Résumés
Résumé
L’acquisition L2 des compléments infinitifs français (CI ; p. ex. chercher à + infinitif, empêcher de + infinitif, aller Ø + infinitif) implique d’apprendre que le choix de la préposition (à, de ou élément nul) qui précède l’infinitif est arbitraire et qu’il doit être déterminé cas par cas. L’anglais (la L1 des participants de cette étude) utilise uniquement la préposition to ‘à’ à cette fin. Cette étude vise à répondre aux questions suivantes : (1) Quels types d’erreurs les apprenants anglophones font-ils relativement aux constructions verbales à CI ? ; (2) Y a-t-il une utilisation généralisée d’une des prépositions ? Nous avons supposé que (1) tous les apprenants utiliseraient à, de et l’élément nul dans des contextes inappropriés, (2a) que à serait surgénéralisé par les apprenants moins compétents à cause de l’influence translinguistique, (2b) tandis que de serait surgénéralisé par les apprenants plus compétents en raison de sa fréquence élevée dans l’input. Nous avons examiné la production et la compréhension des CI chez onze apprenants L2 (six moins compétents, cinq plus compétents) à l’aide d’un test à trous et d’une tâche de jugement de grammaticalité ; et nous avons trouvé (i) des erreurs relatives au choix de la préposition, (ii) ainsi qu’une surgénéralisation de la variante de que nous avons interprétée comme une conséquence de sa fréquence importante dans l’input.
Mots-clés :
- influence translinguistique,
- input,
- sur-généralisation,
- acquisition L2,
- compléments infinitifs
Abstract
The L2 acquisition of French infinitival complements (e.g., chercher à ‘seek to’ + infinitive, essayer de ‘try to’ + infinitive, vouloir Ø ‘want to’ + infinitive) involves learning that the choice of preposition (à, de, or null element) preceding the infinitive is arbitrary and must be acquired on a case-by-case basis. English (participants’ L1 in the present study) uses only the preposition to in this context. This study sought to answer the following questions: (1) What types of errors do less and more proficient Anglophone L2 learners make with infinitival complements introduced by the prepositions à, de or a null element ?; (2) Is one variant overgeneralized as a default form ? We hypothesized that (1) all learners would make incorrect preposition choices, (2a) that à would be overgeneralized by the less proficient learners due to cross-linguistic influence, (2b) while de would be overgeneralized by the more proficient learners due to input frequency. We examined 11 learners’ (six less proficient, five more proficient) production and comprehension of French infinitival complements using a cloze test and a grammaticality judgment task and found (i) errors with preposition choice; (ii) an overgeneralization of the variant de, that we propose is due to its high frequency in the input.
Keywords:
- crosslinguistic influence,
- input,
- over-generalization,
- L2 acquisition,
- infinitival complements
Resumen
La adquisición L2 de los complementos infinitivos en francés (por ejemplo, chercher à ‘tratar de’ + infinitivo, empêcher de ‘impedir de’ aller Ø ‘ir’ + infinitivo) implica aprender que la elección de la preposición (à ‘a’, de ‘de’ o elemento nulo) que precede el infinitivo es arbitrario y que tiene que ser determinado caso por caso. El inglés (la L1 de los participantes de este estudio) utiliza únicamente la preposición to ‘a’ a este fin. Este estudio trata de responder a las preguntas siguientes: (1) Cuáles son los tipos de errores que los aprendices anglófonos hacen relativamente a las construcciones verbales introducidas por las preposiciones à, de o elemento nulo? (2) Existe una utilización generalizada de una de estas preposiciones? Supusimos que (1) todos los aprendices utilizarían à, de y el elemento nulo en contextos inapropiados, (2a) que à seria sobregeneralizada por los menos competentes a causa de la influencia translingüística, (2b) mientras la de sería sobregeneralizada por los aprendices mas competentes gracias a su frecuencia elevada en el input. Examinamos la producción y la comprensión de once aprendices (seis menos competentes, cinco mas competentes) con la ayuda de una prueba de cloze y pruebas de juzgamiento de gramaticalidad; y nosotros encontramos (i) errores relativos a las elecciones de la preposición, (ii) con una sobregeneralización de la variante de que interpretamos como una consecuencia de su frecuencia importante en el input.
Corps de l’article
La maîtrise de la syntaxe dépend pour beaucoup de la connaissance des verbes. Or, dans le contexte de l’acquisition d’une langue seconde, cette connaissance exige habituellement beaucoup d’effort à l’apprenant. Les caractéristiques des verbes qui doivent être acquises sont nombreuses : structure argumentale, sémantique, morphosyntaxe des temps, mode, aspect, etc. Cette étude se concentrera sur la sous-catégorisation.
L’acquisition des compléments verbaux implique d’apprendre que les différents verbes prennent des arguments différents et, pour les verbes à complément infinitif (CI ; p. ex. chercher à + INFINITIF, empêcher de + INFINITIF, allerØ (élément nul) + INFINITIF), que le choix de la préposition doit être déterminé cas par cas. Dans le cas des CI, l’anglais utilise uniquement la préposition to ‘à’ pour relier le verbe matrice à son complément (p. ex. She tries to read. ‘Elle essaie de lire’ ; She is learning to dance. ‘Elle apprend à danser’ ; They want to eat. ‘Ils veulent manger’ ; voir §1 pour plus de détails). Par contraste, le français utilise soit à, soit de, soit un élément nul (p. ex. Il essaie d’apprendre le français. ; Il commence à comprendre.; Il désire partir maintenant.).
En acquisition L2, les erreurs relatives au choix de la préposition précédant les CI sont fréquentes et constituent un problème persistant, même pour les apprenants avancés. Toutefois, qu’il s’agisse du français ou de quelque autre langue typologiquement semblable, aucune étude n’a été jusqu’ici publiée sur le sujet. Dans la présente étude, nous chercherons plus particulièrement à répondre aux questions suivantes : (1) Quels types d’erreurs font les apprenantes[1] anglophones relativement aux constructions verbales à compléments infinitifs introduits par les prépositions à, de ou l’élément nul ? (2) Une des variantes est-elle surgénéralisée en tant que forme par défaut ?
Nous examinerons l’acquisition des CI en français L2 chez plusieurs apprenantes anglophones à l’aide de différents instruments, dont un questionnaire sur leurs antécédents linguistiques et un test de vocabulaire (le test X_Lex2 ; voir §4.2) qui ont servi à évaluer la compétence générale des apprenantes, et deux tâches expérimentales (un test à trous et une tâche de jugement de grammaticalité ; voir §4.3.1) qui ont permis d’évaluer la production des CI. Pour ce qui est de l’organisation de cet article, après avoir discuté de la structure des CI en français (langue cible), en anglais (L1 des apprenantes) et dans l’interlangue des apprenants du français (§1), nous présenterons des concepts d’acquisition pertinents pour l’étude expérimentale (§2) et une étude antérieure sur les stratégies de pauses précédant les CI chez les apprenants du français L2 (Genc, Mavasoglu et Bada 2009) qui sert à motiver la présente étude (§3). Ensuite, nous expliquerons en détail les hypothèses (§4.1), puis nous présenterons les participantes (§4.2), la méthodologie (§4.3) et les résultats (§5). Nous terminerons cette étude par l’évaluation de nos hypothèses (§6.1) et une brève conclusion (§6.2).
1. Les compléments infinitifs en français, en anglais et dans l’interlangue des apprenants du français
En français, les CI sont normalement introduits par à ou de, mais certains infinitifs sont plutôt précédés d’un élément nul. Le tableau 1, créé à l’aide du site web l’Espace français (http://www.espacefrancais.com), présente des verbes fréquents représentatifs de chaque catégorie. Comme il est indiqué dans le tableau, certains verbes apparaissent soit avec à, soit de selon le contexte.[2]
Tableau 1
Exemples de verbes matrices fréquents à compléments infinitifs introduits par à, par de, par les deux prépositions ou par un élément nul
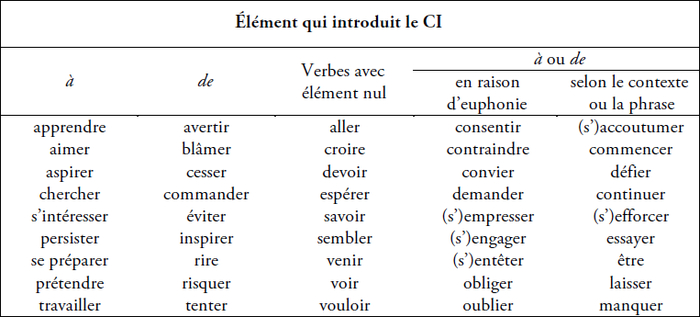
Cox (1983 : 168) prétend que la variabilité de l’élément précédant les CI est une caractéristique qui ne peut pas être enseignée, mais qui doit plutôt être apprise. Selon lui, le choix de la préposition est complètement arbitraire. Huot (1981 : 43) suggère qu’en français de est la plus fréquente des trois variantes. Kalmbach (2008) affirme aussi que l’infinitif est normalement précédé de de et parfois de à. Selon cet auteur, les exceptions (c’est-à-dire les cas où l’infinitif est précédé de à) ne sont pas nombreuses, même si la fréquence d’apparition élevée des verbes matrices qui sont suivis de à donne l’impression inverse.
En fait, l’usage du marqueur d’infinitif de était plus systématique dans la langue classique. Kalmbach reprend Haase (1898 : 296-311) qui présente des cas dans lesquels l’usage de l’époque diverge de celui d’aujourd’hui (p. ex. Il leur sembloit de voir toujours ce visage [Vaugelas]). En effet, de nombreux verbes ont changé de préposition au cours de l’histoire. Des verbes qui, à une époque se construisaient avec de (p. ex. hésiter de faire qqch, s’obstiner de faire qqch, exhorter de faire qqch), se construisent aujourd’hui plutôt avec à (Kalmbach 2008 : 67). La fréquence de de dans les exemples de Haase indique que le marqueur d’infinitif de était « un élément solidement ancré dans la langue ancienne » (Kalmbach 2008 : 67). Kalmbach souligne qu’en plus, lors du passage de de à à, il y a eu dans certains cas disparition du marqueur précédant le verbe (p. ex. les CI précédés de adorer, aimer, désirer, détester, espérer, oser, souhaiter). Selon lui, la raison pour laquelle de est devenu à n’est pas claire.
Le fait que le marqueur de soit plus fréquent que à et l’élément nul pourrait influencer la façon dont les apprenants acquièrent les CI. Il est bien connu que les apprenants L2 acquièrent les mots qui sont plus fréquents dans l’input avant les mots moins fréquents (p. ex. de Groot et Keizjer 2000). De la même façon, la fréquence influence l’acquisition des constructions linguistiques (Kirjavainen et coll. 2009 : 314). Kirjavainen et coll. (2009) ont trouvé que les représentations linguistiques des enfants sont affectées par la fréquence d’occurrence de certaines constructions (p. ex. les séquences de verbes) dans l’input qu’ils entendent. Gaffney (2014) a examiné les premiers verbes matrices utilisés dans les CI par les apprenantes anglophones intermédiaires du français en analysant des données spontanées tirées du corpus FLLOC (Myles et Mitchell 2007).[3] Tous les verbes en question (pouvoir, devoir, aller, vouloir, falloir, venir, décider de, aimer, essayer de, tenter de, espérer, préférer)[4] figurent parmi les 600 mots les plus fréquents du français selon Lonsdale et Le Bras (2009). Par conséquent, si les apprenantes sont influencées par la fréquence élevée de de dans l’input, on devrait s’attendre à voir une surgénéralisation de de dans leur production des CI.
Examinons maintenant la structure des CI en anglais, la L1 des apprenantes de l’étude que nous présenterons en §4.2. En anglais, il n’existe aucune variabilité quant à l’élément qui précède l’infinitif des CI. Comme nous l’avons déjà mentionné dans l’introduction, le seul complémenteur qui figure dans ces constructions est to ‘à’ (voir l’introduction pour des exemples). Historiquement, ce complémenteur est dérivé de la préposition homophone ayant un sens directionnel (p. ex. Caitlin goes to the library. ‘Caitlin va à la bibliothèque’). L’équivalent français de to, préposition directionnelle, est à. Jespersen (1964) décrit le to infinitif contemporain de l’anglais comme « a grammatical implement with no meaning of its own » (330), soit un élément purement syntaxique.
En résumé, en ce qui concerne l’introduction des CI, l’anglais diffère du français. Étant donné le rôle important de l’influence translinguistique en acquisition L2 (voir §2 pour plus de détails), une comparaison entre les constructions avec CI en français et en anglais nous permet de faire des hypothèses concrètes. On pourrait imaginer que, étant donné l’unicité de to comme élément qui introduit les CI en anglais, les apprenantes L2 anglophones puissent finir par surgénéraliser la préposition équivalente à en français. Cette hypothèse sera testée dans l’étude présentée en §4. Toutefois, avant d’aborder l’étude expérimentale, nous devons d’abord considérer quelques concepts pertinents pour notre étude ainsi qu’une étude antérieure.
2. Phénomènes acquisitionnels pertinents pour l’étude de l’acquisition L2 des CI
Dans cette section, nous examinerons deux concepts importants pour comprendre l’acquisition L2 des compléments infinitifs : l’influence translinguistique et la surgénéralisation. Taylor (1975) suppose que la surgénéralisation et l’influence translinguistique constituent deux manifestations linguistiques distinctes d’un seul processus psychologique, à savoir la dépendance générale des apprenants L2 en regard des connaissances déjà acquises qui servent à faciliter l’acquisition (p. 73). Comme nous l’avons vu dans la section précédente, il existe des différences importantes entre les systèmes de CI en français et en anglais, et on pourrait s’attendre à ce que la production des apprenantes anglophones soit influencée, au moins en partie, par leur L1.
Odlin (2003) définit le transfert (ou l’influence translinguistique) comme l’influence qui résulte des similitudes et des différences entre la langue cible et toute autre langue qui a déjà été acquise ; elle explique que l’influence translinguistique exige une identification interlingue (angl. interlingual identification), c’est-à-dire un jugement établissant qu’une structure de la L1 et une structure de la L2 sont similaires (p. 454). Adjemian (1983) a trouvé que les apprenants L2 débutants utilisent d’abord des informations lexicales appropriées pour la L1. Dans son étude sur l’acquisition du lexique français par des anglophones et du lexique anglais par des francophones, ce chercheur a constaté que les apprenants L2 transfèrent des schémas lexicaux de leur L1 à leur L2. Adjemian a observé que les apprenants des deux langues supposent que les verbes de la langue cible prennent les mêmes types de sujets et d’objets que dans leur L1. Par exemple, les apprenants anglophones du français ont produit des phrases agrammaticales comme *Elle marche les chats. Le verbe anglais correspondant walk ‘marcher’ est à la fois transitif et intransitif (p. ex. She walks. ‘Elle marche’ ; She walks her dog. ‘Elle promène son chien’). Par contraste, le verbe français marcher est uniquement intransitif. Dans cette perspective, Towell et Hawkins (1994) fournissent des exemples d’influences translinguistiques lexicales tirés de la production des apprenants francophones de l’anglais (p. ex. I *have very hungry. ‘J’ai très faim’ et I *have twelve years old. ‘J’ai douze ans’). En français, le verbe qui figure dans ces constructions (avoir) correspond au verbe anglais have. D’après ces types d’erreurs, il est évident que les apprenants L2 transfèrent des schémas lexicaux de leur L1, y compris la structure d’argument des verbes. Comme l’élément qui introduit les CI en anglais et en français est un item purement lexical, il s’ensuit que le transfert de l’anglais pourrait influencer l’acquisition des prépositions qui introduisent les CI chez les apprenants L2 du français.
Outre les erreurs mentionnées ci-dessous, l’influence translinguistique peut également entraîner la surgénéralisation. Ortega (2009 : 117) décrit la surgénéralisation comme l’emploi d’une forme ou d’une règle dans des contextes illicites, par exemple l’utilisation fréquente de la terminaison –ed avec les verbes irréguliers en anglais (p. ex. Leung 2006) et le suremploi de l’article défini masculin par des apprenants du français dans des contextes qui requièrent l’article féminin (Bartning 2000). Selinker (1972) définit la surgénéralisation comme un type d’erreurs de production systématique qui ont lieu lorsque l’apprenant transfère une règle de la langue maternelle et viole des règles de la langue cible. En bref, la surgénéralisation consiste toujours à transférer des règles ou des formes dans des contextes inappropriés. Un élément surgénéralisé peut aussi devenir une forme par défaut. Par exemple, Bartning (2000) stipule que les apprenants avancés du français ont tendance à surgénéraliser le genre masculin avec le déterminant défini et donc la plupart des apprenants utilisent le comme forme par défaut.
Dans la section suivante, nous présenterons une étude antérieure sur l’acquisition des CI (Genc et coll. 2011). À notre connaissance, cette étude sur les différences de fluidité dans la production L1 et L2 des constructions françaises avec CI est la seule publication sur l’acquisition L2 de cette structure. Les résultats de cette étude serviront à construire les hypothèses de l’étude présentée en §4.1.
3. Étude antérieure sur les différences de fluidité entre les locuteurs natifs et les apprenants L2 dans la production des constructions avec CI : Genc, Mavasoglu et Bada (2011)
Dans cette section, nous présentons les résultats de Genc et coll. (2011) qui sont pertinents pour l’élaboration d’une étude de l’acquisition L2 des CI. Ces chercheurs ont observé des différences entre les locuteurs natifs et non natifs dans la production des constructions à CI du français. Plus précisément, les locuteurs non natifs ont fait de longues pauses devant les compléments infinitifs introduits par à ou de. Nous suggèrerons ici que ces différences sont attribuables aux difficultés que rencontrent les apprenants L2 dans le choix de la préposition qui précède les compléments infinitifs.
Genc et coll. ont examiné les enregistrements des locuteurs natifs et non natifs du français (L1 turc) et ont cherché à déterminer les différentes stratégies de pause qu’ils ont employées. Les participants étaient dix-sept locuteurs natifs âgés de 20 à 50 ans, tous détenteurs d’un diplôme universitaire. Cinq des locuteurs natifs étaient des enseignants aux départements de français de deux différentes universités en Turquie ; les autres étaient des enseignants de différentes matières en France. Les locuteurs non natifs étaient 60 étudiants turcophones de premier cycle du département de français de l’Université de Çukorova en Turquie. Au moment de l’étude, les soixante participants turcophones avaient suivi une formation pour devenir enseignants de français.
Les deux groupes ont regardé un film et ont commenté ses différents thèmes, puis ont raconté individuellement les principaux évènements du film dans les bureaux des chercheurs. Ensuite, les chercheurs ont enregistré les récits puis les ont transcrits pour l’analyse. En moyenne, les pauses précédant la particule à ou de dans les phrases à CI produites par les locuteurs non natifs étaient plus longues que celles des locuteurs natifs (durée moyenne de 352 contre 145 millisecondes). Genc et coll. (2011) suggèrent que les locuteurs non natifs ont des difficultés à maîtriser la prosodie et que ces difficultés sous-tendent la différence observée entre les apprenants et les locuteurs natifs. Les chercheurs ne réfèrent pas à la difficulté éprouvée par les locuteurs L2 relativement au choix de la préposition pour expliquer les différences de durée. Or, on a de bonnes raisons de le faire. Plus précisément, on peut croire qu’en raison du fait que les apprenants L2 n’ont pas pleinement acquis la sous-catégorisation verbale, ils réagissent moins rapidement que leurs homologues locuteurs natifs lors du choix de la préposition qui précède les CI.
En plus de cette asymétrie entre les deux groupes, on constate aussi une différence importante entre le nombre de phrases infinitives dans le discours spontané des locuteurs natifs (98 occurrences dans les 17 récits, soit 5,8 occurrences par récit), d’une part, et celui des locuteurs non natifs (28 occurrences dans les 60 récits ou 0,47 occurrence en moyenne), d’autre part. Les auteurs de l’étude ne discutent pas de cette asymétrie ; ils soulignent simplement le besoin d’en chercher l’explication dans des études ultérieures. Nous voudrions avancer ici une interprétation : les apprenants L2 de cette étude ont évité les constructions verbales complexes en raison de leur manque de maîtrise de ces structures. Ces apprenants ont pu employer d’autres moyens pour communiquer leurs pensées là où ils étaient incertains du choix de la préposition qui relie le verbe matrice et son CI. Dans son ensemble, l’étude de Genc et coll. montre que les apprenants L2 du français utilisent les constructions infinitives moins souvent que les locuteurs natifs du français et qu’ils hésitent davantage avant de produire une construction infinitive. Étant donné ces deux phénomènes, on peut supposer l’existence d’une difficulté relative à ces constructions verbales, y compris au choix de la préposition.
Dans ce qui suit, nous présentons l’étude que nous avons élaborée afin de vérifier si les constructions à CI étaient vraiment difficiles à assimiler pour les apprenants du français L2 et, le cas échéant, afin de mesurer le degré de cette difficulté.
4. Étude expérimentale
Pour documenter les types d’erreurs lexicales que font les apprenants anglophones lors de la production des CI en français et pour découvrir si une des prépositions est choisie plus souvent que les autres variantes, nous avons mené l’étude expérimentale qui sera décrite dans les sections qui suivent.
4.1. Hypothèses
Trois hypothèses ont servi à encadrer l’étude présentée ici. Les deux premières sont reliées à la première question de recherche : Quels types d’erreurs font les apprenantes anglophones avec les constructions verbales à complément infinitif introduites par les prépositions à, de ou l’élément nul ?
La première hypothèse vise la qualité des erreurs : (H1) : En général, nous supposons que les apprenantes anglophones utilisent les trois variantes – à, de et l’élément nul – dans des contextes inappropriés à cause de facteurs tels que l’influence translinguistique et l’input. Du fait que to est le seul élément anglais qui introduit les CI, il est possible que les apprenantes L2 anglophones surgénéralisent la préposition à, son équivalent français. De plus, les apprenantes pourraient utiliser la préposition de dans des contextes inappropriés, car elle est plus fréquente dans l’input.
La deuxième hypothèse vise plutôt la quantité d’erreurs : (H2) : Nous prédisons que les erreurs seront moins fréquentes chez les apprenantes plus avancées.
Ensuite, nous abordons la deuxième question de recherche : Une des variantes est-elle surgénéralisée en tant que forme par défaut ? En émettant ces hypothèses, nous nous basons sur les rôles de l’influence translinguistique (qui favorise à) et sur la fréquence des formes dans l’input (qui favorise de). L’influence translinguistique diminue au fur et à mesure que la compétence L2 s’améliore (p. ex. Major 2001). Alors, la L1 devrait jouer un rôle plus important chez les apprenantes moins avancées. Nous supposons ainsi que les apprenantes moins avancées utiliseront à, l’équivalent français du to anglais, la seule option dans cette langue. Par contraste, nous supposons que les apprenantes plus avancées seront plus influencées par les tendances observées dans l’input et qu’elles surgénéraliseront ainsi la préposition de qui est plus fréquente en français que à ou l’élément nul (voir §1).
(H3a) : Étant donné le rôle plus important de l’influence translinguistique chez les apprenantes moins avancées, nous supposons que à sera surgénéralisé par ces apprenantes.
(H3b) : Étant donné le rôle important de l’input, surtout chez les apprenantes plus avancées, nous supposons que de sera surgénéralisé par ces apprenantes.
4.2. Participantes
Onze apprenantes L2 anglophones âgées de 19 à 25 ans ont participé à l’étude. Trois des apprenantes détenaient déjà un diplôme universitaire avec une concentration en linguistique (n=2) ou en littérature françaises (n=1) ; les huit autres poursuivaient leurs études au moment de l’expérience. L’expérience faisait intervenir un questionnaire sur les antécédents linguistiques et une évaluation de la compétence en français, le test de connaissances lexicales X_Lex2.
4.2.1. Profils linguistiques des apprenantes
Un questionnaire a permis d’obtenir des renseignements sur le profil linguistique des participantes (p. ex. leur langue maternelle, la langue maternelle de leur mère et de leur père, la langue qu’elles parlent chez elles, leur(s) langue(s) seconde(s), l’âge au début de l’acquisition L2, leur éducation, leur type de formation linguistique [p. ex. immersion] et leur utilisation de leurs langues connues).
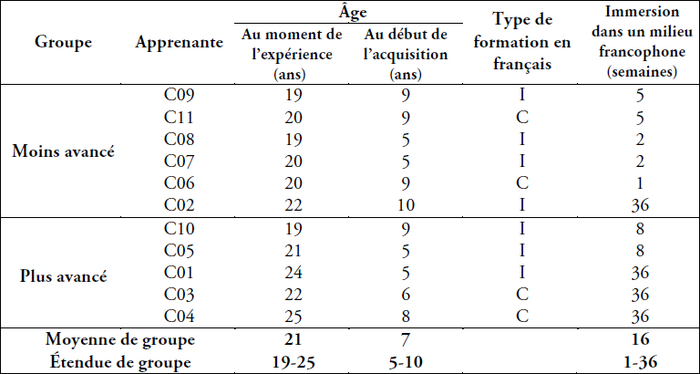
Comme le montre le tableau 2, toutes les apprenantes ont commencé à apprendre le français entre les âges de 5 et 10 ans. Tandis que la majorité d’entre elles était inscrite dans des programmes scolaires d’immersion française (I) aux niveaux primaire et secondaire, quatre apprenantes ont fait le français cadre (C). Comme on le remarque dans le tableau 2, les apprenantes plus avancées ont passé plus de temps en milieu francophone. La seule exception est C02, qui a passé 36 semaines en France mais qui était toutefois dans le groupe moins avancé. Cependant, comme on le verra dans la section suivante, c’est elle qui, de toutes les apprenantes du groupe moins avancé, a eu le meilleur score dans le test X_Lex2.
Tableau 2
Expérience linguistique des apprenantes anglophones moins avancées et plus avancées selon leurs réponses au questionnaire sur leurs antécédents linguistiques
4.2.2. Test de compétence lexicale X_Lex2
Le test de compétence lexicale X_Lex2 (http://www.lognostics.co.uk) est un test oui/non élaboré par Meara et Milton (2003) qui sert à évaluer la taille du vocabulaire des apprenants. Ce test comprend 120 mots dont 100 mots réels et 20 mots inventés qui ressemblent à des mots français, ceux-ci servant à dépister les apprenants qui surestiment leurs connaissances lexicales. Les participants doivent indiquer les mots qu’ils connaissent ou savent employer.[5] Comme il existe un lien étroit entre la taille du vocabulaire et la compétence plus générale (p. ex. Read 2001), nous emploierons les résultats du test X_Lex2 comme mesure de la compétence globale des apprenantes dans notre étude.
Les données obtenues du test X_Lex2 ont été traitées comme suit. Pour calculer le score d’une apprenante, on compte le nombre de mots vrais reconnus qu’on multiplie par 50. Ensuite, on compte le nombre de mots inventés cochés qu’on multiplie par 250. Finalement, on soustrait le deuxième nombre du premier pour obtenir le score du test. En soustrayant le deuxième nombre du premier, on ajuste le score de l’apprenante afin d’éviter des surestimations de leur compétence lexicale. Le score maximal du test X_Lex2 est ainsi de 5000 (100 mots réels x 50 points par mot identifié).
Comme le montre le tableau 3 où figurent les scores ajustés des apprenantes sur le test X_Lex2, il y a deux niveaux de compétence distincts : moins avancé et plus avancé. Les moyennes et les étendues pour les scores au test X_Lex2 pour chaque groupe d’apprenantes dans cette étude sont affichées dans ce tableau.
Tableau 3
Compétence en français des apprenantes anglophones d’après les scores ajustés sur le test X_Lex2 (maximum de 5000)

La littérature critique présente plusieurs exemples où le score du test X_Lex2 est explicitement corrélé aux niveaux du Cadre européen commun de référence pour les langues (CECR). Milton et Meara (2003) ont testé des apprenants L2 de l’anglais qui avaient réussi aux examens de Cambridge (qui évaluent la lecture, la rédaction, la production orale et l’écoute) à tous les niveaux du CECR et ils ont mesuré la taille de leur vocabulaire en utilisant le test X_Lex, la version anglaise du test X_Lex2. Ces chercheurs ont trouvé qu’il y avait une corrélation positive entre le niveau déterminé par le CECR et la taille du vocabulaire mesurée par le test X_Lex. Leurs résultats nous permettent de définir la compétence de nos apprenantes selon les niveaux du CECR, ce qui facilite la comparaison des scores du test X_Lex2.
On constate à partir de la comparaison entre les scores de nos participantes et les scores des apprenants L2 de l’anglais de l’étude de Meara et Milton (2003) que les apprenantes de notre étude varient entre A2 (pré-intermédiaire) et C1 (avancé). Selon les niveaux du CECR, nos apprenantes sont de quatre niveaux : trois d’entre elles (C09, C11, C08) sont du niveau A2 (pré-intermédiaire), trois (C07, C06, C02) sont de niveau B1 (intermédiaire), quatre d’entre elles (C10, C05, C01, C03) de niveau B2 (intermédiaire supérieur) et la dernière apprenante (C04) est de niveau C1 (avancé). Selon l’étude de Meara et Milton (2003), il existe une différence de compétence entre les apprenants ayant un score inférieur à 3250 (B1) et supérieur à 3250 (B2). Pour simplifier notre analyse, on peut ainsi former deux groupes distincts d’apprenantes moins avancées (scores inférieurs à 3250 : C09, C11, C08, C07, C06, C02) et plus avancées (scores supérieurs ou égal à 3250 : C10, C05, C01, C03, C04).
4.3. Méthodologie expérimentale
Dans la présente section, nous présentons en détail les tâches et les stimuli employés dans l’expérience, le protocole expérimental et, finalement, l’analyse des données.
4.3.1. Tâches expérimentales
L’expérience était composée de deux tâches expérimentales : un test à trous et une tâche de jugement de grammaticalité. En planifiant cette expérience, nous cherchions à définir une tâche supplémentaire pour vérifier les résultats du test à trous et pour nous assurer que la tâche n’exercerait pas d’influence. Le test à trous devait mesurer la production écrite des CI tandis que la tâche de jugement de grammaticalité était supposée recueillir des données métalinguistiques et corroborer les résultats obtenus du test à trous.
Les tests à trous nécessitent la capacité de comprendre le contexte et le vocabulaire afin de remplir les blancs ou compléter le texte/la phrase. Cette tâche est souvent employée pour l’évaluation de la compétence L2. Pour la présente étude, la partie supprimée de la phrase était la préposition entre le verbe matrice et l’infinitif (p. ex. Je promets __ aller à l’école aujourd’hui. ; Nous travaillons __ régler le problème.). Pour les phrases à CI introduits par un élément nul, il y avait aussi un blanc entre le verbe matrice et l’infinitif (p. ex. Kim Kardashian et Kanye West veulent __ appeler leur fils « North ».). Selon les directives[6], les participants devaient insérer la préposition appropriée.
Pour corroborer les résultats du test à trous, nous avons utilisé une tâche de jugement de grammaticalité qui a recueilli des données métalinguistiques et qui a testé la compréhension des participants.[7] Dans une tâche de jugement de grammaticalité, les apprenants partagent leurs intuitions ou leurs jugements en ce qui concerne une phrase donnée et les données qui en résultent représentent des connaissances partiellement métalinguistiques (Gass et Selinker 2008).
Ces deux tests ont été très efficaces pour obtenir des données concernant le choix de la préposition qui introduit les CI. La possibilité de manquer de constructions à CI des trois types nous a empêché de recueillir des données à partir d’autres tâches plus spontanées, comme il aurait peut-être été souhaitable. Une tâche de production orale aurait produit des données plus représentatives de la compétence purement linguistique des apprenantes car celles-ci auraient été obligées de produire des phrases sans avoir beaucoup de temps de réflexion. Ceci aurait ainsi réduit l’influence des connaissances métalinguistiques. Toutefois, dans un contexte de parole spontanée, les apprenants peuvent éviter certaines structures. En outre, avec une tâche de production spontanée, il n’existe aucun moyen de garantir que les participants vont utiliser la structure verbale en question ou qu’ils vont utiliser des verbes matrices suivis des trois éléments à, de et l’élément nul. Par exemple, un apprenant qui connaît la construction vouloir + INFINITIF pourrait choisir d’utiliser celle-ci dans la parole spontanée et d’éviter d’autres constructions qui lui sont moins familières comme se préparer à + INFINITIF.
4.3.2. Stimuli
Dans la création des stimuli pour le test à trous et pour la tâche de jugement de grammaticalité, il y avait deux variables à contrôler, soit la fréquence du verbe matrice et la préposition qui précède le CI (à, de ou l’élément nul). Seuls les verbes de haute fréquence (ceux qui figurent parmi les 5000 mots les plus fréquents du français selon Lonsdale et Le Bras 2009) ont été utilisés pour nous assurer que toutes les participantes les aient déjà rencontrés dans l’input auquel elles avaient été exposées (voir les annexes B et D).[8] Il convient de noter que même s’il était possible de contrôler la fréquence des verbes matrices de toutes les constructions, il n’était pas possible de déterminer la fréquence de ces verbes dans les constructions à CI en question. Ceci constitue une limitation qui n’aurait pu être corrigée que si la fréquence de chaque verbe dans la construction en question avait été calculée en utilisant une grande base de données de parole spontanée, ce qui n’était pas possible au moment de l’expérience. Pour chacune des deux tâches expérimentales, les stimuli comprenaient un nombre égal de verbes matrices suivis de chaque option (à, de ou l’élément nul). Les stimuli ont été randomisés à l’aide du Research Randomizer (http://www.randomizer.org ; Urbaniak et Plous 2011) et l’ordre était différent pour chaque participante.
Pour le test à trous, pour chacune des trois prépositions, nous avons créé huit phrases avec CI pour un total de 24 stimuli (tableau 4), incluant 12 distracteurs. Dans ces dernières phrases, les trous remplaçaient des déterminants et des pronoms objets.
Tableau 4
Résumé des stimuli (phrases cibles et distractrices) pour le test à trous

Les stimuli pour la tâche de jugement de grammaticalité comprenaient six verbes différents, chacun figurant dans trois phrases dont une avec la préposition grammaticale et deux avec des prépositions agrammaticales en fonction du verbe choisi (tableau 5). Lors de la création des stimuli, nous avons contrôlé le type de préposition (une option grammaticale et deux options agrammaticales), ce qui a fini par créer 18 stimuli en tout. Les phrases comprenaient neuf distracteurs, dont quatre étaient grammaticaux tandis que cinq étaient agrammaticaux (absence d’un élément morphologique obligatoire (p. ex. l’article défini), utilisation d’un élément morphologique incorrect (p. ex. flexion verbale ; Il n’aimes pas le café; il préfère le thé.).
Tableau 5
Stimuli (phrases cibles et distractrices) pour la tâche de jugement de grammaticalité linguistiques

4.3.3. Protocole expérimental
Nous avons testé toutes les participantes individuellement dans une pièce tranquille. Nous avons commencé par obtenir le consentement éclairé des participantes. Ensuite, nous avons administré le questionnaire portant sur leurs antécédents linguistiques. Après avoir rempli le questionnaire, les participantes ont fait le test X_Lex2, puis la tâche de jugement de grammaticalité et, enfin, le test à trous. La structure cible étant plus évidente dans le test à trous, nous avons jugé préférable que les participantes fassent la tâche de jugement de grammaticalité – la tâche la plus difficile – avant le test à trous afin de réduire les chances qu’elles devinent l’objet de l’étude. En moyenne, chaque séance expérimentale a duré une heure.
4.3.4. Analyse des données
Les réponses du test à trous ont été reparties en réponses correctes ou incorrectes. Pour chaque participante, nous avons calculé la note globale sur le test, puis, pour les deux groupes, l’étendue, l’écart-type et la moyenne des scores. Les réponses incorrectes ont été comptées et classées en quatre catégories : à, de, élément nul et ‘autre’ là où les participantes avaient inséré un mot autre que à, de ou l’élément nul (p. ex. un clitique objet). Ensuite, nous avons calculé la fréquence relative de chaque réponse-type pour chaque apprenante et pour chaque groupe. Finalement, nous avons calculé la moyenne pour chaque type d’erreur (utilisation incorrecte de à, de ou l’élément nul).
Pour la tâche de jugement de grammaticalité, les réponses ont été jugées correctes ou incorrectes et le pourcentage de bonnes réponses a été calculé pour chaque apprenante. Toutes les erreurs n’ont pas été analysées y compris celles qui ne concernaient pas la préposition devant le CI, par exemple les phrases agrammaticales jugées comme agrammaticales mais pour lesquelles les participantes avaient mal identifié la source de l’agrammaticalité (p. ex. *Sa femme est le seul être vivant qu’il semble à aimer sincèrement ; Réponse : *Sa femme est la seule être vivant qu’il semble à aimer sincèrement.). Les erreurs que nous avons analysées comprenaient des phrases (1) avec des prépositions incorrectement jugées comme grammaticales (p. ex. *Il dit qu’il espère à aller à l’Université de Toronto parce qu’il aime la ville.) ; (2) où les apprenantes avaient changé la préposition à tort dans une phrase grammaticale (p. ex. l’insertion de de : Elle espère _ apprendre le français parce qu’elle veut aller en France.) ; et (3) où la préposition agrammaticale avait été remplacée par une autre préposition agrammaticale (p. ex. à : *Il est défendu _ parler cette langue.).
Ensuite, nous avons classé toutes les erreurs que nous avons analysées en trois catégories selon la variante qui a été jugée incorrectement comme grammaticale ou agrammaticale (à, de ou l’élément nul). Le pourcentage d’erreurs pour chaque catégorie a été calculé pour chaque apprenante, puis nous avons calculé la moyenne de groupe pour chaque type d’erreur.
5. Résultats
5.1. Résultats globaux pour les deux tâches
Le tableau 6 présente les scores globaux des onze apprenantes pour les deux tâches expérimentales. Les apprenantes ont mieux fait au test à trous qu’à la tâche de jugement de grammaticalité. Pour le groupe moins avancé, le score moyen pour le test à trous est de 70 % tandis que celui pour la tâche de jugement de grammaticalité n’est que de 39 %. On observe la même tendance chez les apprenantes plus avancées dont le score moyen est de 77 % pour le test à trous et 60 % pour la tâche de jugement de grammaticalité. Dans l’ensemble, les apprenantes ont mieux fait au test à trous qu’à la tâche de jugement de grammaticalité, la seule exception étant C04. De plus, les différences entre les scores de C01 et C02 sur les deux tâches sont minimes. Les résultats des deux tâches sont cohérents et il y a une corrélation modérée positive entre les scores des deux tests (r = 0.65). Les apprenantes ont mieux fait au test de production (le test à trous) qu’au test de compréhension (la tâche de jugement de grammaticalité). Il est probable que la tâche de jugement de grammaticalité a été plus difficile pour les apprenantes parce que la structure cible n’était pas saillante dans la phrase ; les apprenantes auraient donc porté leur attention sur le sens global de la phrase plutôt que sur la structure. Par conséquent, il est possible que les apprenantes ne se soient pas concentrées assez sur la structure en question et aient ainsi jugé les phrases avec une préposition incorrecte comme grammaticales.
Tableau 6
Pourcentage de bonnes réponses au test à trous et à la tâche de jugement de grammaticalité : apprenantes L2 anglophones moins et plus avancées

En plus des différences que l’on observe entre les deux tâches, il existe des différences évidentes entre les deux groupes. Pour le test à trous, la moyenne du groupe moins avancé est de 70 %, tandis que celle du groupe plus avancé est légèrement plus élevée (77 %). Les résultats des apprenantes plus avancées sont très homogènes, à l’exception de C04, tandis que ceux des apprenantes moins avancées le sont moins. En effet, l’étendue observée chez ce dernier groupe est de 59 %. En outre, trois des apprenantes moins avancées (C07, C08, C09) ont mieux fait que la majorité des apprenantes plus avancées au test à trous. Bien qu’il existe deux exceptions (C04 et C09), la plupart des participantes n’ont pas maîtrisé parfaitement le choix de préposition devant les CI – il n’y a eu aucun score supérieur à 92 % dans le test à trous. Elles ont toutes fait des erreurs : c’est le signe que cette construction verbale n’a pas été complètement acquise.
Pour la tâche de jugement de grammaticalité, la moyenne du groupe moins avancé est de 39 % tandis que celle du groupe plus avancé est de 60 %. Dans l’ensemble, les scores pour la tâche de jugement de grammaticalité sont très hétérogènes pour les deux groupes avec une étendue de 56 pour le groupe moins avancé et de 78 pour le groupe plus avancé. En général, les scores pour la tâche de jugement de grammaticalité sont très bas, ce qui suggère que les apprenantes n’ont pas acquis cette structure verbale.
Dans ce qui suit, nous examinerons les erreurs des apprenantes de façon plus détaillée.
5.2. Résultats du test à trous : analyse détaillée des erreurs
Afin d’évaluer si une des prépositions a été surgénéralisée, toutes les réponses incorrectes du test à trous ont été examinées. Les tableaux 7 et 8 exposent les types d’erreurs faites par chaque participante. Pour chacune, nous montrons la proportion relative des prépositions à, de et de l’élément nul incorrectement utilisés (%) dans le test à trous.
Premièrement, nous analyserons les résultats des apprenantes moins avancées. On constate dans le tableau 7 que, pour ces apprenantes, c’est la préposition de qui a été le plus souvent employée (taux d’emploi erroné : 44 %), suivie de à (28 %) et puis de l’élément nul (18 %). Deux des participantes moins avancées (C06, C11) ont inséré d’autres mots là où il aurait fallu mettre soit à, soit de, soit rien. La variété de mots utilisés suggère que ces deux apprenantes manquaient de familiarité avec les constructions à CI. On doit cependant distinguer entre C06 et C11 : tandis que C06 a utilisé d’autres mots huit fois (p. ex. un, que, pour, et, le), C11 n’a fait qu’une seule erreur de ce type (insertion de que).
Tableau 7
Analyse détaillée des erreurs : fréquence relative (%) des erreurs avec l’emploi des prépositions à, de ou l’élément nul pour le test à trous : apprenantes moins avancées

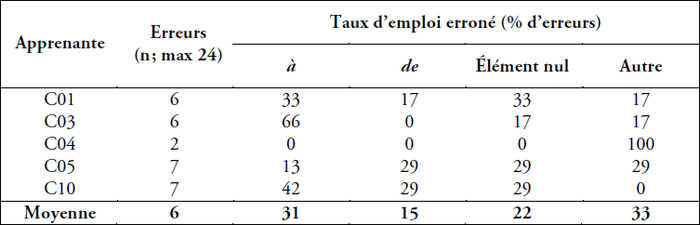
Quant aux apprenantes plus avancées, le tableau 8 montre que c’est à (taux d’emploi erroné : 31 %) qui a été le plus souvent mal employé. Après à, on constate un suremploi de l’élément nul chez ces participantes (taux d’emploi erroné : 22 %). Les participantes plus avancées ont utilisé la préposition de moins souvent dans des contextes illicites (taux d’emploi erroné : 15 %). Quatre des cinq apprenantes plus avancées ont utilisé d’autres mots, deux participantes ne les ont utilisés qu’une seule fois et les deux autres ne les ont utilisés que deux fois chacune. C04 et C05 ont utilisé la préposition pour deux fois chacune, C01 a utilisé pour une fois et C03 a utilisé la une seule fois. Le fait que l’utilisation d’autres mots est relativement rare laisse supposer qu’il existe une distinction entre ces apprenantes et C06 (l’apprenante moins avancée qui a utilisé d’autres mots huit fois) quant à leur maîtrise des constructions à CI. Ces apprenantes ont pu déterminer que les phrases en question comprenaient des CI et elles étaient conscientes du fait que soit à, soit de, soit l’élément nul devait intervenir entre le verbe matrice et l’infinitif. En revanche, C06 n’a pas pu déterminer qu’il s’agissait de constructions à CI et a plutôt choisi une variété des mots pour remplir les trous, ce qui a fini par créer des phrases agrammaticales.
Tableau 8
Analyse détaillée des erreurs : fréquence relative (%) des erreurs avec l’emploi des prépositions à, de ou l’élément nul pour le test à trous : apprenantes plus avancées
Pour terminer la discussion des tendances observées dans l’emploi erroné des prépositions devant les constructions à CI, nous examinerons les résultats de la tâche de jugement de grammaticalité.
5.3. Résultats de la tâche de jugement de grammaticalité : ianalyse détaillée des erreurs
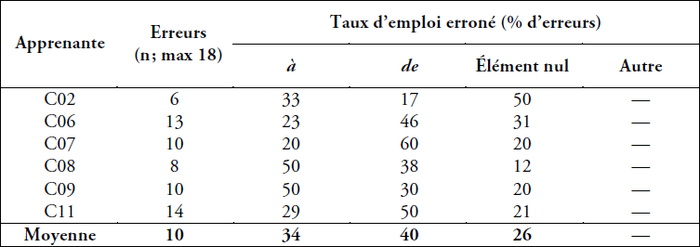
Dans l’analyse des erreurs présentée dans le tableau 9, on remarque que les apprenantes moins avancées ont souvent mal utilisé les prépositions de (taux d’emploi erroné de 40 %) et à (taux d’emploi erroné de 34 %). Elles ont utilisé l’élément nul de façon incorrecte moins souvent (taux d’emploi erroné de 26 %).
Tableau 9
Analyse détaillée des erreurs : fréquence relative (%) des erreurs relatives à l’emploi des prépositions à, de ou l’élément nul pour la tâche de jugement de grammaticalité : apprenantes moins avancées
Comme le montre le tableau 10, pour la tâche de jugement de grammaticalité, la tendance est pareille pour les deux groupes d’apprenantes. On voit que c’est de qui est utilisé incorrectement le plus souvent par les apprenantes plus avancées (taux d’emploi erroné : 35 %), suivi de à (taux d’emploi erroné : 30 %) et que l’élément nul a le plus bas taux d’utilisation incorrecte (taux d’emploi erroné : 15 %).
Tableau 10
Analyse détaillée des erreurs : fréquence relative (%) des erreurs relatives à l’emploi des prépositions à, de ou l’élément nul pour la tâche de jugement de grammaticalité : apprenantes plus avancées

En somme, dans la tâche de jugement de grammaticalité, les deux groupes ont utilisé à la fois à et de souvent dans des contextes agrammaticaux. Pour les apprenantes moins avancées, les deux tâches ont donné des résultats similaires, alors que pour les apprenantes plus avancées les résultats des deux tâches sont contradictoires en ce qui concerne l’utilisation erronée des prépositions a et de. Dans la section suivante, nous discuterons des implications de nos résultats.
6. Évaluation des hypothèses et conclusion
Dans cette dernière section, nous évaluerons les trois hypothèses présentées en §4.1. Ensuite, nous discuterons de l’importance relative de l’influence translinguistique, de l’input et de la surgénéralisation pour expliquer la performance des apprenantes ainsi que des problèmes méthodologiques et des études ultérieures éventuelles.
6.1. Évaluation des hypothèses
Selon la première hypothèse (H1), les apprenantes anglophones utiliseraient à, de et l’élément nul dans des contextes inappropriés. Cette hypothèse a été confirmée. Malgré le fait que tous les verbes utilisés figuraient parmi les verbes les plus fréquents du français, le taux moyen d’erreurs pour le test à trous était de 27 % (étendue de 8 à 67 %) et le taux moyen d’erreurs pour la tâche de jugement de grammaticalité était de 55 % (étendue de 0 à 89%).
Ensuite, la deuxième hypothèse (H2) postulait que les erreurs seraient moins fréquentes chez les apprenantes plus avancées, ce que les moyennes de groupe confirment partiellement. Comme l’indique le tableau 6, les scores des apprenantes plus avancées au test à trous (moyenne de 77 %) et pour la tâche de jugement de grammaticalité (moyenne de 60 %) étaient plus élevés que ceux des apprenantes moins avancées (moyenne du test à trous de 70 % ; moyenne de la tâche de jugement de grammaticalité de 39 %). Toutefois, c’est uniquement dans la tâche de jugement de grammaticalité que la différence entre les deux groupes est évidente. La différence entre les deux groupes dans le test à trous n’est pas considérable et n’est peut-être pas significative (77 % contre 70 %). Il est important de noter que lorsqu’on regarde chaque apprenante, la tendance est différente. On peut constater en se reportant au tableau 6 que les apprenantes C07, C08 et C09 du groupe moins avancé ont eu des scores plus élevés pour le test à trous que la plupart des apprenantes plus avancées.
Enfin, nous abordons la troisième et dernière hypothèse (H3). D’après la première partie de cette hypothèse (H3a), la préposition à serait surgénéralisée par les apprenantes moins avancées. Cela n’a été confirmé ni par les résultats du test à trous ni par ceux de la tâche de jugement de grammaticalité. D’après les résultats des deux tâches, les apprenantes moins avancées ont préféré la variante de. Leurs performances reflétaient ainsi l’input (fréquence plus élevée de la préposition de). Afin d’expliquer ces résultats, on doit considérer l’expérience linguistique des apprenantes. Toutes les apprenantes avaient entre 5 et 10 ans au début de l’acquisition et entre 19 et 22 ans au moment de l’étude (minimum de 9 ans d’apprentissage) ; elles avaient étudié le français au niveau universitaire et avaient passé entre 1 et 36 semaines dans un milieu francophone. Au fil des ans, elles auraient ainsi reçu une grande quantité d’input dans lequel la préposition de aurait précédé les CI le plus souvent.
La deuxième partie de la troisième hypothèse (H3b), selon laquelle de serait surgénéralisé par les apprenantes plus avancées, a été réfutée par la présente expérience. Selon les résultats du test à trous, c’est plutôt à qui a été le plus souvent incorrectement utilisé par les apprenantes plus avancées (31 %), suivi de l’élément nul (22 %) et de de (15 %). Selon les résultats pour la tâche de jugement de grammaticalité, les apprenantes plus avancées ont utilisé de le plus souvent (35 %), toutefois la différence entre l’utilisation incorrecte de de et de à (30 %) n’est sans doute pas réelle. Ces apprenantes ont utilisé l’élément nul incorrectement le moins souvent (15 %). À cause du fait que la différence entre l’utilisation incorrecte de de et de à est très petite (5 %), les résultats de la tâche de jugement de grammaticalité n’appuient pas cette hypothèse. Si l’input avait été déterminant chez ces apprenantes plus avancées, l’erreur la plus répandue n’aurait pas été celle concernant l’emploi de à. Il est difficile de déterminer la raison pour laquelle ces apprenantes plus avancées n’ont pas été plus influencées par l’input dans leur production des CI.
6.2. Conclusion
Dans l’ensemble, cette étude a confirmé que les constructions à CI représentent un problème persistant pour les apprenantes anglophones du français, y compris pour celles de niveau avancé. En effet, bien qu’une seule apprenante (C04) ait eu un score de 100 % pour la tâche de jugement de grammaticalité, de nombreuses apprenantes ayant un diplôme universitaire en linguistique ou en littérature françaises ou faisant une spécialisation en langue française ont été incapables de choisir correctement la préposition précédant le CI.
La surgénéralisation de de, préposition plus fréquente devant les CI en français, qu’on observe dans cette étude chez les apprenantes moins avancées souligne le rôle joué par l’input. Toutefois, les résultats des apprenantes plus avancées n’appuient pas le rôle de l’input ni de l’influence translinguistique. On observe en se reportant au test à trous que ces apprenantes ont le plus souvent incorrectement employé à et on ne constate pas de différence entre leur emploi erroné de à et de de dans la tâche de jugement de grammaticalité.
Cette expérience soulève un problème méthodologique que nous tenons à souligner ici, un problème qui pourrait expliquer le peu de recherche en ce qui a trait à l’acquisition L2 des CI. Comme nous l’avons mentionné plus haut, bien que le test à trous et la tâche de jugement de grammaticalité aient permis de recueillir des données sur les apprenantes de notre étude, les deux tâches sont très métalinguistiques et pourraient focaliser l’attention des apprenantes sur la structure cible. Ces tests, en particulier la tâche de jugement de grammaticalité, évaluent l’intuition grammaticale plutôt que la compétence linguistique. De plus, dans les tâches écrites, les apprenants ont le temps de réviser et de modifier leurs réponses. Une tâche de production orale est plus représentative de la compétence purement linguistique et ne permet pas aux apprenants de réviser leurs choix. Par conséquent, s’agissant d’une tâche de production orale, il est possible qu’on observe plus d’erreurs. Plusieurs tâches de production orale, par exemple une tâche de traduction, ont été envisagées, mais elles ont leurs propres inconvénients, y compris la possibilité que l’influence translinguistique soit plus importante et ainsi que les données soient moins représentatives. Bref, à l’avenir, des données spontanées seraient préférables. Les études ultérieures dans ce domaine devraient étudier la production spontanée des CI à l’aide de corpus. Cela permettrait d’accéder à une grande quantité de données authentiques produites par une variété de locuteurs. De plus, afin d’empêcher les apprenants d’éviter la structure en question (phénomène dont on suppose l’existence chez les apprenants dans Genc et coll. 2011), il faudrait des apprenants plus avancés. Nous suggérons que les apprenants moins avancés éviteraient les CI qu’ils ne connaissent pas.
Les résultats de cette étude révèlent que, même après des années d’apprentissage et après avoir reçu une quantité d’input importante, les apprenants L2 peuvent éprouver des difficultés avec des structures syntaxiques qui dépendent en partie des connaissances lexicales. En comprenant mieux l’interaction entre les systèmes lexicaux et verbaux, on contribuera ainsi aux modèles de l’acquisition des structures verbales complexes, y compris des variantes qui doivent être acquises lexicalement.
Parties annexes
Annexes
Annexe A
Tâche expérimentale : Test à trous
Nom : ________________________________________
Chacune des phrases suivantes comprend des trous. Lisez chaque phrase et décidez si elle est complète. Là où nécessaire, ajoutez les éléments appropriés.
Il faut ___ jouer pour gagner.
Vous risquez ___ vous perdre si vous ne suivez pas mes directives attentivement.
David Copperfield a fait ___ disparaitre la Statue de la Liberté.
Il tient ___ remercier tous ceux qui ont envoyé des communications.
Vous proposez ___ partager gratuitement votre savoir-faire, mais pourquoi ?
Voici un homme en difficulté ; il faut ___ aider.
Le bruit m’empêche ___ dormir.
Je vais parler à mon épouse et je vais ___ demander pourquoi elle est en colère contre moi.
Entrepreneurs, vous cherchez ___ financer votre projet ?
J’ai vu ___ passer trois personnes.
Elles refusent ___ vendre leur maison.
Vous avez appris ___ gérer votre emploi du temps pour avoir plus de temps pour vous reposer ?
Je vais ___ voir le film.
Il a réussi ___ faire un résumé de l’article.
Veux-tu que je t’aide ___ faire ton travail ?
J’ai un téléviseur, mais je ne ___ regarde jamais.
Il tient ___ remercier tous ceux qui ont envoyé des communications.
Ils se préparent ___ partir en vacances.
Pourquoi les responsables de YouTube ont-ils cessé ___ rémunérer les clips en France ?
Ils ont ___ garçon et ___ fille.
Elle pourrait ___ abandonner Hollywood pour être maman à plein temps !
J’ai perdu mon sac. Je ___ cherche.
Voici ___ plus belle ville du monde.
Nous travaillons ___ régler le problème.
J’aime ___ soupe et ___ salade.
Ce petit enfant est très gentil avec sa mère ; il ___ obéit toujours.
Je crois ___ avoir trouvé la bonne réponse.
___ silence est d’or.
Nous essayons ___ trouver un compromis.
Elle a dit ___ nous assoir.
Voilà, la spiritualité, elle sert ___ nous relier à notre essence, qui est en quelque sorte “infinie”, sans limite.
Il y a ___ enfants dans le parc.
Kim Kardashian et Kanye West veulent ___ appeler leur fils “North”.
Vous devez ___ lui demander si vous pouvez venir à sa fête.
Annexe B
Stimuli pour la tâche de jugement de grammaticalité
Tableau B.1
Phrases cibles pour la tâche de jugement de grammaticalité

Note : Le à, de ou l’élément nul sont soulignés ici pour mettre l’accent sur l’élément qui détermine la grammaticalité de la phrase. Dans la tâche de jugement de grammaticalité, ces mots n’étaient pas soulignés.
La fréquence (Lonsdale et Le Bras, 2009) est relative et basée sur un corpus
Tableau B.2
Distracteurs pour la tâche de jugement de grammaticalité

Note : Les mots soulignés ou les trous dans les phrases agrammaticales sont les sources de l’agrammaticalité.
Annexe C
Tâche expérimentale : Tâche de jugement de grammaticalité
Nom : ________________________________________
Après avoir lu chacune des phrases suivantes, indiquez si elle est bien écrite ou non. Là où vous remarquez des problèmes, apportez les corrections nécessaires.
Beaucoup de gens ont du talent, mais seul le travail permet faire une carrière.
Ils permettent à l’enfant à jouer avec ses amis.
Il dit qu’il espère à aller à l’Université de Toronto parce qu’il aime la ville.
Il est absolument défendu de marcher sur les pelouses des jardins publics.
Il n’aimes pas le café ; il préfère le thé.
Il n’arrive pas de faire le travail que son professeur lui a demandé.
Vous ne semblez pas apprécier mes efforts.
Voici le livre que nous employons.
Alex espère de venir demain s’il a le temps.
Née sans langue, une jeune femme arrive parler grâce à un traitement mis au point par des médecins brésiliens.
Saint-Laurent est un fleuve majestueux.
Sa femme est le seul être vivant qu’il semble à aimer sincèrement.
Elle espère apprendre le français parce qu’elle veut aller en France.
Elle a acheté une robe et un manteau.
L’ennui conduit à faire davantage d’erreurs, accroit le stress et provoque des accidents.
Mon docteur m’a dit que je suis très malade.
Vous semblez de faire des progrès.
C’est une crainte de la solitude qui nous conduit penser comme les autres.
Les printemps est agréable, mais l’hiver est froid.
La rédaction d’une bonne thèse n’est pas facile.
Je t’avais défendu à marcher nu-pieds.
Il est défendu parler cette langue.
J’arrive à faire jouer la vidéo mais le son ne fonctionne pas.
Permettez-moi de parler puisque j’ai quelque chose d’important à vous dire.
J’étudie français.
Pour quelles raisons l’État est-il conduit de corriger les inefficacités du marché ?
Annexe D
Tableau de fréquence des verbes utilisés dans le test à trous
Tableau D.1
Fréquence des verbes employés dans les stimuli du test à trous selon Lonsdale et Le Bras (2009)

Annexe E
Stimuli pour le test à trous
Tableau E.1
Phrases cibles pour le test à trous

Note : Le blanc représente le trou que l’apprenante était tenue de remplir.
Tableau E.2
Distracteurs (déterminants et pronoms objets) pour le test à trous

Note : Les mots soulignés étaient remplacés par des blancs dans le test à trous.
Note biographique
Caitlin Gaffney est candidate au doctorat au Département d’études françaises de l’Université de Toronto. Elle se spécialise en acquisition des langues secondes et s’intéresse à l’acquisition de la syntaxe et de la phonologie françaises, principalement chez les apprenants anglophones. Elle s’intéresse également au rôle des différences individuelles dans l’apprentissage des langues. Sa thèse de doctorat porte sur le rôle des traits de personnalité et de l’intelligence dans le développement de la fluidité chez les apprenants anglophones L2.
Notes
-
[1]
L’emploi de la forme féminine (les « apprenantes ») est justifié par le fait que les participants à notre expérience étaient exclusivement des femmes.
-
[2]
La préposition qui introduit un CI a varié au cours de l’histoire. De plus, le sens de certains verbes à l’infinitif change selon la préposition qui les accompagne. Par exemple, demander de veut dire ordonner ou commander (Je vous demande de me répondre), tandis que demander à signifie avoir envie de ou vouloir (Il a demandé à parler devant l’assistance ; Ollivier et Beaudoin, 2008 : 327).
-
[3]
Cette étude a porté spécifiquement sur le sous-corpus de Salford (Hawkins, Towell et Bazergui 2006). Les données de ce corpus ont été recueillies pour une étude longitudinale de douze apprenants universitaires de premier cycle (L1 anglais), de leur première à leur quatrième année d’université. Tous les apprenants faisaient une licence qui comprenait un séjour de six mois en France. Plusieurs tâches ont été administrées au cours du projet ; Gaffney (2014) a examiné les données de la tâche General chat (discussion générale avec le chercheur).
-
[4]
Les verbes sont présentés ici par ordre de fréquence décroissante.
-
[5]
Les consignes suivantes ont été fournies aux participantes : « Please look at these words. Some of these words are real French words and some are invented but are made to look like real words. Please tick the words that you know or can use ».
-
[6]
« Chacune des phrases suivantes comprend des trous. Lisez chaque phrase et décidez si elle est complète. Là où c’est nécessaire, ajoutez les éléments appropriés ».
-
[7]
Nous avons présenté les consignes suivantes aux participantes : « Après avoir lu chacune des phrases suivantes, indiquez si elle est bien écrite ou non. Là où vous remarquez des problèmes, apportez les corrections nécessaires ».
-
[8]
Les mots du dictionnaire viennent d’un corpus de 23 000 000 mots français qui ont été rassemblés à partir d’une grande variété de sources. La moitié des mots vient de corpus oraux, l’autre moitié de textes écrits. Le corpus oral du dictionnaire est constitué de divers genres tels des appels téléphoniques et des entrevues. Les textes écrits comprennent, entre autres, des articles de presse et de revue et des textes littéraires. Aucun texte ne date d’une époque antérieure aux années 1950 (Lonsdale et Le Bras 2009 : 2).
Bibliographie
- Adjemian, C. 1983. “The Transferability of Lexical Properties”. Dans Language Transfer in Language Learning, sous la direction de S. Gass et L. Selinker. Rowley : Newbury House : 250-268.
- Bartning, I. 2000. “Gender Agreement in L2 French : Pre-Advanced vs Advanced Learners”. Studia linguistica 54 (2) : 225-237.
- Cox, T. 1983. “Teaching the Unteachable: Prepositional Complementizers in French”. The French Review 57 (2) : 168-178.
- De Groot, A. M. B., et Keijzer, R. 2000. “What Is Hard to Learn Is Easy to Forget: The Roles of Word Concreteness, Cognate Status, and Word Frequency in Foreign Language Vocabulary Learning and Forgetting”. Language Learning 50 : 1-56.
- Gaffney, C. 2014. L’acquisition L2 des compléments infinitifs français chez les apprenants anglophones en parole spontanée. Mémoire de maîtrise, Université de Toronto.
- Gass, S., et L. Selinker. 2008. Second Language Acquisition: An Introductory Course, 3e éd. New York : Routledge.
- Genc, B., M. Mavasoglu et E. Bada. 2011. “Pausing Preceding and Following à/de in Infinitive Phrases in the Production of Native and Non-Native Speakers of French”. Arizona Working Papers in Second Language Acquisition and Teaching 18 : 1-11.
- Haase, A. 1898. Syntaxe française du XVIIe siècle. Traduit par M. Obert. Paris : Alphonse Picard et Fils. [document électronique de la Bibliothèque nationale de France, 1995] Consulté le 20 juillet 2013.
- Hawkins, R., Towell, R., et Bazergui, N. 2006. The Salford Corpus. Consulté le 5 mai 2014 de http://www.flloc.soton.ac.uk/salford.html.
- Huot, H. 1981. Constructions infinitives du français. Le subordonnant de. Paris-Genève : Droz.
- Kalmbach, J. 2008. « Intégrer les marqueurs d’infinitifs dans la grammaire française ». Synergies pays scandinaves 3 : 63-74.
- Kirjavainen, M., A. Theakston, E. Lieven et M. Tomasello. 2009. “ ‘I Want Hold Postman Pat’ : An Investigation into the Acquisition of Infinitival Marker ‘to’ ”. First Language 29 (3) : 313-339.
- Lonsdale, D., et Y. Le Bras. 2009. Routledge Frequency Dictionary of French: Core Vocabulary for Learners. London : Routledge.
- Leung, Y. 2006. “Verb Morphology in L2A vs L3A : The Representation of Regular and Irregular Past Participles in English-Spanish and Chinese-English-Spanish Interlanguages”. Dans EUROSLA Yearbook 6, sous la direction de S. Foster Cohen, M. Krajnovic, et J. Djigunovic. Amsterdam : John Benjamins : 27-56.
- Major, R. C. 2001. Foreign Accent: The Ontogeny and Phylogeny of Second Language Phonology. Mahwah, NJ : Lawrence Erlbaum.
- Meara, P. et J. Milton. 2003. X_Lex, the Swansea Levels Test. Newbury : Express.
- Myles, F., et R. Mitchell, R. 2007. French Learner Language Oral Corpora (FLLOC). Université de Southampton.
- Odlin, T. 2003. “Crosslinguistic Influence”. Dans Handbook of Second Language Acquisition, sous la direction de C. Doughty et M. Long. Oxford : Blackwell : 436-486.
- Ollivier, J. et M. Beaudoin. 2008. Grammaire française. 4e éd. Toronto : Nelson Education.
- Read, J. 2000. Assessing Vocabulary. Cambridge : Cambridge University Press.
- Selinker, L. 1972. “Interlanguage”. International Review of Applied Linguistics 10 : 209-241.
- Skayem, H. 2004. « Les infinitifs compléments d’un autre verbe ». Dans Espace français. Consulté le 12 février 2013 de http://www.espacefrancais.com.
- Taylor, B. 1975. “The Use of Overgeneralization and Transfer Learning Strategies by Elementary and Intermediate Students of ESL”. Language Learning 25 (1) : 73-107.
- Towell, R. et R. Hawkins. 1994. Approaches to Second Language Acquisition. Clevedon : Multilingual Matters.
- Urbaniak, G. et S. Plous. 2011. Research Randomizer (Version 3.0) [Logiciel]. Consulté le 3 avril 2013 de http://www.randomizer.org.
Liste des tableaux
Tableau 1
Exemples de verbes matrices fréquents à compléments infinitifs introduits par à, par de, par les deux prépositions ou par un élément nul
Tableau 2
Expérience linguistique des apprenantes anglophones moins avancées et plus avancées selon leurs réponses au questionnaire sur leurs antécédents linguistiques
Tableau 3
Compétence en français des apprenantes anglophones d’après les scores ajustés sur le test X_Lex2 (maximum de 5000)
Tableau 4
Résumé des stimuli (phrases cibles et distractrices) pour le test à trous
Tableau 5
Stimuli (phrases cibles et distractrices) pour la tâche de jugement de grammaticalité linguistiques
Tableau 6
Pourcentage de bonnes réponses au test à trous et à la tâche de jugement de grammaticalité : apprenantes L2 anglophones moins et plus avancées
Tableau 7
Analyse détaillée des erreurs : fréquence relative (%) des erreurs avec l’emploi des prépositions à, de ou l’élément nul pour le test à trous : apprenantes moins avancées
Tableau 8
Analyse détaillée des erreurs : fréquence relative (%) des erreurs avec l’emploi des prépositions à, de ou l’élément nul pour le test à trous : apprenantes plus avancées
Tableau 9
Analyse détaillée des erreurs : fréquence relative (%) des erreurs relatives à l’emploi des prépositions à, de ou l’élément nul pour la tâche de jugement de grammaticalité : apprenantes moins avancées
Tableau 10
Analyse détaillée des erreurs : fréquence relative (%) des erreurs relatives à l’emploi des prépositions à, de ou l’élément nul pour la tâche de jugement de grammaticalité : apprenantes plus avancées
Tableau B.1
Phrases cibles pour la tâche de jugement de grammaticalité
Note : Le à, de ou l’élément nul sont soulignés ici pour mettre l’accent sur l’élément qui détermine la grammaticalité de la phrase. Dans la tâche de jugement de grammaticalité, ces mots n’étaient pas soulignés.
La fréquence (Lonsdale et Le Bras, 2009) est relative et basée sur un corpus
Tableau B.2
Distracteurs pour la tâche de jugement de grammaticalité
Note : Les mots soulignés ou les trous dans les phrases agrammaticales sont les sources de l’agrammaticalité.
Tableau D.1
Fréquence des verbes employés dans les stimuli du test à trous selon Lonsdale et Le Bras (2009)