Résumés
Résumé
L’estimation locale des pluies extrêmes et de leur période de retour est souvent peu précise du fait de données peu nombreuses. Le regroupement de données d’une même région permet souvent d’améliorer la précision de cette estimation. Cet article propose une approche régionale pour l’estimation des pluies journalières de fréquence rare, pour le bassin hydrographique du Cheliff (nord-ouest de l´Algérie). La première étape consiste à définir et à valider les régions homogènes de la zone d’étude. Le test d'homogénéité est basé sur la statistique H, qui compare les rapports des L-moments calculés localement à chaque station à leur moyenne sur la région considérée. La deuxième étape consiste à identifier la distribution régionale et à estimer ses paramètres par analyse du diagramme des L-moments et/ou calcul de la statistique Zdist, qui compare les rapports des L-moments régionaux à ceux de la distribution candidate. La loi GEV (« General Extreme Value »), qui a été utilisée dans plusieurs études antérieures de régionalisation des précipitations extrêmes, a été identifiée comme distribution régionale adéquate. Les paramètres de la GEV ont été calculés à l’aide de la définition des L-CV, L-CS et L-CK régionaux. La troisième étape consiste à déterminer localement les quantiles de pluie associés aux différentes périodes de retour, par multiplication du L-coefficient de variation régionale L-CV par la moyenne des précipitations journalières maximales annuelles observées au site considéré. Les pluies calculées par cette méthode, qui peut être appliquée à toute station de la zone étudiée, peuvent être significativement différentes de celles calculées par ajustement local. Les valeurs de l’erreur quadratique moyenne entre les quantiles calculés par approche régionale ou locale sont égales à 10 % pour la pluie journalière maximale annuelle décennale, et à 35 % pour la pluie journalière maximale annuelle centennale. Cette erreur diminue quand la longueur de la série locale augmente, ce qui suggère que l’approche régionale consolide effectivement l’estimation des quantiles de pluie.
Mots-clés :
- période de retour,
- extrêmes,
- précipitations,
- régionalisation,
- L-Moments,
- bassin du Chéliff,
- Algérie
Abstract
Local extreme rainfall estimates are often inaccurate because of the short duration of the observed series. Regional aggregation of data can greatly improve these estimates. This article shows a regional approach for the estimation of daily rainfall frequency rare, in the Cheliff basin (northwestern Algeria). The first step consists of defining and validating the homogeneous regions of the study area. The homogeneity test is based on the H-statistic, which compares the ratios of L-moments calculated locally at each station to their average over the region. The second step is to identify the regional distribution and estimate its parameters by analyzing the diagram of the L-moments and/or calculation of the Z-statistic which compares the ratios of regional L-moments with those of the candidate distribution. GEV ("General Extreme Value"), which has been used in several studies of regionalization of extreme rainfall, has been identified as a suitable regional distribution. The parameters of the GEV were calculated using the definition of regional L-CV, L-CS and L-CK. The third step is to determine locally the quantiles of rain associated with different return periods by multiplying the regional L-coefficient of variation L-CV by the mean annual maximum daily rainfall observed at the considered site. Rainfalls calculated by this method, which can be applied to any station in the study area, are significantly higher than those calculated by local fit. The values of the mean square error (REQM) between quantiles derived from regional or local methods are 10% for the decennial annual maximum daily rainfall, and 35% for the centennial annual maximum daily rainfall. This error decreases when the length of the local series increases, suggesting that the regional method leads indeed to more reliable assessments of the rain quantiles.
Keywords:
- return period,
- extreme,
- precipitation,
- regionalization,
- L-Moments,
- Cheliff basin,
- Algeria
Corps de l’article
1. Introduction
De nombreuses applications hydrologiques s'appuient sur la connaissance des pluies extrêmes. Malheureusement, les données de pluie restent limitées à la fois dans le temps et dans l'espace, ce qui ne permet pas toujours d'obtenir des estimations fiables de ces extrêmes (OUARDA et al., 2008). La régionalisation est une possibilité pour pallier ce problème. La régionalisation consiste à regrouper les données des stations d'une région homogène (ou rendue homogène) pour estimer une fonction de distribution régionale de probabilité. L'échantillon étant plus riche, les estimateurs de cette distribution sont plus robustes que ceux obtenus par une distribution locale. Il a été montré que la distribution régionale menait, dans la plupart des cas, à de meilleurs résultats que la distribution locale, car elle tient compte d'une région en tant que tout (ANCTIL et al., 1998).
Plusieurs procédures de régionalisation des événements extrêmes ont été proposées. Les premiers travaux de régionalisation ont été menés par DALRYMPLE (1960), et reposent sur la distribution des valeurs extrêmes du type I (Gumbel) ajustée à l'aide de moments conventionnels (EV1/MC). Cette méthode, dite méthode de l’indice de crue (index flood) fait l’hypothèse de base que les données aux différents sites d’une région sont indépendantes et suivent la même distribution statistique à un facteur d’échelle près (DOMINGUEZ et al., 2005). Le coefficient de variation et le coefficient d’asymétrie sont alors constants à l’intérieur d’une région homogène. HOSKING (1990) a ensuite introduit les moments L pour l'ajustement des fonctions de distribution. Les moments L sont des combinaisons linéaires des moments conventionnels, ce qui leur confère une robustesse accrue et une plus grande insensibilité aux valeurs extrêmes (VOGEL et FENNESSEY, 1993). Les études de régionalisation peuvent faire appel à d'autres méthodes : interpolation spatiale par krigeage (MERZ et BLOSCHL, 2005), régressions multiples avec différents facteurs géographiques, notamment le relief (WOTLING et al., 2000). Les études les plus nombreuses s'appuient néanmoins sur les L-moments (e.g. ALLILA,1999; HOSKING et WALLIS, 1993; ONIBON et al., 2004).
L’objectif principal de la présente étude est la régionalisation des distributions des pluies extrêmes journalières, pour obtenir des quantiles fiables en des sites ayant peu ou aucune donnée, en utilisant la méthode des L-moments proposée par HOSKING et WALLIS (1997).
La région d'étude est le bassin versant de l’oued Cheliff qui couvre une superficie de 43 750 km2. La faible densité des stations pluviométriques et leur répartition, assez concentrée dans le nord du bassin, nous ont conduits à mettre en place une approche régionale pour déterminer les pluies journalières maximales. La mise en place de l'approche régionale doit permettre d'obtenir de meilleures estimations des pluies extrêmes pour des périodes de retour comprises entre 10 et 100 ans, voire plus.
Cet article est structuré en trois étapes. Il propose, dans un premier temps, une présentation du site d'étude et des données disponibles puis une description des différents régimes pluviométriques qui se trouvent dans le bassin. En second lieu, nous présentons la méthode de régionalisation choisie. On y décrit les tests d’homogénéité utilisés pour la détermination des régions homogènes, la détermination de la fonction de distribution des précipitations et le principe de l’estimation régionale des quantiles associés aux différentes périodes de retour. Finalement, les résultats de la méthode de régionalisation appliquée au bassin du Cheliff concluent l'article.
2. Site d’étude et données utilisés
Situé au nord-ouest de l’Algérie, le bassin du Chéliff présente une superficie de 43 750 km2.
De par ses 759 km de longueur, le Chéliff est le plus long oued du bassin, qui coule d’Est en Ouest depuis le barrage de Boughezoul jusqu’à la mer. Le bassin du Cheliff s’étend entre les longitudes 0° 7’ et 3° 31’ Est et les latitudes 33° 53’ et 36° 26’ Nord. Il est limité au Nord par les côtes de l'Algérois et de l'Oranais, à l’Est par les bassins de l’Isser, du Hodna, du Zahrez et des hauts plateaux Constantinois, à l’Ouest par les bassins de la Macta et des hauts plateaux Oranais et au Sud par l’Atlas saharien (Figure 1). Du point de vue du relief, le bassin comprend quatre régions naturelles diversifiées : les chaînes montagneuses du Dahra-Zaccar (chef-lieu de la wilaya de Chlef) (de 700 à 1 580 m d’altitude) au Nord et l’Ouarsenis au Sud (près de 2 000 m d’altitude), la vallée du Chéliff au centre et une région côtière.
Figure 1
Isohyètes interannuelles et localisation des stations pluviométriques dans le bassin du Chéliff, nord-ouest de l'Algérie.
Interannual isohyetes and location of rain gauges in the Cheliff basin, northwestern Algeria.

Le climat du Chéliff est caractérisé par des régimes pluviométriques irréguliers dans le temps et dans l'espace, des étés chauds et secs peu orageux et des hivers doux et humides et peut être appelé méditerranéen semi-aride (GOMER, 1994).
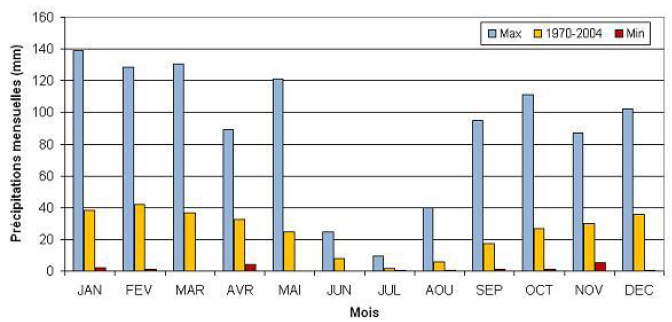
Les données utilisées dans le cadre de cette étude sont les précipitations journalières observées à 50 postes pluviométriques, pendant la période 1968 à 2004 (Tableau 1). Trente-trois stations ont fonctionné au moins 30 ans au cours de cette période, 47 stations au moins 20 ans. Nous avons conservé les années avec moins de 62 jours de pluie manquants par an, soit un taux de lacune maximal de 17 %. Le nombre moyen de lacunes sur l’ensemble des station-années conservées est sensiblement égal à 15 jours par an, soit 4 %. Les précipitations annuelles varient en moyenne de 154 à 600 mm, et sont plus élevées dans les zones montagneuses (Atlas tellien au Nord et Atlas saharien au Sud) que dans les zones de plaine (Figure 1). La variabilité saisonnière des pluies est très marquée, avec un minimum pendant l'été (juin, juillet, août, Figure 2).
Tableau 1
Caractéristiques des stations pluviométriques (période 1968-2004).
Characteristics of rainfall stations (period 1968-2004).

PMA : Pluie Moyenne Annuelle (mm).
Pjmax : Pluies journalières maximales de toutes les années de chaque station (mm).
Figure 2
Précipitations mensuelles moyenne, maximale et minimale à la station El Touaibia pour la période 1941- 2002.
Average maximum and minimum monthly precipitation at El Touaibia station for the period 1941-2002.
Les pluies journalières maximales s’échelonnent de 44 à 190 mm sur l’ensemble des stations, avec une valeur médiane égale à 81 mm. Les pluies journalières maximales se produisent majoritairement de février à septembre (plus de 10 % d’occurrence pour chaque mois de cette période, avec un maximum de 14 % au mois de mars), et sont plus rares pendant la période octobre-janvier (moins de 5 % d’occurrence pour chaque mois de cette période, avec un minimum de 1 % au mois de décembre, Tableau 2).
Tableau 2
Pourcentages d’occurrence des pluies maximales journalières.
Percentages of occurrence of the maximum daily rainfall.

La stationnarité des pluies sur la période considérée a été étudiée avec le test de Mann-Kendall avec bootstrap, appliqué aux séries de pluies annuelles. Ce test, destiné à éliminer l’autocorrélation entre les valeurs des séries chronologiques, est effectivement recommandé (Önöz et Bayazit, 2007). Le test conduit à accepter l’hypothèse de stationnarité avec une confiance de 95 %, pour 49 des 50 stations. Les données utilisées par la suite sont les pluies journalières maximales annuelles (1 valeur par an), et tous les traitements ont été faits relativement à ces données.
3. Méthode de régionalisation
3.1 La méthode des L-Moments
Les L-moments sont des combinaisons linéaires des moments de probabilité pondérés. Le fait d'utiliser ces combinaisons linéaires réduit la dépendance aux événements extrêmes. Pour normaliser la méthode, HOSKING (1990) propose d’utiliser la forme standardisée des L-moments. Ainsi, le L-coefficient de variation (noté L-CV), la L-asymétrie (notée L-CS ) et le L-aplatissement (noté L-CK) sont des formes standardisées des L-moments d’ordre 2, 3 et 4, estimées de la façon suivante (ONIBON et al., 2004) :
Une description détaillée des L-moments est donnée par HOSKING (1986; 1990).
3.2 Principes de la régionalisation
Le principe de la régionalisation consiste à caractériser la fonction de répartition associée à la variable aléatoire considérée, à partir d’informations locales recueillies sur une région homogène (ONIBON et al., 2004).
La mise en oeuvre de la régionalisation par les L-moments requiert trois étapes (HOSKING et WALLIS, 1993; 1997) : (i) identification des groupes de stations hydrologiquement homogènes, (ii) calcul des L-moments régionaux pour chaque groupe homogène et choix du type de loi régionale et (iii) estimation des quantiles locaux à partir de la distribution régionale et des caractéristiques de la pluie locale.
Ces étapes sont détaillées dans ce qui suit.
3.2.1 Constitution de régions homogènes
Pour valider l'homogénéité d'une région en matière de rapports de L-moments, nous avons utilisé le test d'homogénéité basé sur la statistique H proposé par HOSKING et WALLIS (1993).
L'objectif du test H est de vérifier que les pluies journalières maximales de différents sites peuvent être considérées comme étant issues d'une même distribution-mère.
Le principe du test H est de comparer la variance régionale observée des ratios des L-moments à la distribution de cette variance régionale sous l'hypothèse d'homogénéité de la région (hypothèse H0). Cette distribution de variance régionale est obtenue par une méthode « Monte Carlo » qui consiste en une série de simulations basées sur la génération de variables distribuées selon la loi GEV, choisie a priori pour représenter les précipitations extrêmes.
La fonction de distribution cumulée F de la loi GEV est donnée par JENKINSON (1955) :
k, α et ζ représentent respectivement les paramètres de forme, d'échelle et de position.
La statistique H est calculée par :
où V est la valeur observée de Vr (r = 1, 2 ou 3), soit la variance pondérée V1 du L-CV :
La somme pondérée V2 des distances de t et t3 de chaque station à leurs moyennes respectives :
La somme pondérée V3 des distances de t3 et t4 de chaque station à leurs moyennes respectives :
N désigne le nombre de postes d'observation, ni l'effectif de l'échantillon du poste i; t(i) t3(i) et t4(i) sont respectivement les L-CV, L-CS et L-CK du poste i, et ![]() leurs moyennes pondérées, soit :
leurs moyennes pondérées, soit :
µv et σv sont respectivement la moyenne et l'écart-type des Vr obtenus par simulation de Monte Carlo, dans une loi GEV dont les L-moments sont ![]() .
.
HOSKING et WALLIS (1993) montrent qu'une région peut être considérée comme étant homogène si H < 1, probablement hétérogène si 1 ≤ H < 2 et complètement hétérogène si H > 2.
En général, le test d'homogénéité est appliqué sur un découpage de stations en groupes supposés a priori homogènes. Ici, nous avons systématiquement testé toutes les combinaisons de stations, i.e. les combinaisons à p stations parmi les n stations possibles, en partant du plus grand nombre p = n, et en diminuant p d’une unité jusqu’à trouver un groupe homogène à p stations. Cette méthode est bien adaptée au cas d’une région probablement homogène, à condition d’enlever quelques stations posant problème pour des raisons diverses, liées davantage à des problèmes de données qu’à une réelle hétérogénéité physique. La méthode s’avère dans ce cas très efficace pour détecter ces quelques stations, et former le groupe homogène ayant le plus grand effectif. Elle s’est avérée notamment plus efficace que des méthodes classiques, consistant à chercher les stations discordantes, puis à tester l’hétérogénéité du groupe des stations non discordantes. Le cas échéant, cette méthode peut être combinée à une classification hiérarchique définissant plusieurs groupes au sens de la proximité des stations selon un caractère secondaire (par exemple, altitude ou pluie moyenne annuelle) lorsque la région n’est pas totalement homogène.
La statistique H a été calculée pour chaque combinaison de p stations parmi les n stations possibles par un programme R proposé par HOSKING (1997) (fonction regtst, voir en annexe 1), dans la bibliothèque lmomRFA, http://cran.r-project.org/web/packages/lmomRFA/lmomRFA.pdf. Les stations discordantes sont également détectées par ce programme.
3.2.2 Sélection d'une loi de distribution
Les L-moments de la distribution d'une région homogène sont identifiés aux moyennes pondérées des L-moments de chacun des postes d'observations, soit ![]() . On peut ensuite déterminer les paramètres de la loi régionale à partir des L-moments. Dans le cas d’une loi GEV, les paramètres sont liés aux L-moments par les relations :
. On peut ensuite déterminer les paramètres de la loi régionale à partir des L-moments. Dans le cas d’une loi GEV, les paramètres sont liés aux L-moments par les relations :
Le paramètre de forme k est calculé par la formule suivante :
Les paramètres d'échelle α et de position ζ sont déduits des équations :
où  représente la fonction Gamma.
représente la fonction Gamma.
Plusieurs méthodes peuvent être utilisées pour déterminer le type de la loi de distribution.
3.2.2.1 Le diagramme des L-Moments
Le choix de la loi peut être orienté par un diagramme des rapports des L-moments (HOSKING et WALLIS, 1997; VOGEL et al., 2009), en particulier le diagramme qui représente le L-coefficient d'aplatissement τ4 en fonction du L-coefficient d'asymétrie τ3 (MEYLAN et al., 2008). Les valeurs régionales moyennes des L-moments, estimés à partir des observations disponibles en chacun des sites de la région, peuvent être comparées aux L-moments théoriques de différentes lois de distribution.
3.2.2.2 Calcul de la statistique Zdist
BEN-ZVI et AZMON (1997) remarquent que le diagramme des L-moments permet de déterminer les distributions acceptables, mais pas nécessairement la distribution la plus adéquate. Des tests statistiques d'ajustement doivent être utilisés en complément au diagramme.
HOSKING et WALLIS (1997) ont développé le test de la statistique Z, dont l'objectif est de tester si un modèle fréquentiel théorique donné peut représenter le comportement statistique des pluies journalières maximales pour les différents sites d'une région homogène vis-à-vis de ces pluies.
Le test Zdist mesure l'écart sur les ratios des L-coefficients d'aplatissement entre la valeur théorique de la loi choisie et la valeur moyenne obtenue sur la base des Nsim générations de « Monte Carlo ».
![]() ratio du L-moment d'ordre 4 calculé à partir des valeurs régionales des coefficients de variation et d'asymétrie
ratio du L-moment d'ordre 4 calculé à partir des valeurs régionales des coefficients de variation et d'asymétrie ![]() pour chaque distribution théorique candidate DIST.
pour chaque distribution théorique candidate DIST. ![]() est la moyenne empirique des Nsim coefficients d'aplatissement régionaux générés par la loi Kappa. β4 et σ4 sont respectivement le biais et l'écart-type simulé des coefficients d'aplatissement régionaux (HINGRAY et al., 2009). La statistique Zdist a été calculée à l’aide d’un programme R proposé par HOSKING (fonction regtst, voir en annexe 1) dans la bibliothèque lmomRFA, http://cran.r-project.org/web/packages/lmomRFA/lmomRFA.pdf.
est la moyenne empirique des Nsim coefficients d'aplatissement régionaux générés par la loi Kappa. β4 et σ4 sont respectivement le biais et l'écart-type simulé des coefficients d'aplatissement régionaux (HINGRAY et al., 2009). La statistique Zdist a été calculée à l’aide d’un programme R proposé par HOSKING (fonction regtst, voir en annexe 1) dans la bibliothèque lmomRFA, http://cran.r-project.org/web/packages/lmomRFA/lmomRFA.pdf.
3.2.3 Quantiles estimés pour différentes périodes de retour
Pour calculer pour chaque station les quantiles de période de retour T, nous excluons la station cible et calculons le L-CV et la L-CS régionaux. La distribution locale est estimée à partir de la distribution régionale, en déterminant d'abord le L-écart-type par multiplication du L-coefficient de variation régionale L-CV par la moyenne des précipitations journalières maximales annuelles observées au site. Ensuite on calcule les paramètres de la loi GEV en utilisant la L-CS régionale, le L-écart-type estimé à l'étape précédente et la moyenne de précipitations journalières maximales annuelles au site considéré à partir des équations 8 à 10). Enfin, on calcule les quantiles correspondant aux périodes de retour spécifiées en utilisant l'inverse de la fonction de distribution donnée par la formule suivante, dans le cas d’une loi GEV :
Les quantiles de cette distribution locale pourront être comparés à ceux obtenus par ajustement direct de la loi de distribution sur l'échantillon local. Les paramètres de la loi régionale ont été calculés par un programme R proposé par HOSKING (1997) (fonction regfit, voir annexe 1), dans la bibliothèque lmomRFA, http://cran.r-project.org/web/packages/lmomRFA/lmomRFA.pdf.
La fiabilité de la méthode régionale d’estimation des quantiles peut être évaluée en calculant par exemple la racine carrée de l’erreur quadratique moyenne (REQM) relative ainsi que le biais relatif lié à l’estimation régionale. Pour chaque station de la région homogène, nous calculons la racine de la moyenne des valeurs obtenues sur trois périodes de retour, à savoir 10 ans, 100 ans et 1 000 ans :
où ![]() et
et ![]() représentent les quantiles de période de retour T estimés pour le site i respectivement à partir des paramètres régionaux et locaux de la loi de distribution et N le nombre de stations.
représentent les quantiles de période de retour T estimés pour le site i respectivement à partir des paramètres régionaux et locaux de la loi de distribution et N le nombre de stations.
4. Applications et résultats
4.1 Groupes homogènes
La méthode de calcul de la statistique H a été appliquée systématiquement à toutes les combinaisons de p (= 50, 49, 48, 47, 46 stations) parmi les 50 stations disponibles dans l’ensemble de la région. Pour chaque valeur de p, on a calculé le Hmin(p) correspondant à la valeur minimale de H pour toutes les combinaisons de p stations. On obtient finalement un groupe homogène avec 46 stations, après avoir éliminé quatre stations, Nos 15, 7, 35, 39 (Tableau 3).
Tableau 3
Résultats des valeurs minimales de H pour toutes les combinaisons de p stations.
Results of the minimum values of H for all combinations of p stations.

Les résultats présentés ont été obtenus avec H(L-CV), des résultats similaires ont été obtenus avec H(L-CS) et H(L-CK).
4.2 Sélection de la loi régionale
Les résultats du diagramme des L-moments (Figure 3) et le test Zdist (Tableau 4) valident l’hypothèse selon laquelle la loi GEV peut représenter de manière adéquate la distribution des pluies journalières maximales annuelles de la région homogène.
Figure 3
Relation entre la L-CS et le L-CK des précipitations journalieres maximales annuelles (Pearson, LogN, GEV, GPA représentent respectivement les lois Pearson, Lognormale, GEV et Pareto généralisée; Ens. est la désignation du point matérialisant les caractéristiques obtenues à partir des 46 stations).
Relationship between L-CS and L-CK of annual maximum daily rainfall (Pearson, LogN, GEV, GPA represent respectively Pearson, Lognormal, GEV and generalized Pareto distributions; Ens. is the designation of the point materializing the characteristics obtained from 46 stations).
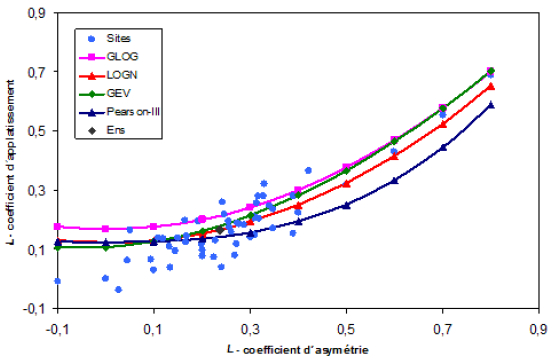
Tableau 4
Caractéristiques statistiques du groupe homogène.
Statistical characteristics of the homogeneous group.

4.3 Comparaison des quantiles locaux estimés par ajustement régional ou par ajustement local
Pour chaque site de la région homogène, on procède aux calculs des précipitations extrêmes correspondant aux quantiles de périodes de retour à partir des paramètres de la loi GEV régionale (cf. paragraphe 3.2.3).
Les quantiles locaux ont également été déterminés par ajustement local de la loi GEV. Ces quantiles ont ensuite été comparés à ceux calculés précédemment par ajustement régional (Figure 4).
Figure 4
Distributions des quantiles estimés: (a) station Pontéba; b) station Sougueur; c) station El Asnam.
At-site and regional cumulative distribution functions (CDFs) for (a) Pontéba station; (b) Sougueur station and (c) El Asnam station.

Comme le montre la figure 4, les écarts entre les quantiles estimés à partir de l'ajustement local ou régional de la GEV ont tendance à augmenter avec la période de retour. L’estimation des quantiles par ajustement régional donne des valeurs supérieures à celles estimées par ajustement local, dans le cas de la station Sougueur (Figure 4b), ou inférieures dans le cas de la station Ponteba (Figure 4a). Par ailleurs, il arrive que l'estimation régionale donne des valeurs similaires à l'estimation locale. C'est le cas, par exemple, de la station El Asnam (Figure 4c). Ces différences peuvent être imputables aux erreurs liées à l’échantillonnage, du fait de la durée relativement courte des périodes d’observation aux différentes stations.
Pour l’ensemble des 46 stations, l’écart REQM entre les quantiles obtenus par approche régionale ou locale est de 10 % pour la période de retour décennale, et de 35 % pour la période de retour centennale (Figure 5).
Figure 5
Comparaison des quantiles des pluies journalières maximales obtenues par ajustement local et par ajustement régional : a) T = 10 ans; b) T = 100 ans.
Comparison of the quantiles of the daily maximal rainfalls derived from local fitting and regional fitting: a) T = 10 years; b) T = 100 years.

Enfin, pour évaluer la pertinence du modèle régional, nous avons artificiellement retiré des valeurs de l’échantillon initial des pluies journalières maximales annuelles, et recalculé pour chaque nouvel échantillon les quantiles obtenus selon l’approche régionale ou selon l’approche locale : ces quantiles ont ensuite été comparés aux quantiles initiaux, obtenus avec l’échantillon complet. Les valeurs à supprimer ont été tirées aléatoirement, par simulation de type Monte Carlo; finalement, on travaille sur des échantillons comprenant entre 30 années d’observations par station (échantillon initial) et six années d’observations par station, pour un ensemble de 46 stations (Figure 6). On peut noter que l’erreur augmente en fonction de la longueur des séries d’observations, et que cette augmentation est relativement beaucoup plus importante pour l’approche locale. Le fait que l’approche régionale stabilise la variabilité de l’estimation des quantiles est naturellement lié au fait que l’échantillon régional est toujours plus important que l’échantillon local. Ceci peut apparaître comme un avantage important de l’approche régionale.
Figure 6
Variation de l'erreur quadratique moyenne locale et régionale en fonction de la longueur de la série pour les périodes de retour décennale et centennale.
Local and regional variation of the relative root mean square error as a function of the length of the series for decennial and centennial return periods.

5. Conclusion
Cette étude a porté sur la régionalisation des distributions des pluies extrêmes journalières, pour obtenir des quantiles fiables en des sites ayant peu ou aucune donnée. La méthode de régionalisation est basée sur les L-moments, et s’appuie sur trois étapes successives : 1) délimitation des régions homogènes par le test d’homogénéité basé sur la statistique H; 2) identification de la loi régionale basée sur le calcul de la statistique Zdist; 3) comparaison des quantiles issus de l’approche régionale et de l’approche locale. Un algorithme original a montré que la région pouvait être considérée comme globalement homogène, si on considère un ensemble de 46 stations sur 50. La distribution GEV a été sélectionnée comme distribution régionale, et ses paramètres ont été estimés à partir des L-moments régionaux. Les REQM calculés entre quantiles régionaux et quantiles locaux sont de 10 et de 35 % respectivement pour des périodes de retour décennales et centennales. Les écarts entre les quantiles s’expliquent en partie par les erreurs d’échantillonnage liées à la durée relativement courte des observations locales; l’approche régionale, en utilisant des échantillons plus fournis, permet de réduire ces erreurs d’échantillonnage.
La méthodologie est généralisable à d'autres bassins algériens, et peut également s'appliquer à d'autres variables hydro-météorologiques que les précipitations. Ultérieurement, une comparaison de cette méthode L-moments est prévue avec d’autres méthodes de type « flood-index », consistant à regrouper toutes les données indépendantes dans un échantillon unique, après normalisation par un facteur d’échelle.
Parties annexes
Annexe
Annexe : algorithme utilisé pour le calcul de H et Zdist
# boucle de calcul H par combinaison de stations
# pjmax.txt est la matrice des pluies maximales journalières, 1 colonne par station, 1 ligne par année, séparateur tabulation
library(lmomRFA)
pjmax = read.table("C:/pjmax.txt", sep = "\t")
x=1:50
# on definit la fonction qui renvoie la valeur H
myfun = function(indice, pluie){
testH <- regtst(regsamlmu(pluie[,indice]))
testH$H[1]
}
# on boucle sur le nombre elements de la combinaison
pv = 50:46
Halist = vector(length=length(pv), mode="list")
for(p in 1:length(pv)) {
a = combn(x,pv[p])
Halist[[p]] = apply(a,2,myfun,pjmax.red)
b=sapply(Halist,min)[p]
sapply(Halist[[p]],which.min)
print(b)
print(a[,which.min(Halist[[p]])])
Remerciements
Ce travail a été réalisé avec le soutien financier d’Hydrosciences Montpellier et de l´Institut de Recherche pour le Développement (IRD, France). Les auteurs remercient Dr Mathieu Le Coz pour ses commentaires et suggestions qui ont valeureusement contribué à l’amélioration de cette étude, et Dr Julie Carreau pour ses conseils en matière de tests statistiques et de programmation en langage R.
Bibliographie
- ALILA Y. (1999). A hierarchical approach for the regionalization of precipitation annual maxima in Canada. J. Geophys. Res., 104, 31645-31655.
- ANCTIL F., N. MARTEL et V.D. HOANG (1998). Analyse régionale des crues journalières de la province du Québec. Rev. Can. Gen. Civ., 25, 360-369.
- BEN-ZVI A. et B. AZMON (1997). Joint use of L-moment diagram and goodness-of-fit test: a case study of diverse series. J. Hydrol., 198, 245-259.
- DALRYMPLE T. (1960). Flood frequency analysis. US Geol. Survey, Water Supply Paper, 1543-A.
- DOMINGUEZ R., C. BOUVIER, L. NEPPEL et H. LUBES (2005). Approche régionale pour l’estimation des distributions ponctuelles des pluies journalières dans le Languedoc-Roussillon (France). Hydrol. Sci. J., 50, 17-29.
- GOMER D. (1994). Écoulement et érosion dans des petits bassins versants à sols marneux sous climat semi-aride méditerranéen. Bassin de la Mina. Thèse de Doctorat, Univ. Karlsruhe, Allemagne, 137 p.
- HINGRAY B., C. PICOUET et A. MUSY (2009). Hydrologie 2, une science pour l´ingénieur. PPUR (Presses polytechniques et universitaires romandes), Lausanne, Suisse, 600 p.
- HOSKING J.R.M. (1986). The theory of probability weighted moments. Research report RC12210, IBM Research Division, Yorktown Heights, New York, NY, USA, 160 p.
- HOSKING J.R.M. (1990). L-Moments: Analysis and estimation of distributions using linear combinations of ordered statistics. J. Res. Stat. Soc., B52,105-124.
- HOSKING J.R.M. et J.R. WALLIS (1993). Some statistics useful in regional frequency analysis. Water Resour. Res., 29, 271-281.
- HOSKING J.R.M. et J.R. WALLIS (1997). Regional frequency analysis: An approach based on L-moments. Cambridge University Press, Cambridge, UK, 224 p.
- JENKINSON A.F. (1955). The frequency distribution of the annual maximum (or minimum) values of meteorological event. Quart. J. Roy. Met. Soc., 81, 158-171.
- MERZ R. et G. BLÖSCHL (2005). Flood frequency regionalisation – spatial proximity vs. catchment attributes. J. Hydrol., 302, 283-306.
- MEYLAN P., A.C. FAVRE et A. MUSY (2008). Hydrologie fréquentielle une science prédictive. PPUR (Presses polytechniques et universitaires romandes), Lausanne, Suisse, 173 p.
- ONIBON H., T. OUARDA, M. BARBET, A. ST-HILAIRE, B. BOBÉE et P. BRUNEAU (2004). Analyse fréquentielle régionale des précipitations journalières maximales annuelles au Québec. Can. Hydrol. Sci. J., 49, 717-735.
- ÖNÖZ B. et M. BAYAZIT (2012). Block bootstrap for Mann–Kendall trend test of serially dependent data. Hydrol. Proc., 26, 3552-3560.
- OUARDA T., A. ST-HILAIRE et B. BOBÉE (2008). Synthèse des développements récents en analyse régionale des extrêmes hydrologiques. Rev. Sci. Eau / J. Water Sci., 21, 219-232.
- VOGEL R.M. et N.M. FENNESSEY (1993). L-Moment diagrams should replace product moment diagrams. Water Resour. Res., 29, 1745-1752.
- VOGEL R.M., J.R.M. HOSKING, C.S. ELPHICK, D.L. ROBERTS et J.M. REED (2009). Goodness-of-fit of probability distributions for sightings as species approach extinction, Bull. Math. Biol., 71, 701-719.
- WOTLING G., C. BOUVIER, J. DANLOUX et J.M. FRITSCH (2000). Regionalization of extreme precipitation distribution using the principal components of the topographical environment. J. Hydrol., 233, 86-101.
Liste des figures
Figure 1
Isohyètes interannuelles et localisation des stations pluviométriques dans le bassin du Chéliff, nord-ouest de l'Algérie.
Interannual isohyetes and location of rain gauges in the Cheliff basin, northwestern Algeria.
Figure 2
Précipitations mensuelles moyenne, maximale et minimale à la station El Touaibia pour la période 1941- 2002.
Average maximum and minimum monthly precipitation at El Touaibia station for the period 1941-2002.
Figure 3
Relation entre la L-CS et le L-CK des précipitations journalieres maximales annuelles (Pearson, LogN, GEV, GPA représentent respectivement les lois Pearson, Lognormale, GEV et Pareto généralisée; Ens. est la désignation du point matérialisant les caractéristiques obtenues à partir des 46 stations).
Relationship between L-CS and L-CK of annual maximum daily rainfall (Pearson, LogN, GEV, GPA represent respectively Pearson, Lognormal, GEV and generalized Pareto distributions; Ens. is the designation of the point materializing the characteristics obtained from 46 stations).
Figure 4
Distributions des quantiles estimés: (a) station Pontéba; b) station Sougueur; c) station El Asnam.
At-site and regional cumulative distribution functions (CDFs) for (a) Pontéba station; (b) Sougueur station and (c) El Asnam station.
Figure 5
Comparaison des quantiles des pluies journalières maximales obtenues par ajustement local et par ajustement régional : a) T = 10 ans; b) T = 100 ans.
Comparison of the quantiles of the daily maximal rainfalls derived from local fitting and regional fitting: a) T = 10 years; b) T = 100 years.
Figure 6
Variation de l'erreur quadratique moyenne locale et régionale en fonction de la longueur de la série pour les périodes de retour décennale et centennale.
Local and regional variation of the relative root mean square error as a function of the length of the series for decennial and centennial return periods.
Liste des tableaux
Tableau 1
Caractéristiques des stations pluviométriques (période 1968-2004).
Characteristics of rainfall stations (period 1968-2004).
PMA : Pluie Moyenne Annuelle (mm).
Pjmax : Pluies journalières maximales de toutes les années de chaque station (mm).
Tableau 2
Pourcentages d’occurrence des pluies maximales journalières.
Percentages of occurrence of the maximum daily rainfall.
Tableau 3
Résultats des valeurs minimales de H pour toutes les combinaisons de p stations.
Results of the minimum values of H for all combinations of p stations.
Tableau 4
Caractéristiques statistiques du groupe homogène.
Statistical characteristics of the homogeneous group.