The Value of Statistical Life in Road Safety: A Meta-Analysis », Accident Analysis and Prevention, 35 : 973-986.
- Department of Health and Human Services (2009), « The Cost of Fatal Injuries to Civilian Workers in the United States: 1992-2001 », National Institute for Occupational Safety and Health.
- Desvousges, W.H., F.R.Johnson, H.S. Banzhaf, R.R. Russell, E.E. Fries, K.J. Dietz et S.C. Helms (1995), « Assessing the Environmental Externality Costs for Electricity Generation », Research Triangle Park, NC: Triangle Economic Research.
- Dillingham, A.E. et R.S. Smith (1984), « Union Effects on the Valuation of Fatal Risk », inProceedings of the Industrial Relations Research Association 36th Annual Meeting, San Francisco, décembre, p. 270–277.
- Dionne, G. (1982), « Moral Hazard and State-Dependent Utility Function », Journal of Risk and Insurance, 49 : 405-422.
- Dionne, G. et L. Eeckhoudt (1985), « Self-Insurance, Self-Protection and Increased Risk Aversion », Economics Letters : 39-43.
- Dionne, G., J. Gagné, P. Lanoie, S. Messier et P.-C. Michaud (2002), « Évaluation des bénéfices liés à une amélioration de la sécurité routière : revue de la littérature et proposition pour le Québec », Chaire de recherche du Canada en gestion des risques, HEC Montréal et CRT, Université de Montréal.
- Dionne, G. et P. Lanoie (2004), « Public Choice about the Value of a Statistical Life for Cost-Benefit Analyses: The Case of Road Safety », Journal of Transport Economics and Policy, 38(2) : 247-274.
- Dionne, G. et M. Lebeau (2010), « Le calcul de la valeur statistique d’une vie humaine », cahier de recherche, Chaire de recherche du Canada en gestion des risques, http://papers.ssrn.com/sol3/papers.cfm?abstract_id=1707440.
- Dolan, P. (1997), « Modeling Valuations for EuroQol Health States », Medical Care, 35 : 1095–1108.
- Dreyfus, M.K. et W.K. Viscusi (1995), « Rates of Time Preference and Consumer Valuations of Automobile Safety and Fuel Efficiency », Journal of Law and Economics, 38(1) : 79-105.
- Drèze, J. (1962), « L’utilité sociale d’une vie humaine », Revue française de recherche opérationnelle, 1 : 93-118.
- Drèze, J. (1992), « From the “Value of Life” to the Economics and Ethics of Population: The Path is Purely Methodological », Recherches Économiques de Louvain, 58(2) : 147-166.
- Dublin L.I. et A.J. Lotka (1947), The Money Value of a Man, New York : The Ronald Press Company.
- Eeckhoudt, L. et C. Gollier (2005), « The Impact of Prudence on Optimal Prevention », Economic Theory, 26 : 989-994.
- Eeckhoudt, L. et J.K. Hammitt (2001), « Risk Aversion and the Value of Mortality Risk », Center for Risk Analysis, Harvard University working paper.
- Eeckhoudt, L. et J.K. Hammitt (2004), « Does Risk Aversion increase the Value of Mortality Risk? », Journal of Environmental Economics and Management, 47 : 13-29.
- Feeny, D.H., W.J. Furlong, M. Boyle et G.W. Torrance (1995), « Multi-Attribute Health Status Classification Systems: Health Utilities Index », Pharmacoeconomics, 7(6) : 490-502.
- Feeny, D.H., G.W. Torrance et W.J. Furlong (1996), « Health Utilities Index », in B. Spilker, (éd.), Quality of Life and Pharmacoeconomics in Clinical Trials, 2e édition, Philadelphia : Lippincott-Raven Press, p. 239-252.
- Fein, R. (1958), Economics of Mental Illness, New York : Basic Books.
- Fortin B. et P. Lanoie (2000), « Effects of Workers’ Compensation: A Survey », inDionne, G. (éd.) Handbook of Insurance, Kluwer Academic Publishers, Boston, p. 421-457.
- Fox-Rushby, J. (2002), « Disability Adjusted Life Years (DALYs) for Decision-Making? An Overview of the Literature », Office of Health Economics, London, 172 p.
- Garen, J. (1988), « Compensating Wage Differentials and the Endogeneity of Job Riskiness », Review of Economics and Statistics, 9-16.
- Glass, G.V., B. Mcgraw et M.L. Smith (1981), Meta-analysis in Social Research, Sage Publications : Beverly Hills, CA.
- Graham, J.D., K.M. Thompson, S.J. Goldie, M. Segui-Gomez et M.C. Weinstein (1997), « The Cost-Effectiveness of Air Bags by Seating Position », Journal of the American Medical Association, 278 : 1418-1425.
- Hammitt, J.K. (2002), « QALYs Versus WTP », Risk Analysis, 22(5) : 985-1001.
- Huber, P.J. (1964), « Robust Estimation of a Location Parameter », Annals of Mathematical Statistics, 35 : 73-101.
- Huber, P.J. (1981), Robust Statistics, New York : John Wiley & Sons, Inc.
- Hunter, J.E. et F.L. Schmidt (2004), Methods of Meta-Analysis: Correcting Error and Bias in Research Findings, 2nd Edition, Newbury Park : Sage Publications.
- Jenkins, R.R., N. Owens et L.B. Wiggins (2001), « Valuing Reduced Risk to Children: The Case of Bicycle Safety Helmets », Contemporary Economic Policy, 19 : 397-408.
- Jones-Lee, M.-W. (1976), The Value of Life: An Economic Analysis, Chicago : University Press.
- Karni, E. (1985), Decision Making under Uncertainty: The Case of State-Dependent Preferences, Harvard University Press, Cambridge, MA.
- Kind P. (1996), « The EuroQol Instrument: An Index of Health-Related Quality of Life », in Spilker, B., (éd.), Quality of Life and Pharmacoeconomics in Clinical Trials, 2e édition, Philadelphia (PA): Lippincott-Raven Press, 191-201.
- Knieser, T.J., W.K. Viscusi, C. Woock, J.P. Ziliak (2007), « Pinning Down the Value of Statistical Life », Working paper IZA no 3107, 32 p.
- Lanoie, P., C. Pedro et R. Latour (1995), « The Value of a Statistical Life: A Comparison of Two Approaches », Journal of Risk and Uncertainty, 10 : 235-257.
- Le Pen, C. (1993), « Capital humain et la santé (valeur et qualité de la vie humaine) », Paris, Dauphine, miméo.
- Leigh , P.J. (1987), « Gender, Firm Size, Industry and Estimates of the Value-of-Life », Journal of Health Economics, 6(3) : 255-273.
- Li, J. et G. Dionne (2010), « The Impact of Prudence on Optimal Prevention Revisited », Cahier de recherche 10-04, Chaire de recherche du Canada en gestion des risques, HEC Montréal, Economics Letters, à paraître.
- Liu, J.T., J.K. Hammitt et J.L. Liu (1997), « Estimated Hedonic Wage Function and Value of Life in a Developing Country », Economics Letters, 57(3) : 353-358.
- Marin, A. et G. Psacharopoulos (1982), « The Reward for Risk in the Labor Market: Evidence from the United Kingdom and a Reconciliation with other Studies », Journal of Political Economy, 90 : 827–853.
- Mcdowell, I. et C. Newell (1996), Measuring Health: A Guide to Rating Scales and Questionnaires, 2e édition, Oxford University Press, p. 446-456.
- Meng, R. (1989), « Compensating Differences in the Canadian Labor Market », Canadian Journal of Economics, 22 : 413–424.
- Michaud, P.-C. (2001), « Évaluation des bénéfices et choix des projets impliquant la sauvegarde de vies humaines », Mémoire présenté en vue de l’obtention du grade de maîtrise, HEC Montréal.
- Miller, T.R. (2000), « Variations between Countries in Values of Statistical Life », Journal of Transport Economics and Policy, 34(2) : 169–188.
- Mincer, J. (1974), Schooling, Experience, and Earnings, Columbia University Press, New York.
- Mishan, E.J. (1971), « Evaluation of Life and Limb: A Theoretical Approach », Journal of Political Economy, 79 : 687-705.
- Moore, M. et W.K. Viscusi (1988a), « Doubling the Estimated Value of Life: Results Using New Occupational Fatality Data », Journal of Policy Analysis and Management, 7 : 476–490.
- Mrozek, J.R. et L.O. Taylor (2002), « What Determines the Value of Life? A Meta-Analysis », Journal of Policy Analysis and Management, 21(2) : 253–270.
- Murray, C.J.L. (1994), « Quantifying the Burden of Disease: The Technical Basis for Disability-adjusted Life Years », Bulletin of the World Health Organisation, 72(3) : 429-445.
- Mushkin, S.J. (1962), « Health as an Investment », Journal of Political Economy, 70(2) : 129-157.
- Pliskin, J.S., D.S. Shepard et M.C. Weinstein (1980), « Utility Functions for Life Years and Health Status », Operations Research, 28(1) : 206–224.
- Pratt, J.W. et R.J. Zeckhauser (1996), « Willingness to Pay and the Distribution of Risk and Wealth », Journal of Political Economy, 104(4) : 747–763.
- Raudenbush, S.W. (1994), « Random Effects Models », inCooper, H. et L.V. Hedges (éds.), The Handbook of Research Synthesis, Russel Sage Fundation, New York.
- Rice, D.P. (1967), « Estimating the Cost of Illness », American Journal of Public Health, 57 : 424-440.
- Rice, D.P. et E.J. Mackenzie, Associates (1989), Cost of Injury in the United States : A Report to Congress, San Francisco, CA, 131 p.
- Root, N. et D. Sebastian (1981), « BLS Develops Measure of Job Risk by Occupation », Monthly Labor Review, 106 : 26-30.
- Sandy, R. et R.F. Elliott (1996), « Unions and Risk: Their Impact on the Compensation for Fatal Risk », Economica, 63(250) : 291-309.
- Secrétariat du conseil du trésor (1998), Guide de l’analyse avantages-coûts, 75 p.
- Schelling, T.C. (1968), « The Life you Save May be your Own », in Chase, S. (éd.), Problems in Public Expenditure Analysis, Washington, Brookings Institution, p. 127-162.
- Smith, A. (1776), The Wealth of Nations, Chicago : University of Chicago Press.
- Smith, V.K. et W.H. Desvousges (1987), « An Empirical Analysis of the Economic Value of Risk Changes », Journal of Political Economy, 95 : 89-114.
- Takeuchi, K. (2000), « A Meta-Analysis of the Value of Statistical Life », Discussion Paper, Institute of Social Sciences, Meiji University.
- Thaler, R. et S. Rosen (1975), « The Value of Saving A Life: Evidence From The Labor Market », inTerleckyj N., Household Production and Consumption, NBER Press, Columbia University.
- Thaler, R. (1974), « The Value of Saving a Life: A Market Estimate », thèse de doctorat, University of Rochester, Dept. of Economics.
- Transport Canada (1994), Guide de l’analyse coûts-avantages à Transport Canada, Rapport de Transport Canada, TP11875F.
- Treich, N. (2005), « L’analyse coût-bénéfice de la prévention des risques », LERNA, Université de Toulouse.
- Viscusi, W.K. (1978a), « Wealth Effects and Earnings Premiums for Job Hazards », Review of Economics and Statistics, 60(3) : 408–416.
- Viscusi, W.K. (1993), « The Value of Risks to Life and Health », Journal of Economic Literature, 31 : 1912-1946.
- Viscusi, W.K. (2000), « Risk Equity », Discussion Paper, n° 294, Harvard Law School, Cambridge.
- Viscusi, W.K. (2003), « Racial Differences in Labor Market Values of a Statistical Life », Journal of Risk and Uncertainty, 27(3) : 239-256.
- Viscusi, W.K. (2005), « The Value of Life », Discussion Paper, n° 517, Harvard Law School, Cambridge.
- Viscusi, W.K. et J.E. Aldy (2003), « The Value of a Statistical Life: A Critical Review of Market Estimates Throughout the World », Journal of Risk and Uncertainty, 27 : 5-76.
- Viscusi, W.K. et J. Hersch (1998), « Smoking and Other Risky Behaviors », Journal of Drug Issues, 28(3) : 645-661.
- Wagstaff, A. (1991), « QALYs and the Equity-Efficiency Trade-Off », Journal of Health Economics, 10 : 21-41.
- Weinstein, M.C., D.S. Shepard et J.S. Pliskin (1980), « The Economic Value of Changing Mortality Probabilities: A Decision-Theoretic Approach », The QuarterlyJournal of Economics, 94 : 373-396.
- Wooldridge, J.M. (2000), Introductory Econometrics: A Modern Approach, South-Western College Publishing.
- Berger, M.C. et P. E. Gabriel (1991), « Risk Aversion and the Earnings of U.S. Immigrants and Natives », Applied Economics, 23 : 311-318.
- Blincoe, L.J., A.G. Seay, E. Zaloshnja, T.R. Miller, E.O. Romano, S. Luchter, R.S. Spicer (2002), The Economic Impact of Motor Vehicle Crashes, 2000, Washington D.C.: National Highway Traffic Safety Administration, DOT HS 809 446, 86 p.
- Brown, C. (1980), « Equalizing Differences in the Labor Market », Quarterly Journal of Economics, 94(1) : 113–134.
- Chestnut, L.G., D. Mills et R.D. Rowe (1999), « Air Quality Valuation Model Version 3.0 (AQVM 3.0) Report 2: Methodology », préparé pour Environnement Canada, Health Canada by Status Consulting Inc., Boulder, CO.
- Council of Economic Advisers (2005), Economic Report of the President, Washington, DC : Government Printing Office.
- Cousineau, J.-M., R. Lacroix et A.-M. Girard (1992), « Occupational Hazard and Wage Compensating Differentials », The Review of Economics and Statistics : 166-169.
- Dillingham, A.E. (1985), « The Influence of Risk Variable Definition on Value-of-Life Estimates », Economic Inquiry, 24 : 227–294.
- Dionne, G. et P.-C. Michaud (2002), « Statistical Analysis of Value-of-Life Estimates Using Hedonic Wage Method », cahier de recherche HEC Montréal, n° 02-01.
- Dorman, P. et P. Hagstrom (1998), « Wage Compensation for Dangerous Work Revisited », Industrial and Labor Relations Review, 52(1) : 116–135.
- Dorsey, S. et N. Walzer (1983), « Workers Compensation, Job Hazards, and Wages », Industrial and Labor Relations Review, 36 : 642-654.
- Fisher, A., L.G. Chestnut et D.M. Violette (1989), « The Value of Reducing Risks of Death: A Note on New Evidence », Journal of Policy Analysis and Management, 8(1) : 88-100.
- Florax, R.J.G.M. (2001), « Methodological Pitfalls in Meta-Analysis: Publication Bias », VU Research Memorandum, n° 2001–2028, Amsterdam.
- Furlong, W., D. Feeny, G.W. Torrance, C. Goldsmith, S. Depauw, M. Boyle, M. Denton et Z. Zhu (1998), « Multiplicative Multi-Attribute Utility Function for the Health Utilities Index Mark 3 (HUI3) System: A Technical Report », McMaster University Centre for Health Economics and Policy Analysis Working Paper, n° 98-11, Hamilton, Ontario : McMaster University.
- Gegax, D., S. Gerking et W. Schulze (1991), « Perceived Risk and the Marginal Value of Safety », The Review of Economics and Statistics, 589–597.
- Glass, G.V. (1976), « Primary, Secondary and Meta-analysis of Research », Educational Researcher, 5 : 3-8.
- Gunderson, M. et D. Hyatt (2001), « Workplace Risks and Wages: Canadian Evidence from Alternative Models », Canadian Journal of Economics, 34(2) : 377-395.
- Herzog, H.W. et A.M. Schlottmann (1990), « Valuing Risk in the Workplace: Market Price, Willingness to Pay, and the Optimal Provision of Safety », Review of Economics and Statistics : 463–470.
- Johannesson, M. (1995), « The Relationship between Cost Effectiveness Analysis and Cost Benefit Analysis », Social Science and Medicine, 41 : 483-489.
- Kim, S.-W. et P.V. Fishback (1999), « The Impact of Institutional Change on Compensating Wage Differentials for Accident Risk: South Korea, 1984-1990 », Journal of Risk and Uncertainty, 18 : 231-248.
- Knieser, T.J. et J.D. Leeth (1991), « Compensating Wage Differentials for Fatal Injury Risk in Australia, Japan and the United States », Journal of Risk and Uncertainty, 4(1) : 75–90.
- Knieser, T.J. et W.K. Viscusi (2005), « Value of a Statistical Life: Relative Position vs. Relative Age », Harvard Law and Economics Discussion Paper no 502.
- Krupnik, A., A. Alberini, M. Cropper, N.B. Simon, B. O’brien, R. Goeree et M. Heintzelman (2002), « Age, Health and the Willingness to Pay for Mortality Risk Reductions: A Contingent Valuation Survey of Ontario Residents », Journal ofRisk and Uncertainty, 24(2) : 161-186.
- Lanoie, P. (1993), « La valeur économique d’une vie humaine : où en sommes-nous? », in Gauthier, G. et M. Thibault (éds.), L’analyse coûts-avantages, défis et controverses, Économica, Paris, 526 p.
- Leeth, J.D. et J. Ruser (2003), « Compensating Wage Differentials for Fatal and Nonfatal Injury Risk by Gender and Race », Journal of Risk and Uncertainty, 27(3) : 257-277.
- Leigh, P.J. (1991), « No Evidence of Compensating Wages for Occupational Fatalities », Industrial Relations, 30(3) : 382-395.
- Leigh, P.J. (1995), « Compensating Wages, Value of a Statistical Life, and Inter-industry Differentials », Journal of Environmental Economics and Management, 28 : 83-97.
- Leigh, P.J. et R.N. Folsom (1984), « Estimates of the Value of Accident Avoidance at the Job Depend on the Concavity of the Equalizing Differences Curve », Quarterly Review of Economics and Business, 24(1) : 56-66.
- Lott, J. et R. Manning (2000), « Have Changing Liability Rules Compensated Workers Twice for Occupational Hazards? Earnings Premiums and Cancer Risks », Journal of Legal Studies, 29 : 99-130.
- Low, S.A. et L.R. Mcpheters (1983), « Wage Differentials and Risk of Death: An Empirical Analysis », Economic Inquiry, 21(2) : 271-280.
- Martinello, F. et R. Meng (1992), « Workplace Risks and the Value of Hazard Avoidance », Canadian Journal of Economics, 25(2) : 333–345.
- Mcdowell, I. (mcdowell@uottawa.ca), EuroQol EQ-5D, [courrier électronique à Martin Lebeau], 27 février 2006.
- Melinek, S.J. (1974), « A Method of Evaluating Human Life for Economic Purposes », Accident Analysis and Prevention, 6 : 103–114.
- Meng, R. et D.A. Smith (1990), « The Valuation of Risk of Death in Public Sector Decision-Making », Canadian Public Policy, 16 : 137–144.
- Meng, R. et D.A. Smith (1999), « The Impact of Workers’ Compensation on Wage Premiums for Job Hazards in Canada », Applied Economics, 31 : 1101-1108.
- Miller, P., C. Mulvey et K. Norris (1997), « Compensating Differentials for Risk of Death in Australia », Economic Record, 73 : 363-372.
- Miller, T.R. (1990), « The Plausible Range for the Value of Life — Red Herrings Among the Mackerel », Journal of Forensic Economics, 3(3) : 17–39.
- Moore, M. et W.K. Viscusi (1988b), « The Quantity-Adjusted Value of Life », Economic Inquiry, 26(3) : 369-388.
- Moore, M. et W.K. Viscusi (1989), « Rates of Time Preference and Valuations of the Duration of Life », Journal of Public Economics, 38(3) : 297-317.
- Moore, M. et W.K. Viscusi (1990a), « Discounting Environmental Health Risks: New Evidence and Policy Implications », Journal of Environmental Economics and Management, 18 : 51–62.
- Moore, M. et W.K. Viscusi (1990b), « Models for Estimating Discount Rates for Long-Term Health Risks Using Labor Market Data », Journal of Risk and Uncertainty, 3 : 381–401.
- Needleman, L. (1980), « The Valuation of Changes in the Risk of Death by Those at Risk », Manchester School of Economics and Social Studies, 48(3) : 229-254.
- Olson, C.A. (1981), « An Analysis of Wage Differentials Received by Workers on Dangerous Jobs », Journal of Human Resources, 16 : 167–185.
- Sandy, R., R.F. Elliott, W.S. Siebert et X. Wei (2001), « Measurement Error and the Effects of Unions on the Compensating Differentials for Fatal Workplace Risks », Journal of Risk and Uncertainty, 23(1) : 33-56.
- Shanmugam, K.R. (2001), « Self Selection Bias in the Estimates of Compensating Differentials for Job Risks in India », Journal of Risk and Uncertainty, 22(3) : 263-275.
- Siebert, W.S. et X. Wei (1994), « Compensating Wage Differentials for Workplace Accidents: Evidence for Union and Nonunion Workers in the UK », Journal of Risk and Uncertainty, 9 : 61–76.
- Smith, R.S. (1974), « The Feasibility of an “Injury Tax” Approach to Occupational Safety », Law and Contemporary Problems, 38 : 730–744.
- Summers, R. et A. Heston (1991), « The Penn World Table (Mark 5): An Expanded Set of International Comparisons, 1950-1988 », Quarterly Journal of Economics, 106 : 327-368.
- Viscusi, W.K. (1978b), « Labor Market Valuations of Life and Limb: Empirical Evidence and Policy Implications », Public Policy, 26 : 359–386.
- Viscusi, W.K. (2004), « The Value of Life: Estimates with Risks by Occupation and Industry », Economic Inquiry, 42(1) : 29-48.
- Weiss, P., G. Maier et S. Gerking (1986), « The Economic Evaluation of Job Safety: A Methodological Survey and Some Estimates for Austria », Empirica, 13(1) : 53-67.
- Wolf, F.M. (1986), Meta-Analysis: Quantitative Methods for Research Synthesis, Sage Publications.
- Zhang, A., A.E. Boardman, D. Gillen et W.G. Waters II (2004), « Towards Estimating the Social and Environmental Costs of Transportation in Canada », Report for Transport Canada, UBC Centre for Transportation Studies, 450 p.
Autre bibliographie
Liste des figures
Graphique 1
Forme des courbes d’indifférence entre la richesse et la probabilité de décès
Graphique 2
Disposition à payer agrégée selon la concentration du risque
Graphique 3
Amélioration au sens de Pareto
Graphique 4
Équilibre sur le marché du travail
Liste des tableaux
Tableau 1
Probabilité de décès moyenne par industrie (BLS : 1972-1982, NIOSH : 1980-1985)
Tableau 2
Probabilité de décès moyenne par industrie (1992-1995)
Tableau 3
Résumé des résultats des méta-analyses