Résumés
Abstract
This article examines real-time simultaneous interpretation (SI) and delayed SI, recorded speeches broadcast on TV through SI. The results showed that interpreters’ factors in two modes of SI had a high correlation thus showing that interpreters use a similar strategy when the speakers’ variables are identical. As expected, the quality of delayed SI was higher than that of live SI due to longer pauses, EVS and Korean sentences in live SI than those of delayed SI. Thus it was found that the quality of incoming sentences deteriorates when interpreters spend more time than allowed on a sentence. Interpreters in delayed SI, thanks to their strong sense of anticipation, produced a high quality SI by following the proper strategy. This implies that securing scripts in advance or obtaining a detailed outline by the interpreter is key to ensuring a quality SI.
Keywords/Mots-clés:
- simultaneous interpretation,
- Korean,
- delayed SI,
- accuracy,
- EVS
Résumé
Dans cette étude, nous avons comparé les résultats de l’interprétation simultanée d’une émission télévisée en direct et de l’interprétation simultanée de la même émission enregistrée. Les résultats ont montré une haute corrélation parmi divers facteurs et nous avons constaté que les interprètes des deux groupes utilisaient des stratégies analogues sur un discours source identique. Comme nous pouvions nous y attendre, l’exactitude de l’interprétation simultanée à partir d’un enregistrement était supérieure à celle de l’interprétation simultanée en direct, la raison étant que les pauses, le décalage entre le discours source et le discours cible (EVS) et la longueur des phrases coréennes de la première étaient plus longues que celles de la deuxième. Nous pouvons ainsi constater que, lorsqu’un interprète passe un temps excessif sur une phrase, l’exactitude de la phrase suivante est moindre. Dans l’interprétation simultanée à partir d’un enregistrement, les interprètes ont utilisé des stratégies adéquates avec beaucoup d’anticipation, ce qui a résulté en une haute exactitude. Cela démontre qu’il est important que l’interprète se procure le discours source ou qu’il s’assure de ses grandes lignes avant de procéder à l’interprétation afin d’augmenter la qualité de l’interprétation simultanée.
초록
이 논문은 TV 방송에서 원문을 생 동시통역한 것과 녹화 동시통역한 것을 비교 분석하였다. 그 결과 둘은 여러 변수에서 높은 상관관계를 보여 원문 변수가 동일할 경우 두 그룹의 통역사들은 유사한 전략을 사용한다는 점이 밝혀졌다. 그리고 예상대로 녹화 동시통역의 정확도가 생 동시통역보다 높았다. 그 이유로는 생 동시통역이 녹화 동시통역보다 통역 중 휴지를 길게 남겼으며 이에 따라 EVS가 길어졌고 이것은 또 해당 문장의 길이가 늘어나는 것으로 이어졌다. 이처럼 통역사가 한 문장에 지나치게 오래 집착할 경우 다음 문장의 정확도가 떨어진다는 것이다. 반면 녹화 동시통역 또는 원고가 미리 주어지는 동시통역의 경우에는 통역사의 강한 예측에 힘입어 적절한 전략을 사용함으로써 높은 정확도를 보여 앞으로 동시통역 교육에 중요한 시사점을 안겨준다고 보겠다.
Corps de l’article
I. Introduction
When professional conference interpreters make preparations for international conferences the final stage is meeting their speakers. Though interpreters may have an outline of the speeches they are about to simultaneously interpret, they desperately need the content in detail. As Jones (1998) pointed out, interpreters, at macro level, do not know where the speech as a whole is headed; at micro level, interpreters do not know whether an individual sentence will be in positive or negative form. Therefore, if interpreters can ask their speakers to deliver the full speech before the conference or they can get the full text in advance, the quality of the simultaneous interpretation for that speech would be significantly enhanced. This is because the more shared information on the part of interpreters with speakers, the higher the quality of the segment. Listening to the whole speech before actual SI, however, rarely happens in real situations.
In this context, this paper will analyze two sets of SI for TV broadcasting. One set was a live SI coverage on TV and the other set was SI for the same speeches broadcast a few hours later. The principle aim is to try to find the difference in the pattern of information processing in the two modes. If any significant difference is found, it can be utilized for interpreters’ education.
II. Materials and Procedures
Seven audiotapes of English speeches and seven pairs of Korean SI were chosen for this study. One set of SI was for live coverage on TV and the other set was SI for the same original speeches which were re-broadcast a few hours after the live coverage on the same TV channel. Each SI lasted approximately 4 to 5 minutes and a total of 21 samples were analyzed. Speakers were a US president and military officers and the SI was carried out by professional conference interpreters who received formal conference interpretation training. Since it is very difficult to access naturalistic data, this SI that was broadcast on TV is an exception (Gile 2000, 2001).
The audio of the original English speeches and SI were saved in a personal computer equipped with voice-editing software that can measure up to 1 millisecond. Transcripts of the English speeches were obtained from the Internet and Korean SI was transcribed using the files in the computer. Speakers’ (S) and interpreters’ (I) temporal aspects in each sample were measured by playing back the actual voice from the computer. The length of each pause was measured and it was marked on the original and interpretation script. Measured factors include the number of syllables of English speech and SI, speaking time, speech proportion (SP, a ratio that speaking time occupies within the total time of SI), between-sentence pause, in-sentence pause, EVS (ear-voice-span), EVS/the length of sentence. Interpreted Korean sentences were compared with the original English sentence one by one to check accuracy based on word correspondence and meaning. Since Pöchhacker (2004) noted that “cognitive information processing skills is clearly the most widespread meme in interpreting studies to date,” the above mentioned analysis on the temporal aspects of the SI modes will reveal many unknown facts about “cognitive information skills during SI.”
III. Simultaneous Interpretation and Delayed Simultaneous Interpretation
The term “simultaneous interpretation” contains simultaneity as one of the most important qualities of this human information processing. There is, however, another form of SI, that can be called delayed SI. As mentioned earlier, this refers to the kind of SI that takes place after the original speech has been aired once. We can see this kind of SI usually on TV when major speeches are re-broadcast with SI. In this situation, interpreters are given a certain advantage that interpreters for real-time or live SI cannot hope for. Although this form of SI is not widely used, the situation is similar to one where interpreters receive scripts they are going to interpret simultaneously in advance. There was a case where an examination in SI on a technical speech was carried out this way (Sawyer 2004).
One of the most important characteristics of SI is that conference interpreters should distribute limited information processing capacity to all modules constituting SI. As Gile (1995) pointed out, interpreters’ mental energy is only available in limited supply and if interpretation requires more than is available, the quality of that part will deteriorate. Interpreters engaging in English (B language) into Korean (A language), however, experience unique difficulties that cannot be found in A to B SI. Since interpreters are listening to a foreign language, their short-term memory and linguistic rules in long-term memory will be weaker than that of native speakers (Call 1985; Griffith 1990). In this regard, Weber (1990) used the term “absorption threshold” and argued that this may be higher if interpreters are listening to their native language and lower when listening to a foreign language. When we apply these on delayed SI, the “absorption threshold” for interpreters of the delayed SI group would be higher than that of the live SI group.
Besides the problem of listening, Korean conference interpreters must store a large amount of information for some time before reproducing it due to syntactic difference between Korean (SOV) and English (SVO). Human raw memory for a string of words, however, is not large enough to accommodate the SI task (MacWhinney 1997). In this context, interpreters will have to sacrifice the quality of a certain sentence if they cannot make use of an optimal strategy to handle the incoming messages. Here, again, interpreters in delayed SI mode could be free from this restraint thanks to their strong sense of anticipation.
Another difficulty facing these interpreters is finding target language equivalents. As Garman (1990) pointed out, items in larger word classes are less easily accessed, academic and formal expressions would not be retrieved as quickly as expressions in daily use, so interpreters should spend some of their energy on this task. Concerning equivalents, interpreters in delayed SI would be able to come up with appropriate expressions quickly since they already listened to the whole speech and may even have written down some difficult words in the target language.
Unlike reading or translation processes where people can stop reading and go back for understanding purposes, interpreters cannot control the rate of incoming original speech during SI. In such situations, interpreters mobilize their background knowledge to anticipate what the speaker is going to say and due to this anticipation, interpreters can utter their TL before the end of the incoming sentence. Concerning anticipation, as was shown, the extent to which interpreters can anticipate would be different in live SI and delayed SI. Interpreters in delayed mode have already listened to the whole speech and knew where the speech is headed.
Therefore, it can be assumed that the anticipation of interpreters in delayed SI is strong and their access to Korean equivalents will be fast by spending a little processing capacity. Sometimes their anticipation will be even stronger than for those interpreters doing consecutive interpretation. In consecutive interpretation, interpreters interpret after listening to a certain amount of speech and they don’t know the ultimate path of the speech. Interpreters in delayed SI, on the contrary, know the whole story and do not have to spend a lot of their processing capacity in understanding incoming messages. Interpreters in the live SI group, on the other hand, would have difficulties in that they lack the advantages enjoyed by the delayed group had. To make the situation worse, the interpreters considered in this paper were in a more vulnerable situation than interpreters in everyday SI because they could not meet the speakers beforehad. Instead of receiving an outline from the speakers in advance, all they could do was collect related information on the Internet and read news articles on the subject. This would make the processing of SI in the two modes very different in terms of their time and crisis management.
IV. Result
4.1 Correlations between S and I variables
Table 1
Correlations between S syllable and I variables

* p<0.05
** p<0.01
Live SI and delayed SI in Table 1 show surprisingly similar correlation with S syllables. This result exactly matches the study of Lee (2004), which analyzed paired Korean live SI. In some cases, some I variables had positive correlations with S variables while they showed a unanimously negative correlation in other cases. This can be attributable to the fact that interpreters are inevitably dependent on speaker variables. As Gile (1995) pointed out, interpreters have to follow the path chosen by the source-language speaker and they are not “free to speak their own mind, and therefore to bypass possible production difficulties by rearranging the sequence of information and ideas or by dropping or modifying some of these.”
In the case of interpreters’ syllables (IS) and interpreters’ speaking time (IT), interpreters show positive correlation with speakers’ syllables (SS). This means that interpreters in both modes increase or decrease the length of their sentence proportional to the length of the English sentence. The reason behind this would be that interpreters, whether they were engaged in real time SI or delayed SI, could not work on a sentence for an unlimited period of time due to constraints in memory load and the incoming flow of sentences.
Table 2
Correlations between ST and I variables

* p<0.05
** p<0.01
The variable speakers’ speaking time (ST) examined in Table 2 is more temporal than SS in Table 1 and the correlation coefficient in Table 2 is higher than SS. This again illustrates the dependence of the interpreted version on the original speech. Furthermore, the correlation coefficients of delayed SI are higher than live SI. It can be assumed that interpreters in delayed SI follow the temporal path of the original speaker more closely than interpreters live SI do.
Table 3
Correlations between S in-sentence and I variables
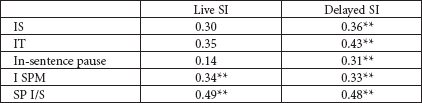
* p<0.05
** p<0.01
While all variables in delayed SI in Table 3 reveal statistically significant correlations with S variables, only two variables in live SI showed correlations. This means that interpreters in delayed SI controlled the volume of their IS, IT and in-sentence pause proportional to the speakers’ variables while interpreters in live SI failed to do that. Long S in-sentence pause implies the ST gets longer and, in turn, interpreters' speaking time in delayed SI followed the same path. Following this pattern, the in-sentence pauses in delayed SI seemed to have been longer.
Table 4
Correlations between SSPM and I variables

* p<0.05
** p<0.01
As is the case with other variables, speakers’ syllables per minute (SSPM) in Table 4 also shows that delayed SI had more stable correlations with S variables than live SI did. Out of nine variables, delayed SI came up with eight statistically significant correlations while live SI produced only three. This might imply that interpreters for delayed SI, who already listened to the original speech once or several times, had a stronger anticipation than those interpreters for live SI. Therefore, interpreters in delayed SI could maintain constant relations with S variables.
To summarize this section, delayed SI showed strong correlations with S variables while live SI revealed weaker or no correlations. This may be attributable to the fact that interpreters in delayed SI mode process the incoming message in a more stable way than those in the live group do.
4.2 Comparison of live and delayed SI
Among a group of I variables examined in this paper, a certain variable is fixed first by the interpreter prior to other variables. The first variable is the interpreter’s between-sentence pause which means the silence between one Korean sentence and the following sentence. After this, in-sentence pauses are made which directly influence the length of EVS of the sentence. Speech proportion comes next and the number of I syllables or speaking time is the result of these factors. All these variables combined finally determine the accuracy of the sentence in question.
Out of 136 original sentences, 89 sentences (65.5%) were interpreted in live SI while 107 sentences (78.7%) were interpreted in delayed SI. The number of original sentences interpreted by both modes was 73. This finding is in line with Lambert, Daro and Fabbro (1995) who found that omission was the most frequently occurring error.
Table 5
Accuracy

(%)
As was expected, the accuracy of delayed SI in Table 5 was much higher than that of live SI. Most delayed SI showed an average accuracy of 80% or above and sample 5, in particular, missed no single sentence and showed 100% accuracy. Statistical treatment revealed that accuracy of live SI (73.7%) was statistically lower than that of delayed SI (p=0.001). This clearly demonstrates that interpreters for delayed SI enjoyed many advantages over interpreters for live SI.
Table 6
Interpreters’ between-sentence pause

(%)
Between-sentence pause is an absolute silence in which interpreters stop rendering their converted message. It means that audiences hear nothing from the interpreters’ booth. In the case of live SI, it occupied 29.3% of the interpreters’ speaking time and 30.7% on delayed SI.
Concerning this pause, Jones (1998) argued that “if a speaker begins and the interpreter says absolutely nothing, be it only for a few seconds, because they are waiting for the right moment to begin their interpretation, the participants listening to the interpreters may become very nervous, turn round and make signs at the interpreters’ booth.” Although the average length of between-sentence pause in two groups was not statistically different, the pair of 73 sentences which were interpreted by both groups revealed that the between-sentence pause of live SI (1.55 sec) is statistically longer than delayed SI (1.18sec p= 0.05). This means that interpreters in live SI begin their utterance later than those for delayed SI possibly due to their overloaded information processing. Undoubtedly, interpreters in live SI are certainly aware that pauses in their SI give a negative impression to an audience listening to the SI. In this situation, the longer pauses by interpreters in live SI mean that they are facing unavoidable obstacles in their information processing. These lengthened pauses, in turn, will directly influence the length of EVS.
Table 7
Interpreters’ in-sentence pause

(%)
As is the case with between-sentence pauses, live SI's in-sentence pauses were longer than those of delayed SI. At sample level, in-sentence pause in the live SI group occupied 9.74% of the total speaking time, while delayed SI reached 4.66% (p= 0.049). This again demonstrates that interpreters in live SI mode seem to have more difficulty in processing incoming messages than interpreters in delayed SI do. When we remember Weller’s (1991) argument that understanding the original message is the most difficult part, poor comprehension in this stage will directly influence the quality of the SI.
The fact that the pair of 73 sentences had high correlations (r=0.55, p<0.01) means two groups of interpreters share similar processing strategy and both of them are dependent on speakers. As the between-sentence pauses influence the length of EVS, this in-sentence pause will affect SP of the sentence.
Table 8
EVS

(sec)
EVS, the time between certain segments of the speaker was perceived to the interpreter and the time the interpreter produces his interpreted version, is one of the few observable and quantifiable variables in SI study. For that reason, this is one of the most outstanding variables for interpreters' time management during SI. During this short EVS, interpreters carry out concurrent processing of comprehending, converting, planning and uttering TL. The nature of EVS can be said to be the minimum time for processing on the part of the interpreter. That is why EVS can be one of the most noticeable results of an interpreter's strategy.
EVS of live SI at sample level (3.14 sec) was statistically longer than that of delayed SI (1.34 sec, p=0.002). At sentence level, the pattern was similar in that live SI revealed EVS of 3.23 sec while the delayed group showed 1.28 sec (p=0.000). In this context, longer EVS in live SI at both sample level and sentence level demonstrates the difficulty in processing including poor anticipation. In the case of live SI, interpreters wait some time before beginning their interpretation. Delayed SI, on the other hand, their EVS was much shorter than live SI and was shorter than the EVS in other studies of English into Korean SI (Lee 2002). In the case of Sample 4, the interpreter started uttering TL even before the beginning of the original sentence. This might reveal that the interpreter in question had no difficulty in comprehending and finding Korean expression as he knew the direction of the original speech.
Table 9
EVS/sentence ratio

(%)
EVS/sentence ratio is a more accurate variable than mere EVS since the former reveals relative length of EVS vis-à-vis the length of each sentence. When EVS/sentence is 1, the interpreter begins to produce converted information after listening to the speaker’s entire sentence. The interpreter would begin half of the original sentence when the figure is 0.5. Table 9 highlights that sample level EVS/sentence ratio of interpreters for live SI was 1.01 while three out of seven interpreters began their interpretation after the end of the incoming original sentence. In delayed SI, on the other hand, the average EVS/sentence was 0.52 which means that interpreters started producing converted messages at nearly half of the original sentence.
This result may also be attributable to the fact that delayed interpreters could have a strong sense of anticipation while live interpreters do not. In this regard, Lambart, Daro and Fabbro (1995) argued that “when dealing with difficult texts to be translated from L2 into L1, they (interpreters) should preferably focalize their attention on input.” When interpreters spend too much time and capacity on one sentence, EVS for the next sentence will be extremely lengthened and in some cases, the sentence might be omitted in SI.
Therefore, it can be said that longer EVS and EVS/sentence are clearly responsible for the poor quality of live SI. This is in line with the result of Barik (1973) who argued that the interpreter performs better if he does not lag too far behind the speaker. Lee (2002) who examined EVS and quality in English into Korean SI also came up with the same result.
Table 10
Speech proportion

(%)
Sentence level speech proportion highlights a clear comparison between two modes. Delayed SI shows very high sentence SP (96.9%), even sometimes 100%, while live SI shows lower SP (90.0%, p=0.003). Part of this result is the great in-sentence pause in the case of live SI. As interpreters stop uttering the interpreted version in the case of live SI, their SP will be naturally lowered. They might have difficulty in one of the phases involved in SI. Lowering SP or suspending uttering of converted versions from English into Korean SI seems quite a common phenomenon. Interpreters, intuitively, try to reduce the portion of multi-processing, which is listening and speaking at the same time.
Table 11
Sentence level syllable I/S ratio

(%)
Table 11 compared each samples’ average number of syllables of the sentences in interpretation vis-à-vis original sentences in live and delayed SI. When Syl I/S ratio is 100%, interpreter and speaker are supposed to produce the same number of syllables. When the ratio is 200%, it means the interpreter uttered twice as many syllables as the speaker did. The interpreter would have spoken half of the number of the speaker when this ratio is 50%. In this context, Table 11 highlights that both modes of SI used more syllables than the original English sentences (164% in live SI, 153% in delayed SI). This demonstrates the expansion of syllable in an interpreted Korean version and implies that more syllables are needed to produce perfect SI from English into Korean which is physically impossible. Contrary to expectation, t-test demonstrates no significant difference of IS between the two groups and no correlations were found either.
Table 12
Sample level syllable I/S ratio

(%)
Table 12 shows syllable I/S ratio at sample level. Compared with the sentence level syllable I/S ratio in Table 11, the sample level syllable I/S ratio was much lower (107% in live SI, 119 in delayed SI). This can be attributable to the fact that both groups omitted a certain number of original sentences in their SI. Although there was no significant difference between the two groups, high correlations (r=0.79, p<0.05) might mean that interpreters in two modes did their best to utter as many syllables as possible under the given conditions.
With regard to interpreters’ speaking time, a t-test was run to see if there is any difference between the lengths of the interpreters’ speaking time in two modes. The average length of the pair of 73 sentences in live SI (4.08 sec) was statistically longer than that of delayed SI (3.27 sec, p=0.009). This means interpreters in live mode stuck to one sentence longer than interpreters in delayed mode did. If an interpreter tries to stick to one sentence for a longer period of time than allowed, he may successfully interpret the segment, but he does it at the peril of the next sentence. This might be partly responsible for the low quality of live SI in this paper. The fact that the pair of 73 sentences showed some correlations (r=0.395, p<0.001) suggests interpreters in the two modes maintained a similar portion of increase or decrease of their target sentences. This may be due to the fact that they are under the same speaker condition.
Table 13
Sentence level IT I/S ratio

(%)
Interpreter speaking time I/S ratio, at sample level, reaffirms the above-mentioned point. Although it was not strategically significant, interpreters in live mode spoke longer (156%) than those in the delayed mode (103 %, p=0.067). Interpreters under the delayed SI mode kept the length of their Korean sentence as long as that of original, while live mode showed some 156% longer than the original English sentence. When we examined this ratio of the pair of 73 sentences which were interpreted by both modes, IT I/S ratio in live mode was 132%, and delayed mode was 98% but it was not statistically significant.
Table 14
SPM

(words per minute)
T-tests reveal that SPM of the two groups was not statistically different at sample level (375: 426). Sentence level SPM, however, revealed a clear difference in that delayed SI showed 455 SPM while that of live was 410 SPM (p= 0.000). This might mean that interpreters in delayed mode spoke faster than those of live SI mode.
Table 15
SPM I/S ratio

(%)
SPM I/S ratio was the same case where delayed SI produced 1.62 times more syllables than the original English sentence and live SI produced 1.48 times syllables than the original (p = 0.001). This strongly shows that information processing in the delayed SI is more efficient than that of live SI. It was also found that both SPM I/S ratio of pairs of 73 sentences showed a high correlation (r=0.85, p<0.01). This means two groups of interpreters are taking a similar strategy in processing the same original sentences.
V. Conclusion
As was expected, the quality of delayed SI was much higher than that of live SI. The number of sentences interpreted and the accuracy of each sample proved this fact. Accuracy was the final result being affected by a chain of interpreter variables influencing one to another beginning with between-sentence pauses, EVS, in-sentence pauses, SP. Against this background, it was found that the between-sentence pause in live SI was greater than that of delayed SI. The fact that interpreters for live SI begin their utterance later than interpreters for delayed SI would mean that the former are working rigorously to grasp a minimum amount information to begin their interpretation under the severe multi-processing. As interpreters in live SI waited for a length of time, their EVS was inevitably lengthened as a result. Although conference interpreters are intuitively trying to reduce the length of EVS, interpreters in live SI mode had no choice but to leave long EVS due to their weaker processing capacity than delayed interpreters. Lengthened EVS made the Korean interpretation for the sentence become longer and negatively affected the processing of the following sentence.
This difficulty on the part of live SI was reaffirmed in the longer in-sentence pause in live SI. While interpreters in the delayed SI group were facilitated by a strong sense of anticipation since they already listened to the original sentences, the live group seemed to struggle hard to process incoming messages by distributing their limited capacity. This resulted in long in-sentence pauses and lowered SP in the live SI group. Interpreters are believed to take these strategies in order to reduce the part of extreme multi-processing, that is listening to the original sentence and uttering their own translation.
Under this situation, the SPM of delayed SI was higher than that of live SI. As with the SP, interpreters would reduce SPM if they experienced difficulty in processing any incoming message, high SPM means their processing is trouble-free. This was exactly the case when we examined the accuracy of two groups of SI.
When to finish processing one sentence and move on to the next sentence is another important decision interpreters must make during SI. For the reasons just mentioned, the length of Korean sentences in live SI was longer than in delayed SI. Since the SI should be stopped at the end of the speaker’s delivery of speech, sticking to one sentence for a long time will negatively affect the next sentence. This may be one of the reasons why live SI omitted more sentences than delayed SI. Delayed SI, on the other hand, illustrated that interpreters successfully processed incoming messages using the right strategy. This includes reducing between-sentence and in-sentence pauses, maintaining optimal EVS, and keeping the interpreted sentence at an appropriate length.
Since the speaker variables were the same for the interpreters in both groups of SI, the above mentioned differences are the result of interpreters’ information processing strategy. As was mentioned repeatedly, this difference is attributable to the fact that interpreters in delayed SI mode had a chance to listen to the whole speech in advance and they knew where the speeches would go. Besides the direction of the speech, interpreters in delay mode seem to spend shorter time in finding Korean expressions than the live SI group. This is in line with the study by Lambert (2004) who examined performance rates in sight translation, sight interpretation and simultaneous interpretation and found that additional rehearsal in which interpreters had a chance to read the speech from beginning to end enhanced interpreters’ performance.
One of the reasons behind the low quality of live SI would be the extreme multi-processing, especially processing more than two different sentences at the same time. Lambert (1992) succinctly explained as follows.
From the cognitive psychological point of view, simultaneous interpretation is a complex human information processing activity composed of a series of independent skills. The interpreter receives and attends to part of a sentence, referred to as a prepositional phase, a chunk, or a meaning unit. S/he begins translating and conveying meaning unit 1. At the same time, meaning unit 2 arrives aurally while the interpreter is still involved with the vocalization of meaning unit 1.
Since interpreters in live SI couldn’t finish unit 1 in time, partly due to long EVS, unit 2 or even unit 3 will arrive aurally. Part of the responsibility for this extreme multi-processing would the poor time management by the interpreters in live SI. Interpreters in the live SI group, however, should not be blamed wrongfully for this because they would have had good time management thus avoiding extreme multi-processing if they could have had the chance to listen to the original speech.
The sharp contrast between two modes of SI clearly demonstrates what strategy interpreters should take and how to make preparation to ensure quality SI. Although we cannot expect to have scripts in advance all the time, in some cases, however, a full text is given to interpreters in advance and they could have preparation time to read the whole text. Although speakers frequently stray from the script when they actually deliver speeches and this requires extra processing capacity on the part of interpreters, knowing where the speaker is going is very important for an interpreter in SI modes. Therefore, it would be recommendable that interpreters should try to get the scripts in advance and read them if possible. If not, interpreters, at least, should try to acquire the most detailed outline possible.
It would also be advisable to train interpreters to understand the nature of SI including the importance of prior knowledge and anticipation. As Chiaro and Nocella (2004) argued “both the complexity and the interaction of the various factors involved in the course of interpreting are not easy to manage,” and “it is human beings themselves who are responsible for the quality of the process in question.” They should remember that SI is a process of continuous crisis management and optimal distribution of limited processing capacity to each module is key to ensuring quality SI. To be more specific, interpreters should be advised not to allocate too much time on one sentence and they should understand that if they do, the quality of the next incoming sentence may be damaged or completely omitted. This might include the strategy not to spend more time than allowed to find fancier equivalents. When interpreters understand these points and acquire the strategy to realize them, their performance in the real world of SI will be improved.
Parties annexes
Biography
Taehyung Lee
Prof. Lee graduated from the GSIT at Hankuk University of Foreign Studies. He has written some 20 articles on interpretation studies, three of these for META. He currently teaches interpretation to undergraduate students at Hanyang University where he established the program.
Note
-
[*]
This work was supported by a research grant from Hanyang University, Ansan, Korea, made in the program year of 2004.
References
- Barik, H. C. (1973): “Simultaneous Interpretation: Temporal and Quantitative Data”, Language and Speech 16-3, pp. 237-270.
- Call, M. E. (1985): “Auditory Short-term Memory, Listening Comprehension, and the Input Hypothesis”, TESOL Quarterly 19-4, pp. 765-781.
- Garman, M. (1990): Psycholinguistics, Cambridge, Cambridge University Press.
- Chiaro, D and G. Nocella (2004): “Interpreters’ Perception of Linguistic and Non-linguistic Factors Affecting Quality: A Survey through the World Wide Web”, Meta 49-2. pp. 278-293.
- Gile, D. (1995): Basic Concepts and Models for Interpreter and Translator Training, Amsterdam, John Benjamins Publishing.
- ——— (2000): “Issues in Interdisciplinary Research into Conference Interpreting”, In B. E. Dimitrova and K. Hyltenstam (Eds), Language Processing and Simultaneous Interpreting, Amsterdam, John Benjamins Publishing.
- ——— (2001): “Selecting a Topic for Ph.D. Research in Interpreting”, In D. Gile (Eds), Getting Started in Interpreting Research, Amsterdam, John Benjamins Publishing.
- Griffiths, R. (1990): “Speech Rate and NNS Comprehension: A Preliminary Study in Time-benefit Analysis”, Language Learning 40-3, pp. 311-336.
- Jones, R. (1998): Conference Interpreting Explained, St. Jerome Publishing.
- Lambert, S., Daro, V. and F. Fabbro (1995): “Focalized Attention on Input vs. Output During Simultaneous Interpretation: Possibly a Waste of Effort!”, Meta 40-1, pp. 39-46.
- Lambert, S. (2004): “Shared Attention During Sight Translation, Sight Interpretation and Simultaneous Interpretation”, Meta 49-2, pp. 294-306.
- ——— (1992): “Shadowing”, Meta 37-2, pp. 263-273.
- Lee, T. (2004): “Analysis of Paired Korean Simultaneous Interpretation for a Speech Given in English”, FORUM 2-2, pp. 293-313.
- ——— (2002): “Ear Voice Span in English into Korean Simultaneous Interpretation”, Meta 47-4, pp. 596-606.
- MacWhinney, B. (1997): “Simultaneous Interpretation and the Competition Model”, In J.H. Danks, G. M. Shreve, G.M. Fountain and M.K. McBeath (Eds.), Cognitive Processes in Translation and Interpreting, London, Sage Publications.
- Pöchhacker, F. (2004): Introducing Interpreting Studies, Routledge, London
- Sawer, D. B. (2004): Fundamental Aspects of Interpreter Education, Amsterdam, John Benjamins Publishing.
- Weber, W. K. (1990): “The Importance of Sight translation in an Interpreter Training Program”, In Bowen, D. M. (Eds.), Interpreting-Yesterday, Today, and Tomorrow: American Translators Association Scholarly Monograph Series 4, New York, State University of New York at Binghamton.
- Weller, G. (1991): “The Influence of Comprehension Input on Simultaneous Interpreter's Output”, Proceedings of the 12th World Congress of FIT, Amsterdam, John Benjamins Publishing.
 10.7202/003384ar
10.7202/003384arListe des tableaux
Table 1
Correlations between S syllable and I variables
* p<0.05
** p<0.01
Table 2
Correlations between ST and I variables
* p<0.05
** p<0.01
Table 3
Correlations between S in-sentence and I variables
* p<0.05
** p<0.01
Table 4
Correlations between SSPM and I variables
* p<0.05
** p<0.01
Table 5
Accuracy
(%)
Table 6
Interpreters’ between-sentence pause
(%)
Table 7
Interpreters’ in-sentence pause
(%)
Table 8
EVS
(sec)
Table 9
EVS/sentence ratio
(%)
Table 10
Speech proportion
(%)
Table 11
Sentence level syllable I/S ratio
(%)
Table 12
Sample level syllable I/S ratio
(%)
Table 13
Sentence level IT I/S ratio
(%)
Table 14
SPM
(words per minute)
Table 15
SPM I/S ratio
(%)